Deep Learning for Content-Based Image Retrieval: A Comprehensive Study
原文地址:Deep Learning for Content-Based Image Retrieval: A Comprehensive Study
摘要
Learning effective feature representations and similarity measures are crucial to the retrieval performance of a content-based image retrieval (CBIR) system. Despite extensive research efforts for decades, it remains one of the most challenging open problems that considerably hinders the successes of real-world CBIR systems. The key challenge has been attributed to the well-known "semantic gap" issue that exists between low-level image pixels captured by machines and high-level semantic concepts perceived by human. Among various techniques, machine learning has been actively investigated as a possible direction to bridge the semantic gap in the long term. Inspired by recent successes of deep learning techniques for computer vision and other applications, in this paper, we attempt to address an open problem: if deep learning is a hope for bridging the semantic gap in CBIR and how much improvements in CBIR tasks can be achieved by exploring the state-of-the-art deep learning techniques for learning feature representations and similarity measures. Specifically, we investigate a framework of deep learning with application to CBIR tasks with an extensive set of empirical studies by examining a state-of-the-art deep learning method (Convolutional Neural Networks) for CBIR tasks under varied settings. From our empirical studies, we find some encouraging results and summarize some important insights for future research.
学习有效的特征表示和相似性度量对于基于内容的图像检索(CBIR)系统的检索性能至关重要。尽管几十年来进行了广泛的研究,它仍然是最具挑战性的开放性问题之一,极大地阻碍了现实世界中CBIR系统的成功。关键的挑战被归因于众所周知的“语义鸿沟”问题,即机器捕获的低级图像像素与人类感知的高级语义概念之间存在的鸿沟。在各种技术中,机器学习一直被视为是一个可行的能够弥补语义鸿沟的方向。最近应用于计算机视觉和其他应用的深度学习技术取得了成功,受此启发,我们试图解决一个开放性问题:深度学习是否有希望弥合CBIR中的语义鸿沟,以及通过探索用于学习特征表示和相似性度量的最新深度学习技术,CBIR任务可以实现多大程度的改进。具体而言,我们研究了一个应用于CBIR任务的深度学习框架,在各种设置下对最新的深度学习方法(卷积神经网络)进行了大量实证研究。通过实验调研,我们发现了一些令人鼓舞的结果,并总结了一些对未来研究的重要见解。
引言
论文调查了从图像中学习特征表示的深度学习算法,以及它们对于CBIR任务的相似性度量。论文试图解决以下三个问题:
- 深度网络学习能否学习得到有效的的能够作用于
CBIR任务的图像表示? - 与传统人工设计的特征相比,深度特征能够带来多大的改进?
- 如何将已训练好的深度网络模型迁移到
CBIR数据集?
论文构造了一个作用于CBIR任务的深度学习框架,应用最好的深度学习方法(卷积神经网络)从图像中学习特征表示,并且在不同CBIR数据集中进行完备实验。
论文主要工作如下:
- 构造了用于
CBIR任务的深度学习框架,通过训练卷积神经网络来学习图像的有效特征; - 构造了完备实验,在不同设置下将深度卷积神经网络应用于不同的
CBIR任务。
框架
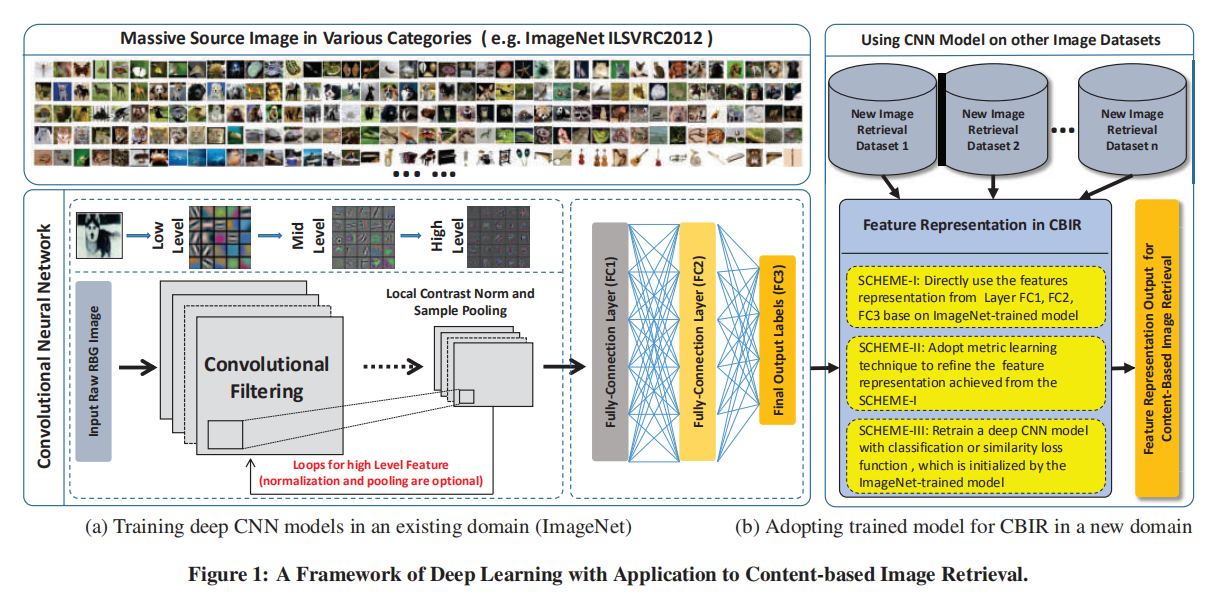
论文采用了AlexNet,并且使用ImageNet预训练的网络权重对不同的CBIR任务进行迁移训练,调查卷积神经网络能否应用于CBIR任务。
特征表示
论文使用AlexNet最后三个全连接层输出(FC1 / FC2 / FC3)作为特征表示,分别命名为DF.FC1 / DF.FC2 / DF.FC3。
为了调查如何有效的将深度卷积网络的特征应用于CBIR任务,论文设计了3种不同的特征使用方式,来评估深度网络输出的特征向量对于CBIR任务的有效性以及提高幅度。
模式一:直接使用
直接使用预训练模型的权重,作用于测试数据集,采集最后三个全连接层的输出(DF.FC1 / DF.FC2 / DF.FC3)作为特征向量。这种使用的前提是目标数据集和训练数据集拥有相似的场景。
Note:论文在得到特征向量后,会额外执行一个归一化操作(l2-norm)。
模式二:相似性学习
通过相似性学习算法在CBIR数据集中微调预训练模型,论文采用OASIS(Online Algorithm for Scalable Image Similarity Learning)算法,其作用是在稀疏表示上学习双线性相似性度量。
假定三元组集合
计算两个样本之间的相似函数(双线性模式(bilinear form))如下:
其中hinge loss为三元组模式:
全局损失
经过模式二训练后的特征表示命名为DF.FC1+SL / DF.FC2+SL / DF.FC3+SL
模式三:微调训练
可分为两种训练方式,
- 方式一:通过目标数据集标签进行微调训练,提取微调训练后的特征向量,命名为
