A Comprehensive Overhaul of Feature Distillation
原文地址:A Comprehensive Overhaul of Feature Distillation
官方实现:clovaai/overhaul-distillation
复现地址:ZJCV/overhaul
摘要
We investigate the design aspects of feature distillation methods achieving network compression and propose a novel feature distillation method in which the distillation loss is designed to make a synergy among various aspects: teacher transform, student transform, distillation feature position and distance function. Our proposed distillation loss includes a feature transform with a newly designed margin ReLU, a new distillation feature position, and a partial L2 distance function to skip redundant information giving adverse effects to the compression of student. In ImageNet, our proposed method achieves 21.65% of top-1 error with ResNet50, which outperforms the performance of the teacher network, ResNet152. Our proposed method is evaluated on various tasks such as image classification, object detection and semantic segmentation and achieves a significant performance improvement in all tasks. The code is available at this https URL
我们调查了实现网络压缩的特征提取方法的各种设计,并提出了一种新的特征提取方法,其中蒸馏损失函数被设计为教师变换、学生变换、蒸馏特征位置以及距离函数之间的协同。我们提出的蒸馏损失包括一个新设计的margin ReLU的特征变换、一个新的蒸馏特征位置和一个partial L2距离函数(跳过对学生压缩产生不利影响的冗余信息)。在ImageNet中,我们提出的方法使用ResNet50实现了21.65%的top-1错误,其性能优于教师网络ResNet152。我们提出的方法在图像分类、目标检测和语义分割等任务上进行了评估,并在所有任务中取得了显著的性能改进。代码开源在https://github.com/clovaai/overhaul-distillation
