Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
原文地址:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
摘要
State-of-the-art object detection networks depend on region proposal algorithms to hypothesize object locations. Advances like SPPnet [1] and Fast R-CNN [2] have reduced the running time of these detection networks, exposing region proposal computation as a bottleneck. In this work, we introduce a Region Proposal Network (RPN) that shares full-image convolutional features with the detection network, thus enabling nearly cost-free region proposals. An RPN is a fully convolutional network that simultaneously predicts object bounds and objectness scores at each position. The RPN is trained end-to-end to generate high-quality region proposals, which are used by Fast R-CNN for detection. We further merge RPN and Fast R-CNN into a single network by sharing their convolutional features—using the recently popular terminology of neural networks with“attention” mechanisms, the RPN component tells the unified network where to look. For the very deep VGG-16 model [3], our detection system has a frame rate of 5fps (including all steps) on a GPU, while achieving state-of-the-art object detection accuracy on PASCAL VOC 2007, 2012, and MS COCO datasets with only 300 proposals per image. In ILSVRC and COCO 2015 competitions, Faster R-CNN and RPN are the foundations of the 1st-place winning entries in several tracks. Code has been made publicly available.
最先进的目标检测网络依赖于区域建议算法来假设目标位置。像[1]和[2]这样的进步已经减少了这些检测网络的运行时间,而区域建议计算成为了一个瓶颈。在这项工作中,我们引入了一个区域建议网络(RPN),它与检测网络共享全图像卷积特征,从而实现几乎免费的区域建议。RPN是一个全卷积网络,可以同时预测每个位置的目标边界和目标分数。对RPN进行端到端的训练,以生成高质量的区域建议,然后用于Fast R-CNN进行检测。我们通过共享它们的卷积特征,进一步将RPN和Fast R-CNN合并成一个网络 - 使用最近流行的带有“注意力”机制的神经网络,RPN部分告诉整个网络在哪里寻找。对于非常深的VGG-16模型[3],我们的检测系统在GPU上的帧速率为5fps(包括所有步骤),而在PASCAL VOC 2007、2012和MS COCO数据集上实现了最先进的目标检测精度,每幅图像只有300个建议。在ILSVRC和COCO 2015竞赛中,Fast R-CNN和R-CNN是在几个比赛中获得第一名的基础。代码已公开
- https://github.com/shaoqingren/faster-rcnn (in MATLAB)
- https://github.com/rbgirshick/py-faster-rcnn (in Python)
Fast R-CNN
Faster R-CNN是在Fast R-CNN的基础上改进的,先了解一下Fast R-CNN卷积架构
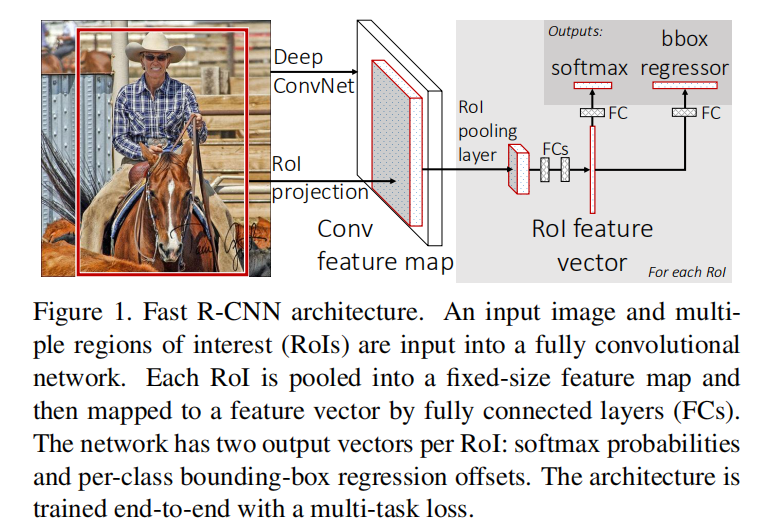
Fast R-CNN在特征图上提取候选区域,通过RoI Pooling层输出固定长度的特征向量,最后通过全连接层同时进行分类和边界框预测。这一网络架构拥有以下优点:
- 实现一个端到端的训练过程,不需要缓存额外特征
- 使用
RoI Pooling,释放对输入图像大小的限制
Fast R-CNN使用SelectiveSearch算法进行目标提取。选择性搜索算法通过图分割算法得到初始分割区域,然后利用分层分组算法组合更多的候选区域,最终得到一组过完备的候选区域
Faster R-CNN
Faster R-CNN提出了一个目标提取网络RPN,来替代Fast R-CNN使用的SelectiveSearch算法,能够实现接近实时的目标提取
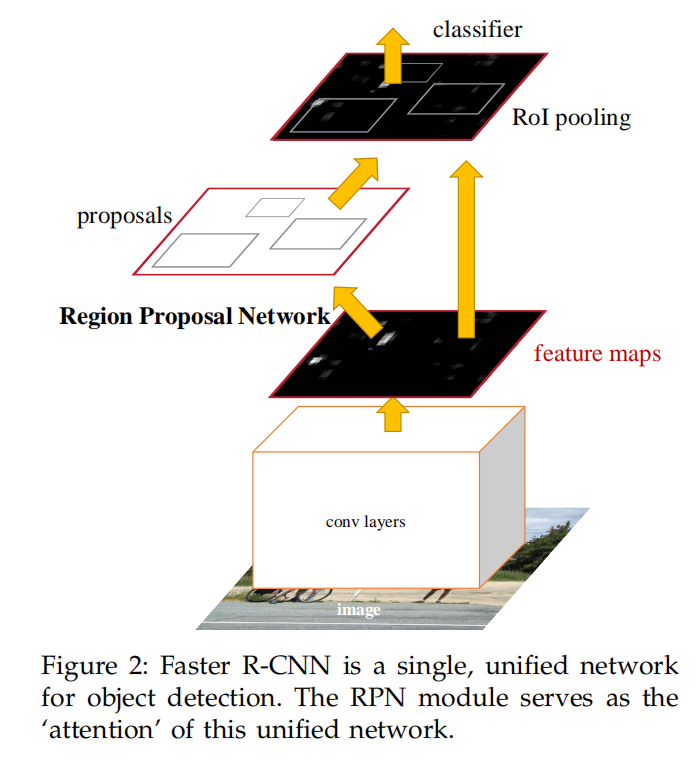
其完整的实现流程如下:
- 输入图像
- 经过卷积网络提取特征图
- 输入特征图到
RPN网络提取候选区域 - 从特征图中提取候选区域对应的特征
- 通过
RoI Pooling得到固定长度的向量 - 将特征向量输入到检测网络计算分类成绩和边界框偏移
在Faster R-CNN算法中,由2个网络组成:
RPN:全卷积模型,用于提取候选区域Fast R-CNN:计算卷积特征,计算分类成绩和边界框偏移
其中,RPN和Fast R-CNN共享计算得到的特征图
RPN
RPN(Region Proposal Network)是一个全卷积网络,其目的是提取候选区域
锚点
相比于SS算法通过图分割算法,结合图像底层特征(颜色/强度等)来构建初始候选框。RPN在特征图的每个cell中定义了多个不同尺度和长宽比的锚点框,通过人工定义的方式实现初始候选框
RPN选择了3种边界框大小(\([128^{2}, 256^{2}, 512^{2}]\))和3种长宽比(\([1:1, 1:2, 2:1]\))。超参数\(k\)表示每个cell中锚点框的个数,所以\(k=9\)
网络架构
从基础网络中计算得到特征图后,作为RPN的输入,经过一个卷积核大小为\(n\times n\)的卷积层(+ReLU)计算后,再分别使用\(1\times 1\)大小的卷积层计算分类成绩和边界框偏移
- 卷积层:计算区域建议特征
- 分类层:计算分类成绩
- 回归层:计算边界框偏移
在RPN网络中,仅对候选目标和背景进行分类;同时对候选目标的边界框进行一次矫正
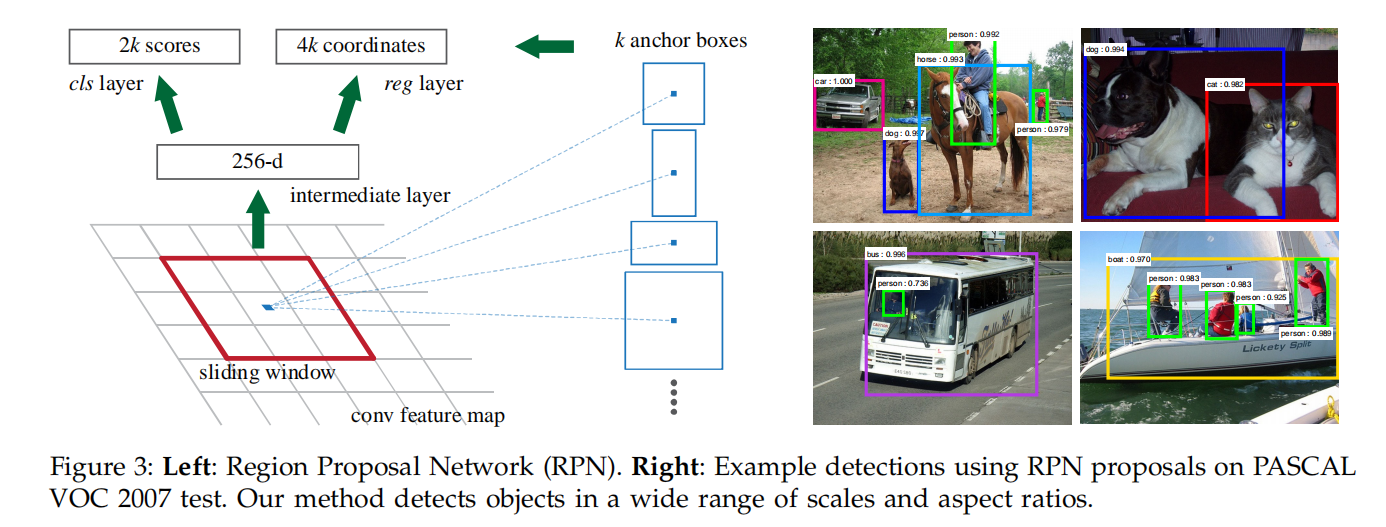
- 论文分别使用了
ZFNet和VGGNet作为最开始的卷积层,其深度分别为\(215\)和\(512\),卷积核大小为\(n=3\) - 分类层计算
2类成绩,所以其深度为\(2k\) - 回归层计算每个锚点的边界框偏移,所以其深度为\(4k\)