ReCLS.FC1 / ReCLS.FC2 / ReCLS.FC3 - 方式二:相似性训练,相比于模式二,采用了更有效的相似性度量。计算公式如下所示:
假定输入图像为
对于输入对hinge loss定义如下
经过相似性微调训练后得到的特征向量命名为ReDSL.FC1 / ReDSL.FC2 / ReDSL.FC3。
Note:当无法获取数据的类别标签时,可以采用边信息(side information)进行相似性学习。
另外,论文还提到了一个微调的小trick,就是在模型前几层使用更小的学习率。
数据集

论文在多个数据集上进行了实验,以验证不同模式下的深度特征对于图像检索任务的性能
ImageNet:通用数据集。超过1500w数据和接近22000个类别。论文使用它的子集ImageNet ILSVRC 2012进行预训练,共有1000类,每类差不多1000张图像,总共有120w训练数据、5w张验证数据和15w张测试数据;Caltech 256:目标数据集。Caltech-256物品分类数据集由Caltech-101数据集演变而来,该数据集选自Google Image数据集,并手工去除了不符合其类别的图片。在该数据集中共有30,607张图片,256个图片类别,每个类别包括超过80张图片。更多信息查看Caltech256 图像分类竞赛;Oxford:地标数据集。牛津建筑数据集,包含从Flickr收集的5062张图像,为11座地标建筑提供了55个查询集,每个地标5个。更多信息查看Oxford5k (Oxford Buildings);Pairs:地标数据集。类似于Oxford5k数据集,包含从Flickr收集的6392张图像和55个查询集;Pubfig83LFW:人脸数据集。结合了两个常用的人脸数据集:PubFig83和LFW。更多信息查看PubFig83 + LFW Dataset。
实验
主要设计了两个场景:
- 相同环境。将
ImageNet上经过分类预训练后的模型应用于图像检索实现; - 不同环境。将
ImageNet数据集上预训练后的模型应用到其他数据集,以测试训练环境和测试环境不相同的情况下CNN模型的特征提取能力。
论文采用了三种图像检索领域广泛使用的评估标准:均值平均精度(the mean average precision (mAP))、前k张排序精度(the precision at particular ranks ("P@K"))和前k张召回率(the recall at particular ranks ("R@K"))。
ImageNet
因为都在ImageNet进行分类预训练和图像检索测试,所以使用模式一的方式提取特征向量。在ILSVRC 2012数据集上评估检索性能,使用5w张验证集图片作为查询集,在120w张训练集图像中进行检索。
论文比较了几种特征提取方式,包括几种词袋(bag-of-words, BoW)实现,实验结果如下表一所示:
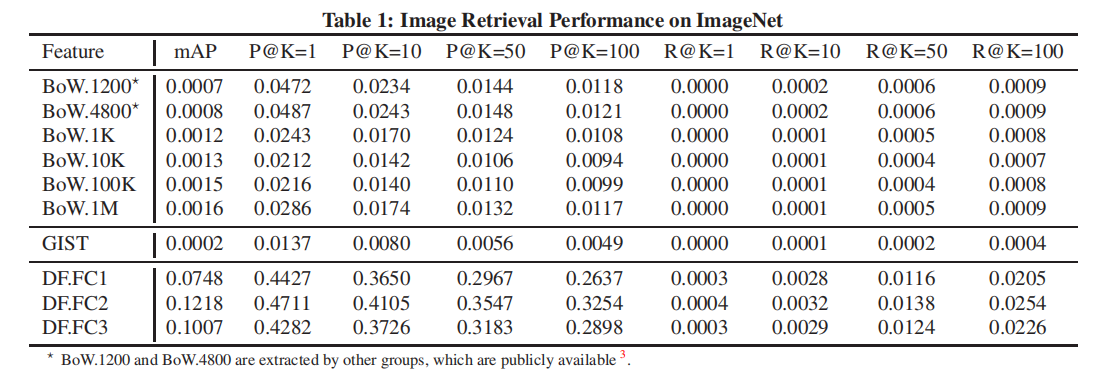
BoW.1200和BoW.4800是通过objectect训练得到的
从上述表格中,可以得出以下结论:
BoW特征表示在ImageNet数据集上进行图像检索的性能并不出色;BoW特征长度越长,性能越强。最好的BoW.1M仅能够实现0.0016 mAP;AlexNet最后三层提取的特征表示(FC1/FC2/FC3)均能够实现非常好的检索性能;FC2(最后一个隐藏层输出)特征表示能够实现最好的47.11% top1精度;