思路
- 首先描述特征蒸馏损失函数的泛化公式;
- 然后分析了损失函数中涉及的计算类别。
泛化损失
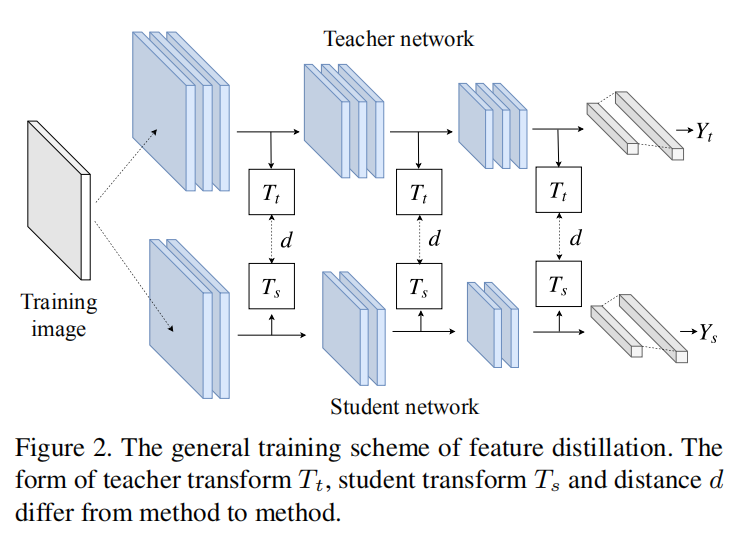
\[ L_{distill}=d(T_{t}(F_{t}), T_{s}(F_{s})) \]
- \(F_{t}\)表示教师模型的特征;
- \(F_{s}\)表示学生模型的特征;
- \(T_{t}\)表示教师模型的特征转换函数,用于匹配学生模型输出特征大小;
- \(T_{s}\)表示学生模型的特征转换函数,用于匹配教师模型输出特征大小;
- \(d\)表示距离函数,用于计算教师模型和学生之间的特征相似度。
计算类别
特征蒸馏损失的计算设计到4个类别,下图所示:

teacher transform:对教师网络的特征进行转换,以匹配学生网络特征;- 在之前的特征蒸馏算法中,通常会对教师网络特征进行转换,这会损失一部分信息;
- 论文提出一个新的转换函数
margin ReLU,不对正值特征(论文认为是有益的)进行转换,而对负值特征进行抑制;
student transform:类似于teacher transform,对学生网络特征进行转换以匹配蒸馏训练;- 论文采用了之前论文实现的一种方法,使用\(1\times 1\)卷积层对学生特征进行转换,扩大其特征图大小以匹配教师特征;
Distillation feature position:采集网络中哪个位置的特征进行蒸馏训练;- 之前的实现并没有考虑到
ReLU的作用。经过ReLU计算的特征,会留下正值特征(作者认为是有益的)而过滤掉所有负值特征; - 论文将采样特征位置放置在
ReLU函数之前,这样得到的蒸馏特征保留了所有信息,在后续实验中也发现是有用的;
- 之前的实现并没有考虑到
- 距离函数:计算教师网络特征和学生网络特征之间的相似度;
- 之前的论文大多采用
L1或者L2距离函数; - 本文选择了不一样的蒸馏特征位置,所以采集的教师网络特征中包含了负值特征(作者认为是有害的);
- 为了过滤这些特征,设计了一个新的
L2距离函数:partial L2。
- 之前的论文大多采用
蒸馏位置
ReLU函数能够过滤所有负值特征,为网络带来非线性特征。不过在之前的特征蒸馏算法中并没有考虑到这一点,论文设计了新的蒸馏特征位置,其位于ReLU之前,这样能够为特征蒸馏带来更多的信息,如下图所示
在上图中,作者列举了多个基本单元,其核心思想就是都是从该Block(无论是简单卷积-BN块,还是残差块/前激活残差块/金字塔残差块)结束后遇到的第一个ReLU(这个ReLU可能是block的最后一步,或者是下一个block的操作)之前获取蒸馏特征图。
