[Going deeper with convolutions]进一步深入卷积操作
文章Going deeper with convolutions提出了一种新的卷积架构 - Inception,基于此实现的CNN架构GoogLeNet能够得到更好的分类和检测效果
摘要
We propose a deep convolutional neural network architecture codenamed Inception, which was responsible for setting the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC14). The main hallmark of this architecture is the improved utilization of the computing resources inside the network. This was achieved by a carefully crafted design that allows for increasing the depth and width of the network while keeping the computational budget constant. To optimize quality, the architectural decisions were based on the Hebbian principle and the intuition of multi-scale processing. One particular incarnation used in our submission for ILSVRC14 is called GoogLeNet, a 22 layers deep network, the quality of which is assessed in the context of classification and detection.
我们提出了一种深度卷积神经网络架构 - Inception,在2014年ImageNet大规模视觉识别挑战赛(ILSVRC14)中得到了最好的分类和检测实现。这种架构的主要特点是提高了网络内部计算资源的利用率。这是通过精心设计实现的,该设计允许增加网络的深度和宽度,同时保持计算预算不变。为了优化模型,该架构基于Hebbian原则和多尺度处理的直觉。在我们提交的ILSVRC14中使用的一个特定实现称为GoogLeNet,这是一个22层的深层网络,其用于分类和检测实现
1x1 卷积
作用:
- 通过激活函数提高卷积表达能力
- 通过控制滤波器个数来减少输出数据体深度,实现维度衰减,移除计算瓶颈
思考
最简单的提高深度神经网络表达能力的方式是增大网络大小,一方面是增加网络的层数,另一方面是提高每层网络的宽度
缺点:
- 更大的网络意味着更多的参数,这使得网络更容易过拟合,因为训练数据是有限的
- 增加网络规模会导致计算资源的急剧增加,而且很容易造成资源的浪费(很多权重最后会趋近于
0)
解决这两个问题的基本方法是最终从完全连接到稀疏连接的架构,甚至是在卷积中
基于Hebbian原则:neurons that fire together, wire together(一起放电、连接在一起的神经元)
架构细节
The main idea of the Inception architecture is based on finding out how an optimal local sparse structure in a convolutional vision network can be approximated and covered by readily available dense components
Inception架构的主要思想是基于发现卷积视觉网络中的最优局部稀疏结构能够被密集组件近似覆盖
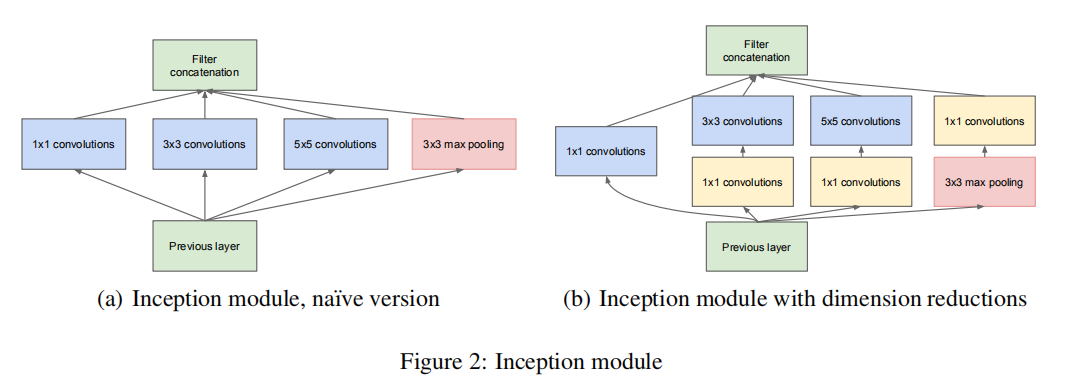
当前Inception架构基于3种滤波器尺寸:1x1、3x3、5x5;同时由于池化操作对于现有卷积网络的成功是至关重要的,因此在每个阶段增加一个可替代的并行池化路径
As these “Inception modules” are stacked on top of each other, their output correlation statistics are bound to vary: as features of higher abstraction are captured by higher layers, their spatial concentration is expected to decrease suggesting that the ratio of 3×3 and 5×5 convolutions should increase as we move to higher layers.
