[LR Scheduler]学习率退火
在标准随机梯度下降过程中,每次更新使用固定学习率(learning rate),迭代一定次数后损失值不再下降,一种解释是因为权重在最优点周围打转,如果能够在迭代过程中减小学习率,就能够更加接近最优点,实现更高的检测精度
学习率退火(annealing the learning rate)属于优化策略的一种,有3种方式实现学习率随时间下降
- 随步数衰减(
step decay) - 指数衰减(
exponential decay) 1/t衰减(1/t decay)
下面介绍这3种学习率退火实现,然后用numpy编程进行验证
随步数衰减
随步数衰减(step decay)指的是多次迭代后降低学习率再继续迭代
如果选择固定迭代次数,实现公式如下:
\[ lr = lr_{0} * \beta^{t/T} \]
- \(lr\)表示学习率
- \(lr_{0}\)表示初始学习率
- \(\beta\)表示衰减因子,通常是0.5
- \(t\)表示迭代次数
- \(T\)是一个常量,表示迭代次数
其中\(t/T\)是一个整数除法,比如\(2/4=0, 5/4=1\)
迭代多少次才进行学习率衰减取决于实际问题和模型,如果无法确定可以先打印出标准的随机梯度下降过程的验证集误差(val error),选择验证集误差不再下降的时候降低学习率
指数衰减
指数衰减(exponential decay)指的是学习率随迭代次数指数下降,数学公式如下:
\[ lr = lr_{0} e^{-kt} \]
- \(lr\)表示学习率
- \(lr_{0}\)表示初始学习率
- \(k\)表示衰减因子
- \(t\)是迭代次数
其衰减速度随指数下降,一方面可以提高初始学习率,另一方面可以结合随步数衰减策略,多次迭代后再衰减,这样可以探索更大的权重空间
1/t衰减
1/t衰减实现公式如下:
\[ lr = lr_{0}/(1+kt) \]
- \(lr\)表示学习率
- \(lr_{0}\)表示初始学习率
- \(k\)表示衰减因子
- \(t\)是迭代次数
衰减比较
假定初始学习率为1e-3,衰减因子k=0.5,随步长衰减方式每隔10次迭代衰减一次,结果如下
1 | import matplotlib.pyplot as plt |
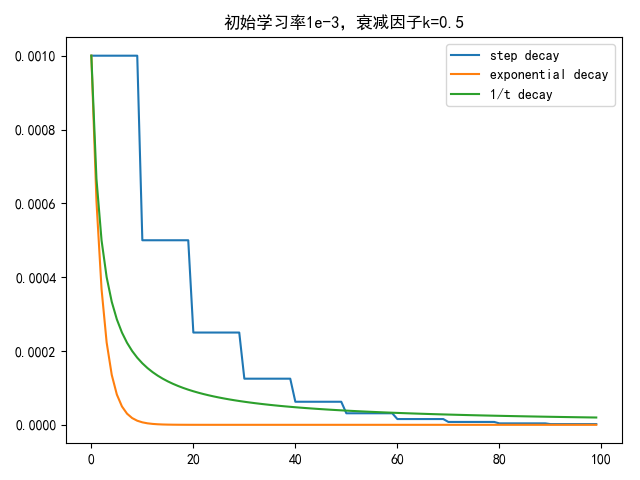
从数值上看,指数衰减最快,随步长衰减最不平滑,1/t衰减是前2者的折中
从概念上看,随步长衰减最具解释性
Iris分类
参考iris数据集,使用3层神经网络实现Iris数据集分类
网络和训练参数如下:
1 | # 批量大小 |
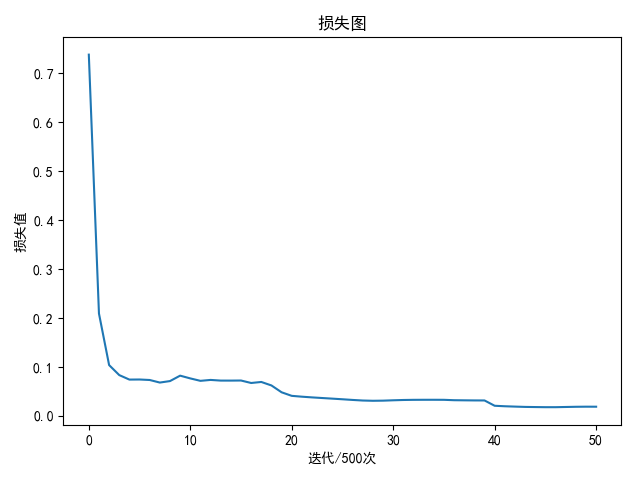
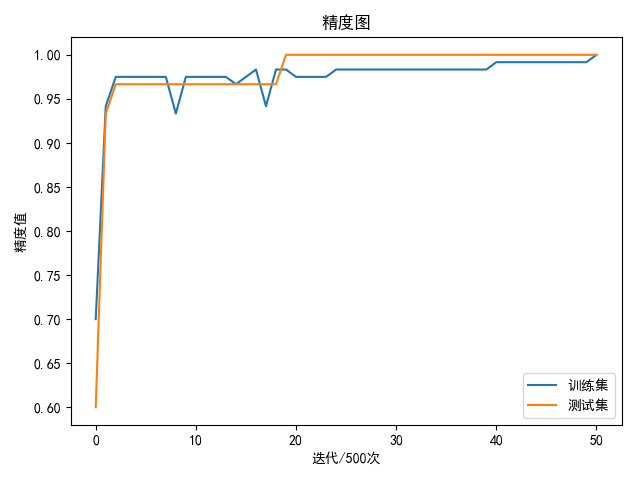
训练1万次得到最好的训练集精度98.33%,验证集精度为100.00%
使用随步数衰减方法,设置初始学习率为1e-3,每隔1万次迭代降低一半学习率
1 | epoch: 23500 loss: 0.017741 |
共训练25500次实现100%的训练集精度和测试集精度
1 | if __name__ == '__main__': |
完整代码:PyNet/src/three_layer_net_iris.py
参数地址:PyNet/model/three_layer_net_iris.pkl
Pytorch实现
Pytorch提供模块torch.optim.lr_scheduler用于学习率退火实现
参考How to use torch.optim.lr_scheduler.ExponentialLR?,lr_scheduler的step方法仅用于更新学习率,和反向传播无关
随步长衰减
有3种方法
- LambdaLR
- StepLR
- MultiStepLR
LambdaLR
class torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)
optimizer是优化器lr_lambda是lambda函数,输入为迭代次数,用于计算衰减率
每次迭代都通过lambda函数计算新的衰减率,再乘以初始学习率就是当前学习率
1 |
|
lambda1函数功能是每隔5次迭代提高1倍学习率,结果如下:
1 | [0.1] |
StepLR
class torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
每隔step_size次迭代降低gamma倍学习率
1 | ... |
每轮输出学习率如下
1 | [0.1] |
MultiStepLR
class torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
StepLR只能指定固定次数进行衰减,并且衰减会一直持续下去
MultiStepLR可以指定哪个迭代次数进行衰减,并指定衰减次数
milestones是一个升序列表,表示迭代下标,只有当前迭代次数是列表中的值时才衰减一次
1 | scheduler = MultiStepLR(optimer, milestones=[3, 5, 10], gamma=0.5) |
每轮输出学习率如下
1 | [0.1] |
指数衰减
class torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)
每轮迭代中学习率乘以gamma衰减因子