转换函数
Teacher Transform
设计教师转换函数的目的是为了让教师网络特征图更好的反映特征信息,也就是如果教师网络的特征值是正的,那么学生网络要尽可能的让这些神经元大小为正值;如果教师网络神经元的大小是负的,那么学生网络相应的神经元的特征值尽可能小于0(也就是没必要和教师网络神经元一样有相同大小的负值)。论文由此设计了教师转换函数如下:
\[ \sigma _{m}(x)=\max(x, m) \]
其中\(m\)是一个小于\(0\)的边界值,称上述损失函数为Margin ReLU。论文比较了新设计的Margin ReLU和之前论文的差别,从下图可知,Margin ReLU更能够反应教师网络特征值的变化
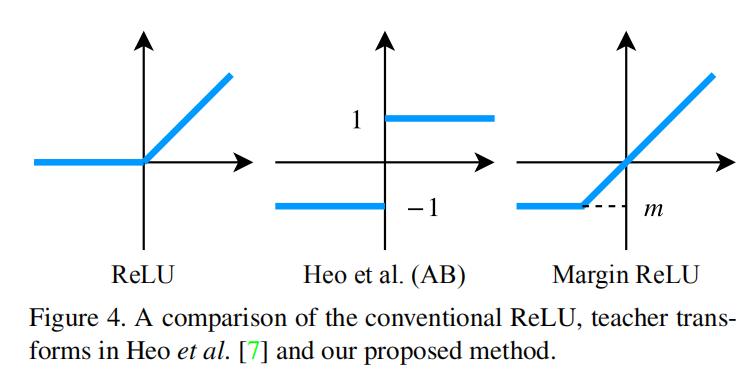
在论文设计中,\(m\)值计算为教师网络负响应神经元的逐通道期望,也就是说,给定通道数为\(C\),教师网络特征图\(F_{t}\)的第\(i\)个元素的边界值\(m_{C}\)的计算公式如下:
\[ m_{C} = E[F_{t}^{i} | F_{t}^{i} < 0, i\in C] \]
Student Transform
学生网络特征图的大小通常小于等于教师网络,所以参考了之前的论文设计,使用一个\(1\times 1\)卷积层外加一个批量归一化层作为转换函数。
损失函数
距离函数
针对蒸馏训练,论文设计的距离函数\(d\)如下所示,称之为partial L2距离函数\(d_{p}\)
\[ d_{p}(T, S) = \sum_{i}^{W HC} \left\{\begin{matrix} 0 & if S_{i}\leq T_{i} < 0\\ (T_{i} - S_{i})^{2} & otherwise \end{matrix}\right. \]
- \(T\in R^{W\times H\times C}\):表示教师网络特征表示;
- \(S\in R^{W\times H\times C}\):表示学生网络特征表示;
- \(T_{i}, S_{i}\)表示第\(i\)个组件的特征表示;
设计思路:
- 对于教师网络的正响应神经元,需要学生网络相应位置尽可能的模拟;
- 对于教师网络的负响应神经元,需要学生网络相应位置小于
0即可。
蒸馏损失
论文设计的蒸馏训练的损失函数结合了教师特征转换函数、学生特征转换函数和距离函数,整体公式如下:
\[ L_{distill} = d_{p}(\sigma_{m_{C}}(F_{t}), r(F_{s})) \]
整体损失
论文设计的蒸馏算法是端到端的一阶段训练,所以结合正常训练的交叉熵损失函数和蒸馏损失函数进行训练,公式如下:
\[ loss = L_{task} + \alpha L_{distill} \]
在不同任务中,论文设计了不同的蒸馏位置数目。比如在CIFAR中,提取模型的3个目标层进行蒸馏训练;在ImageNet中,提取模型的4个目标层进行训练。
实验