由于这些“Inception模块”相互堆叠,它们的输出相关统计数据必然会有所不同:随着更高抽象的特征被更高层捕获,它们的空间集中度预计会降低,这表明随着我们向更高层移动,3×3和5×5卷积的比率应该会增加
但是使用5x5卷积核以及池化层的增加会导致:它们的输出滤波器的数量等于前一阶段的滤波器的数量,池化层的输出与卷积层的输出的合并将不可避免。在使用3x3和5x5之前,可通过1x1卷积进行降维操作,同时使用1x1卷积还能够进一步实现rectified linear activation功能(就是用ReLU激活函数提高权重非线性能力)
In general, an Inception network is a network consisting of modules of the above type stacked upon each other, with occasional max-pooling layers with stride 2 to halve the resolution of the grid. For technical reasons (memory efficiency during training), it seemed beneficial to start using Inception modules only at higher layers while keeping the lower layers in traditional convolutional fashion. This is not strictly necessary, simply reflecting some infrastructural inefficiencies in our current implementation.
一般来说,Inception网络是由上述类型的模块相互堆叠而成的网络,偶尔会有最大池层,其步长为2,以将网格的分辨率减半。出于技术原因(训练期间的内存效率),所以只在较高层使用Inception模块,同时保持较低层的传统卷积方式。这似乎是有益的,但绝对不是必要的,只是反映了我们当前设备中一些基础设施的效率低下