损失函数
正负样本
需要对每个锚点框设置一个标签(正或者负样本),用于RPN训练。赋值以下条件的锚点为正样本:
- 和某一个
GT拥有最高IoU的锚点 - 和任意一个
GT的IoU超过0.7
赋值IoU<0.3的锚点为负样本,居于中间(0.3<IoU<0.7)的锚点框不参与训练
多任务损失
使用Fast R-CNN的损失函数:
\[ L({p_{i}}, {t_{i}}) = \frac {1}{N_{cls}} \sum_{i} L_{cls}(p_{i}, p^{*}_{i}) + \lambda \frac {1}{N_{reg}} \sum_{i} p^{*}_{i}L_{reg}(t_{i}, t_{i}^{*}) \]
- \(i\)指的是每一批次中锚点框下标
- \(p_{i}\)指的是锚点\(p\)是否是候选目标的预测概率
- 如果锚点为正样本,那么\(p_{i}^{*}=1\),否则\(p_{i}^{*}=0\)
- \(t_{i}\)表示预测边界框的参数化坐标
- \(t_{i}^{*}\)表示正样本锚点对应的标注框的参数化坐标
对于回归损失\(L_{reg}\),使用Smooth L1 Loss;对于分类损失\(L_{cls}\),使用Softmax Loss。\(\lambda\)是一个超参数,用于平衡回归损失和分类损失,默认设置为\(10\)
训练
在实际训练过程中,使用如下设置:
SGD。初始学习率为1e-3,训练6万次后调整为1e-4,再执行2万次训练- 使用预训练模型。对于
VGG而言,微调conv3_1之后的网络 - 动量:
0.9 - 权重衰减:
5e-4 - 批量大小:
1
每张图像中的正负样本数差距很大,所以随机采集256个正负样本进行训练,正负样本比为\(1:1\)。如果正样本数量不够,则使用负样本填充
训练RPN和Fast R-CNN
因为RPN和Fast R-CNN检测器共享同一个基础网络,所以可以同时训练这两个网络。文章提出了多种训练方法
Alternating training(交替训练):先训练RPN,再训练Fast R-CNN,重复这一过程Approximate joint training(近似联合训练):同时训练RPN和Fast R-CNN。利用基础网络生成特征图;输入到RPN得到候选区域;再结合特征图和候选区域得到候选区域特征;输入到Fast R-CNN检测器进行训练Non-Approxmiate joint training(非近似联合训练)
文章集合了上述训练方法,提出了一个4步交替训练方法:
- 使用预训练模型微调
RPN网络 - 使用
RPN网络生成的候选区域训练Fast R-CNN检测器(检测网络同样使用预训练模型微调) - 使用
Fast R-CNN检测器训练RPN网络,固定共享卷积层,仅微调RPN - 保持共享卷积层和
RPN,微调Fast R-CNN的检测模块
在实际操作中使用了第2种方法
实现细节
- 输入图像:等比缩放。较短边缩放到
600 - 锚点:在每个
cell中定义的锚点边界框会出现超出图像边界的情况。在训练过程中,忽略超出边界的锚点;在测试阶段,需要裁剪超出的边界 NMS:按RPN网络计算得到的分类成绩进行排序,去除IoU超过0.7的候选建议top-k:完成NMS后,取前几个候选建议进行后续的检测。在训练阶段,取top-k=2000;在测试阶段,取top-k=300
实现
Faster R-CNN最重要的贡献就是提出了RPN网络,实现如下:object-detection-algorithm/RPN
论文中对参与训练的正负样本进行了严格的限制,比如正负样本总数为256,比例为1:1,正样本不足的话由负样本填充,不过实际实现过程中发现正样本数目经常为个位数,这样也会导致正负样本极度不平衡
另外在损失函数中设置了超参数\(\lambda = 10\),这会造成梯度爆炸,直接设置\(\lambda=1\)即可