论文在多个不同领域进行了实验,OFD算法提供了一致性的增强。
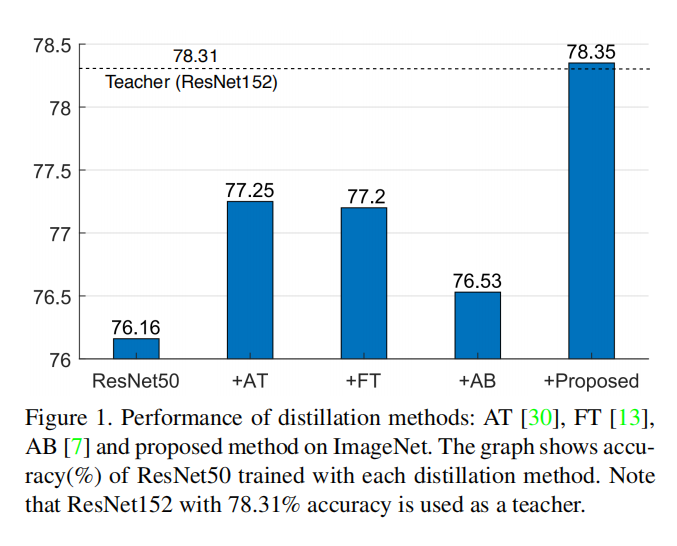
CIFAR100

- 从上述实验来看,
OFD算法提供了最强的增益; - 为了复现其他论文的最好效果,一些算法结合了
KD进行训练; OFD算法并没有结合KD算法,因为其效果反而变差了。
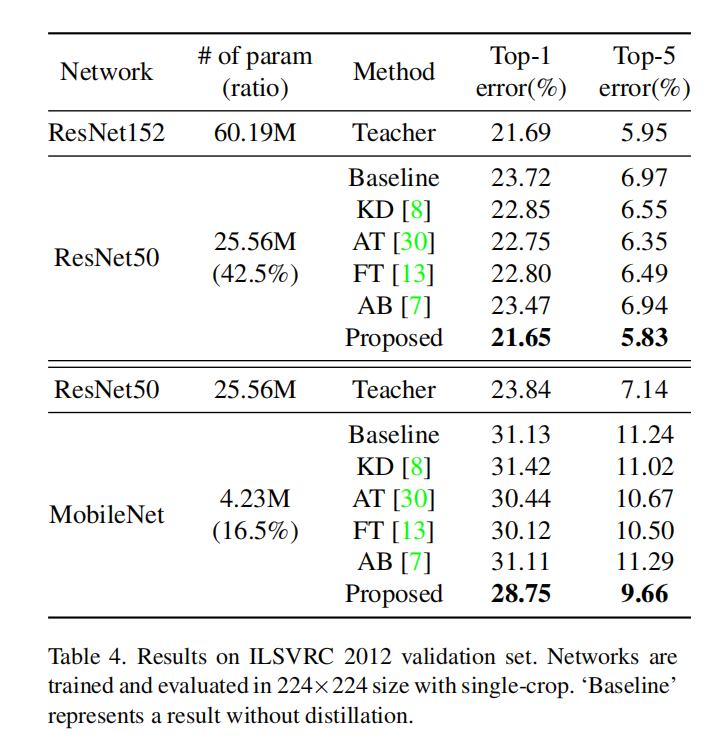
ImageNet
目标检测
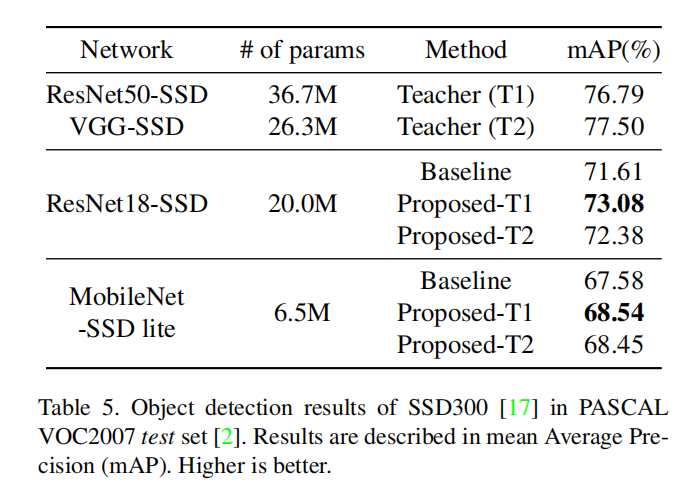
语义分割
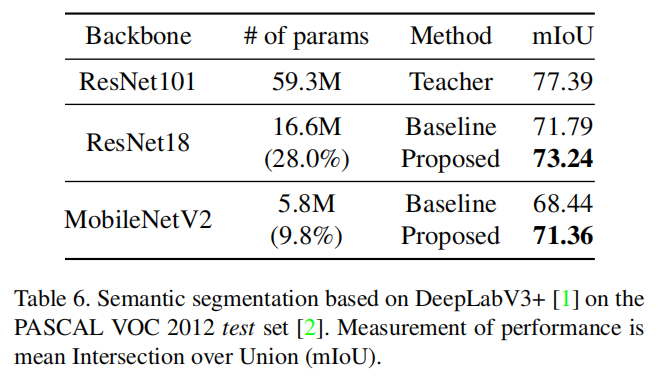
分析
相似度
论文想要找出一种有效的方式来衡量OFD算法的性能提高。计算了不同蒸馏算法得到的教师-学生网络输出向量的K-L散度以及相对于真值标签的交叉熵的相似度,如下表所示:
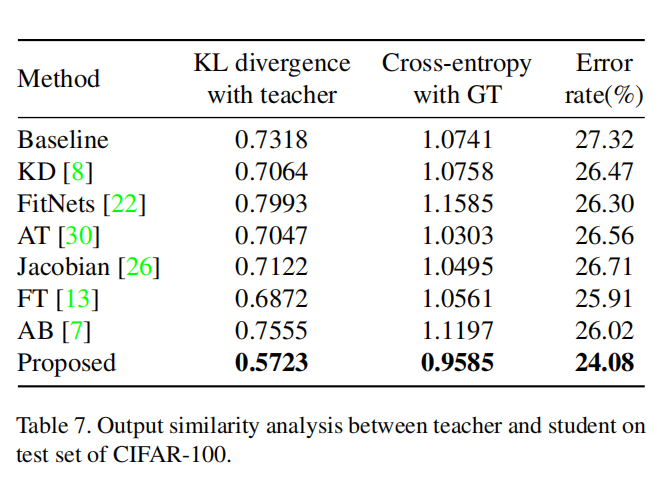
在上表中,初始化蒸馏(initial distillation)算法(FitNets/AB,二阶段训练,先蒸馏训练得到初始化参数,然后进行正常训练)同时提高了KL散度和交叉熵;其他持续蒸馏(continuous distillation)算法(一阶段训练,同时进行任务训练和蒸馏训练)同时减少了KL散度。
论文提出的蒸馏算法能够最大程度的降低KL散度和交叉熵,通过实验也证明了Overhaul算法的有效性,说明提高教师网络和学生网络的输出相似度能够有效提高学生网络的性能。
消融研究
论文通过实验证明了蒸馏算法中各个部分对于最终性能的增益,如下表所示

批量归一化
大部分模型中都包含有批量归一化层,而BN层在设计上可分为训练模式和推理模式。在之前的知识迁移论文中,大都没有考虑到这个差异。论文认为在蒸馏训练中,教师网络和学生网络应该保持相同的归一化方式,所以论文设计了以下方法:
- 在学生转换中添加了
BN层; - 设置教师网络为训练模型,进行特征计算。
从实验结果来看,这种方式提供了额外的增益。如下表所示
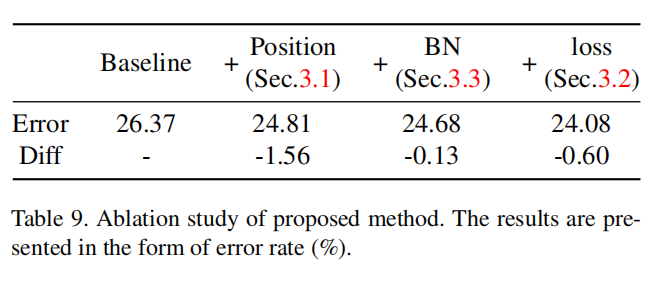
- 对于非特征蒸馏算法而言,不同模式的
BN对于最终训练结果差异性不大; - 对于
AT而言,其使用注意力图(减少的蒸馏特征),在推理模式下进行训练更好; - 对于其他特征蒸馏算法而言,使用训练模型进行训练均提高了最终精度。
小结
OFD算法的关键内容:
- 新的蒸馏位置:在
ReLU之前; - 新的教师转换函数:
Margin ReLU; - 新的距离函数:
Partial L2距离; - 同步教师-学生网络的
BN层:都采用训练模式。
额外思考:
- 论文认为正值特征更有用,是因为
ReLU的关系。它过滤了所有负值特征,导致后续网络层并没有使用到上层负相应特征;将ReLU函数倒过来,过滤所有正值函数,那么负值特征就更有用了; - 将蒸馏位置放置在
ReLU之前有种KD的思想,就是为学生网络提供尽可能多的暗知识,帮助学生网络进行训练。