One of the main beneficial aspects of this architecture is that it allows for increasing the number of units at each stage significantly without an uncontrolled blow-up in computational complexity. The ubiquitous use of dimension reduction allows for shielding the large number of input filters of the last stage to the next layer, first reducing their dimension before convolving over them with a large patch size. Another practically useful aspect of this design is that it aligns with the intuition that visual information should be processed at various scales and then aggregated so that the next stage can abstract features from different scales simultaneously
这种体系结构的一个主要优点是,它允许在每个阶段显著增加单元的数量,而不会导致计算复杂性的失控膨胀。降维的普遍使用允许将最后一级的大量输入滤波器屏蔽到下一层,首先降低它们的尺寸,然后用大的卷积核尺寸卷积它们。这种设计的另一个实用方面是,它与直觉一致,即视觉信息应该在不同的尺度上进行处理,然后进行汇总,以便下一阶段可以同时从不同的尺度提取特征
GoogLeNet
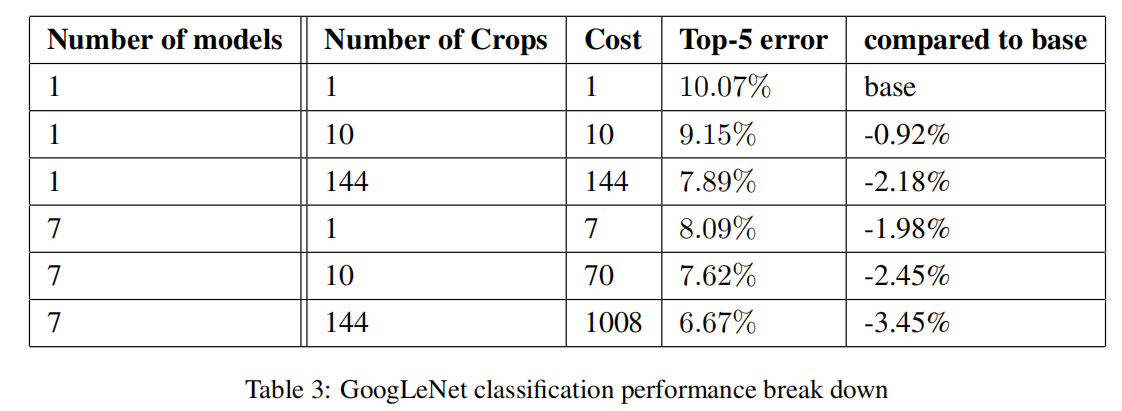
在模型集成中,使用6到7个模型(使用了完全相同的拓扑结构,除了用不同的采样方法训练)
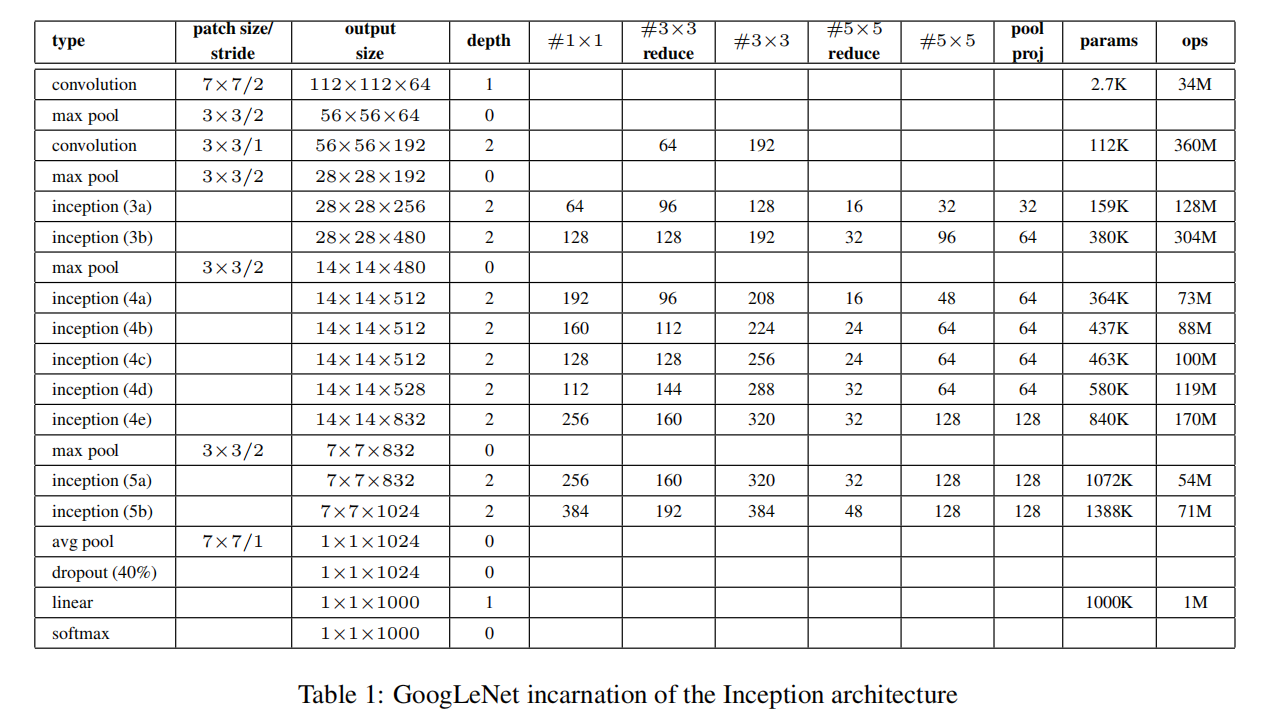
模型细节
如果只计算带参数的层,网络有22层(如果我们也计算池化层,则为27层)。用于构建网络的总层数(独立构建块)约为100层
- 激活函数:
ReLU - 输入图像:
224x224,RGB图像(减去均值图像) #3x3 reduce和#5x5 reduce表示在使用3x3和5x5卷积之前使用了1x1卷积的数量- 在
pool proj列中查询得到用于池化层之后的1x1卷积滤波器数量 - 全连接层:使用
