NIN
文章Network In Network提出一种新的深度网络结构mlpconv,使用微神经网络(micro neural network)代替传统卷积层的线性滤波器,同时利用全局平均池化(global average pooling)代替全连接层作为分类器,在当时的CIFAR-10和CIFAR-100上实现了最好的检测结果
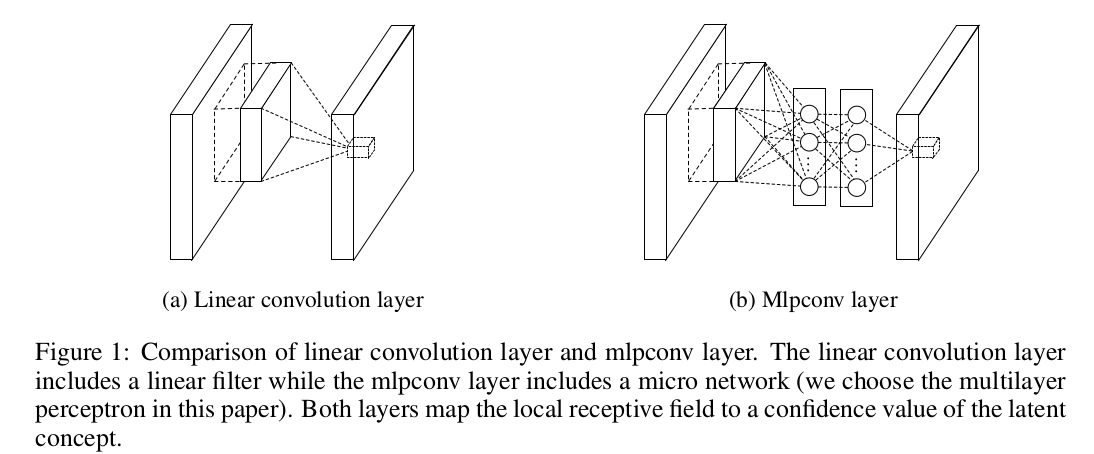
多层感知器池化层
传统卷积层
传统卷积层执行滤波器和局部感受野的内积操作(inner product),随后执行非线性激活函数,输出的结果称为特征图(feature map)。实现如下:
卷积层滤波器是一个线性模型(generalized linear model,GLM),仅在输入数据是线性可分的情况下,GLM才能得到很好的抽象结果
为了能够在高度非线性数据中获取正确抽象信息,卷积层使用了过完备(over-complete)的滤波器,以此来涵盖所有潜在的变化,这会加重下一层滤波器的负担
Maxout Network
Maxout网络在特征图上执行最大池化操作,其操作作为分段线性逼近器(piecewise linear approximator)能够近似所有的凸函数(approximating any convex functions)
Maxout网络的缺陷在于它依赖于输入空间是一个凸集
MLPConv
径向机网络(radial basis network)和多层感知器(multilayer perceptron,MLP)是已知通用的函数逼近器(universal function approximators),MLPConv使用了MLP作为滤波器,有以下理由:
MLP兼容于卷积神经网络结构,比如反向传播训练MLP同样是一个深度模型,符合特征重用精神(the spirit of feature re-use)
MLPConv结构如下
计算公式如下:
MLP层数,在MLP的每层操作完成后使用ReLU作为激活函数