Note:论文在实验中并没有增加额外的后处理,比如基于几何约束的重排序(geometric constraint based reranking)或者查询扩展(query expansion)操作。
下图3展示了不同查询图像在不同特征表示使用下的查询结果。

Caltech256
分别采集Caltech256的子集:10类/20类/50类,每类分别采集40张训练图像和25张测试图像。对于BoW特征向量,使用了几种距离度量函数进行微调训练;对于CNN模型,使用模式一和模式二方式采集特征表示。实验结果如下表2所示:
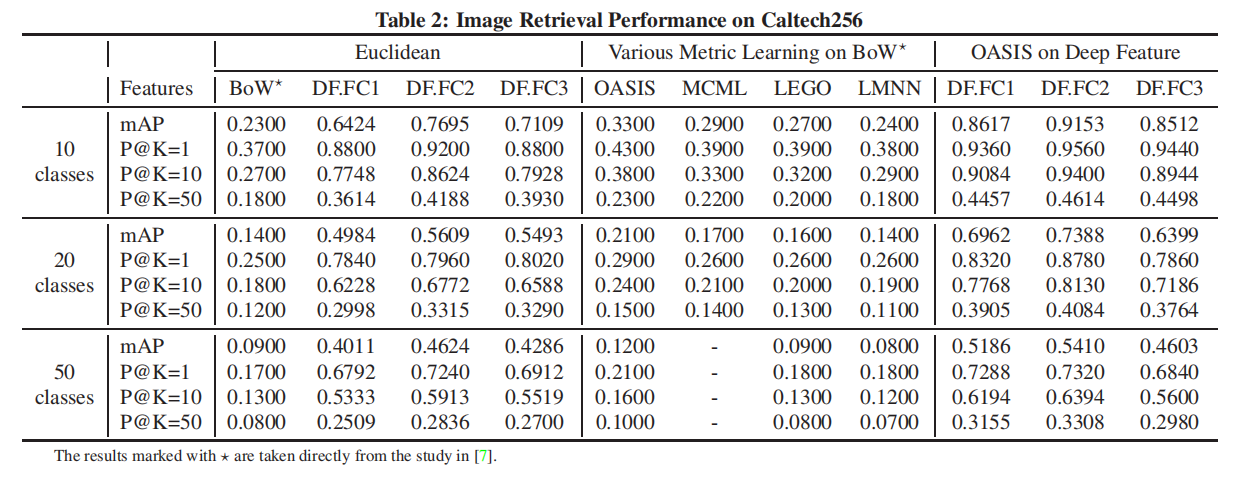
- 直接采用预训练模型的
DF.FC1/2/3特征表示一致性超越了BoW特征表示,同时DF.FC2仍旧获取了最好的性能; - 和
ImageNet图像检索实验一致,DF.FC3的性能超越了DF.FC1;- 论文给出的解释:
Caltech256类似于ImageNet,不同类别之间的差异性非常大,而最后一层输出拥有最丰富的语义信息,所以能够得到更好的结果;
- 论文给出的解释:
- 采用相似性学习算法
OASIS后的CNN模型能够得到最好的性能;10类任务的mAP从0.23提升到0.33;- 经过相似性训练后,
DF.FC1的性能反而比DF.FC3高了,说明DML能够探索得到更丰富的语义信息。
Oxford5k/Paris6k
论文还在两个地标建筑数据集上进行了实验,测试了三种CNN模型特征表示,实验结果如下表3和下表4所示:
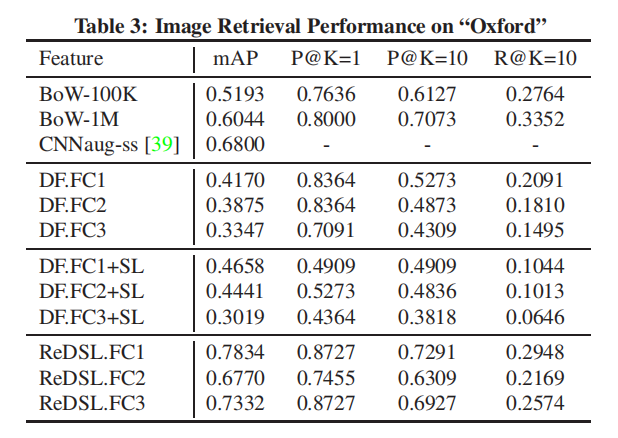
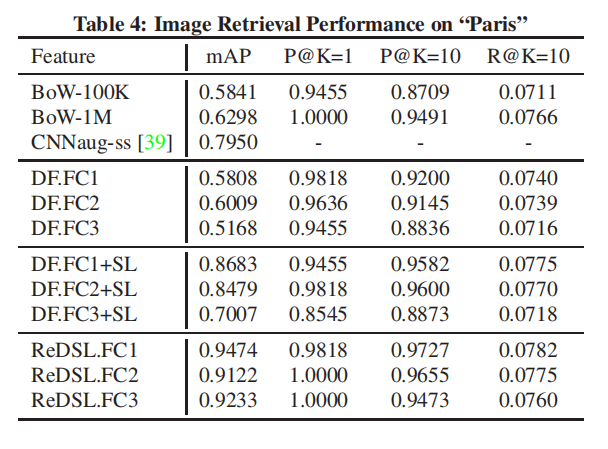
- 相比于之前数据集,
BoW在这两个地标建筑数据集上实现了很好的性能;BoW.1M在Oxford5k和Paris6k数据集上的mAP分别是0.6044和0.6298;- 论文分析:建筑图像包含了很多有效的边/角信息,非常适用于
BoW采集;
- 模式一特征表示的性能非常差
DF.FC1和DF.FC2的性能高于DF.FC3,说明Image的语义信息不适用于这两个数据集;- 当目标数据集和训练数据集存在非常大的差异性时,无法直接进行使用特征表示;
- 经过相似性训练后,模式二特征表示能够提 高模型性能;
- 模式三特征表示能够获取最好的性能,论文的解释没有很理解???
Pubfig83LFW
比较了模式一、模式三以及手动设计特征的性能,结果如下表5所示:

从实验结果来看,模式三微调训练得到的特征表示就是好,再次证明了CNN模型的迁移能力。
小结
这是一篇2014年发布的论文,通过大量的实验证明了:
- 卷积神经网络(深度学习)提取的图像特征能够有效的作用于
CBIR任务; - 预训练对于卷积神经网络的必要性,不论目标数据集和预训练数据集是否属于相似场景;
- 微调训练的必要性,直接使用预训练模型的特征表示不一定超过人工设计特征的性能,但是经过微调后的
CNN特征表示能够得到最好性能; - 使用模型(
AlexNet)倒数第二层的特征向量对于CBIR任务而言拥有最好的性能表现。
现在是2022年,不管有没有看过这篇论文,上面的结论可以说是common sense了,在各种CBIR任务中大量的应用了各种架构的卷积神经网络;前段时间同事也做了类似的测试,得到的结论和上面是一致的。
- 卷积神经网络的有效性;
- 预训练以及微调训练的必要性;
- 使用倒数前几层的特征表示而不是最后输出层。
未找到相关的 Issues 进行评论
请联系 @zjykzj 初始化创建