average pooling替代全连接层
额外分类器
通过添加连接到这些中间层的辅助分类器,我们期望在分类器的较低阶段鼓励区分,增加传播回来的梯度信号,并提供额外的正则化。这些分类器采用较小的卷积网络的形式,放在Inception (4a)和(4d)模块的输出之上
在训练过程中,它们的损失被加到网络的总损失中,并带有一个折扣权重(辅助分类器的损失被加权为0.3);在推理时,这些辅助网络被丢弃。包括辅助分类器在内的附加网络的确切结构如下:
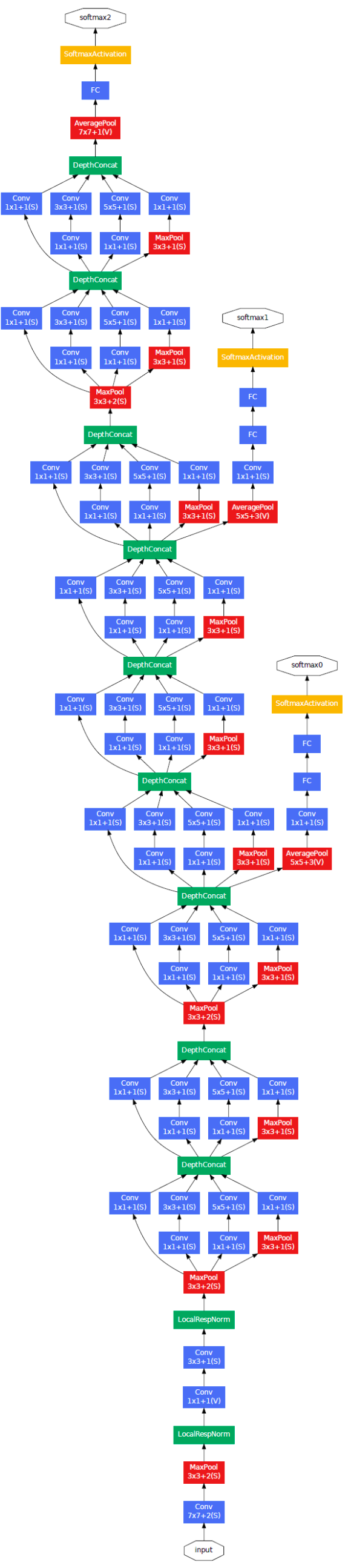
对于辅助分类器:
- 使用滤波器大小为
5x5,步长为3的平均池化层,在(4a)阶段得到4x4x512大小输出,在(4d)阶段得到4x4x528大小输出 - 使用
128个1x1大小卷积滤波器,用于维度衰减和整流线性激活 - 全连接层使用
1024个滤波器以及ReLU - 随机失活层:失活概率
70% softmax分类器,用于分类1000类
训练方法
- 优化器:
SGD,动量为0.9 - 随步长衰减:每隔
8轮降低4%学习率
一个在赛后被证实非常有效的处理方法:对图像的各种大小的块进行采样,这些块的大小均匀地分布在图像面积的8%和100%之间,并且其纵横比在3/4和4/3之间随机选择
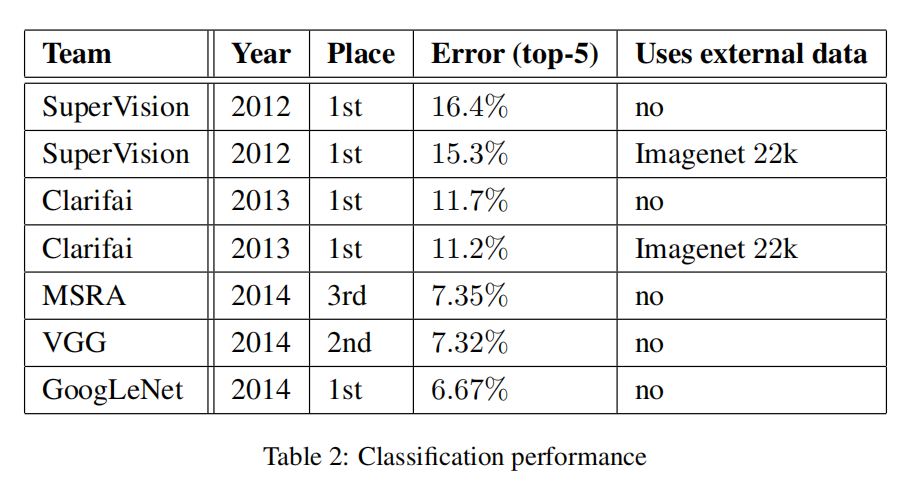
ILSVRC 2014分类挑战
简介
ILSVRC 2014分类挑战:共1000类别,120万幅训练图像,5万幅验证图像,10万幅测试图像.每个图像都有一个标注的真实类别
评判标准
使用两个比较标准:
Top-1准确率(the top-1 accuracy rate)Top-5错误率(the top-5 error rate)
训练技巧
额外的训练技巧如下:
- 使用不同的图像采样方法训练了
7个相同的GoogLeNet模型,进行集成预测 - 在测试阶段,缩放图像到
4个尺度(更短边缩放至256, 288, 320, 352)。获取缩放后图像的左/中/右的方块(取最小边为长度的正方形);对于肖像图像,取上/中/下。对于每个方块,取中心和4个角的224x224裁减图像,同时将方块缩放至224x224,包括它们的镜像版本。最终得到4x3x6x2=144个测试图像 - 使用模型集成对测试图像进行分类概率计算,并平均每类概率
Gitalk 加载中 ...