从跨通道(跨特征图)的角度来看,上式等同于在卷积层中执行级联跨通道参数池化(cascaded cross channel parameteric pooling)操作,每个跨通道参数池化层对输入特征图执行权重线性重组
单个MLPConv操作等同于级联多个跨通道参数池化层,这种级联的跨通道参数池化结构允许跨通道信息的交互学习
从实现上看,单个跨通道参数池化层等同于
全局平均池化层
传统神经网络中,使用卷积神经网络作为特征提取器,使用全连接层作为分类器,很难解释全连接层中发生的变化
使用全局平均池化层(global average pooling layer, GAP)替代全连接层作为分类器有以下优势:
- 有很好的可解释性,它强制了特征映射和类别之间的对应,特征图可以解释为类别置信图
- 全连接层易于过拟合,强烈依赖于正则化策略,而GAP是一个天然的正则化器(没有参数),能够避免过拟合
GAP求和了空间信息,对于输入数据的空间转换有更好的鲁棒性
GAP计算:最后一个MLPConv提取的特征图数据体作为GAP的输入,通过空间平均特征图得到二维结果特征图,将结果特征图向量化后作为输出直接输入到softmax分类器
比如输入特征图数据体大小为
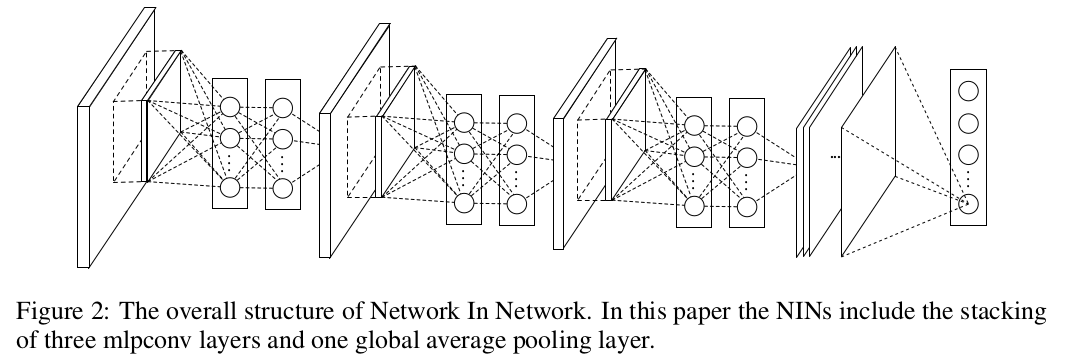
NIN
文章提出新的网络模型NIN(Network In Network),底层使用多个MLPConv堆叠,顶层使用GAP和softmax分类器
模型细节
文章给出的模型内容
共
3个MLPConv,每个MLPConv使用一个3层MLP每个
MLPConv后接一个Max池化层,步长为2模型最后是一个
GAP和softmax分类器随机失活操作作用于前
2个MLPConv的输出
参考Network-in-Network Implementation using TensorFlow的实现细节如下:
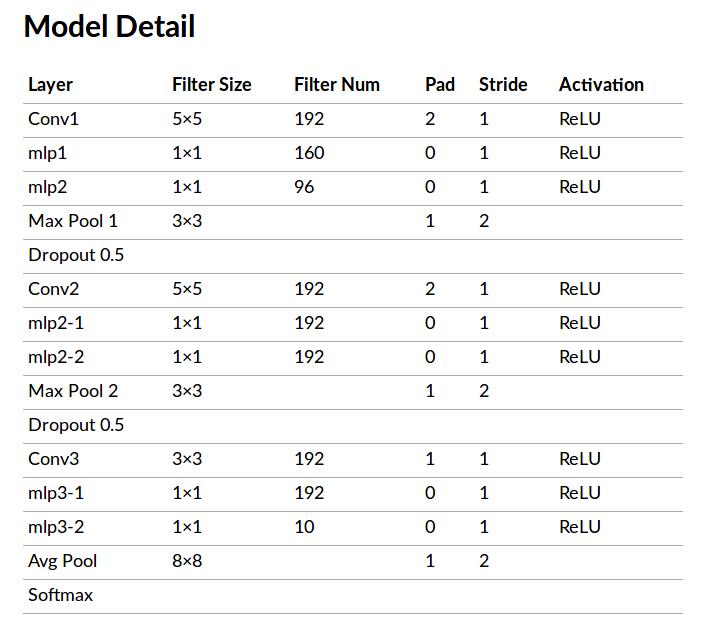
注意 1:上述模型假设输入数据体空间尺寸为
注意 2:经过计算,最大池化层步长为
小结
不同于可视化理解卷积神经网络的思路,NIN专注于提高单层抽象能力,同样实现了模型性能的提升
Gitalk 加载中 ...