RandAugment: Practical automated data augmentation with a reduced search space
原文地址:RandAugment: Practical automated data augmentation with a reduced search space
官方实现:tensorflow/tpu
Pytorch实现:pytorch/vision
摘要
Recent work has shown that data augmentation has the potential to significantly improve the generalization of deep learning models. Recently, automated augmentation strategies have led to state-of-the-art results in image classification and object detection. While these strategies were optimized for improving validation accuracy, they also led to state-of-the-art results in semi-supervised learning and improved robustness to common corruptions of images. An obstacle to a large-scale adoption of these methods is a separate search phase which increases the training complexity and may substantially increase the computational cost. Additionally, due to the separate search phase, these approaches are unable to adjust the regularization strength based on model or dataset size. Automated augmentation policies are often found by training small models on small datasets and subsequently applied to train larger models. In this work, we remove both of these obstacles. RandAugment has a significantly reduced search space which allows it to be trained on the target task with no need for a separate proxy task. Furthermore, due to the parameterization, the regularization strength may be tailored to different model and dataset sizes. RandAugment can be used uniformly across different tasks and datasets and works out of the box, matching or surpassing all previous automated augmentation approaches on CIFAR-10/100, SVHN, and ImageNet. On the ImageNet dataset we achieve 85.0% accuracy, a 0.6% increase over the previous state-of-the-art and 1.0% increase over baseline augmentation. On object detection, RandAugment leads to 1.0-1.3% improvement over baseline augmentation, and is within 0.3% mAP of AutoAugment on COCO. Finally, due to its interpretable hyperparameter, RandAugment may be used to investigate the role of data augmentation with varying model and dataset size. Code is available online.
最近研究表明数据扩充拥有显著提高深度模型泛化能力的潜力。到目前为止,自动增强策略已经在图像分类和目标检测方面实现了最先进的结果。虽然这些策略的优化目的以为了提高验证集精度,但是它们也在半监督学习领域实现了最好效果,同时提高了对图像常见损坏的鲁棒性。大规模采用这些方法的一个障碍是单独的搜索阶段,这增加了训练的复杂性,并且可能后续增加计算成本。此外,由于单独的搜索阶段,这些方法不能基于模型或数据集大小调整正则化强度。自动增强策略通常在小数据集上训练小模型,然后应用于训练更大的模型。在这项工作中,我们消除了这两个障碍。RandAugment的搜索空间显著降低,这使得它可以在目标任务上进行训练,而不需要单独的代理任务。此外,RandAugment将整个训练过程参数化,这样就可以调整正则化强度来适应不同的模型和数据集大小。RandAugment适用于不同的任务和数据集,并且开箱即用,匹配或超越了之前在CIFAR-10/100、SVHN和ImageNet上的所有自动增强方法。在ImageNet数据集上实现了85.0%准确率,比以前的最先进算法提高了0.6%,比基准增强策略提高了1.0%。在目标检测方面,RandAugment比基准增强策略提高了1.0-1.3%,在COCO数据集上比AutoAugment高0.3% mAP。最后,通过其可解释性的超参数,RandAugment可用于研究在不同模型和数据集大小下数据增强的作用。代码已开源:github.com/tensorflow/tpu/tree/master/models/official/efficientnet
引言
- 传统数据增强实现:领域专家手动设计,不同领域的增强策略很难直接移植;
- 自动数据增强实现:设计搜索空间,包含独立的搜索阶段:用小模型在小的代理数据集上进行搜索,获取得到增强策略后应用于更大数据集或更大模型。
- 优点:自动搜索的数据增强策略可以显著提高模型准确率和模型鲁棒性,并且具有可迁移性,在推理阶段没有耗时;
- 缺点:需要单独的搜索步骤,提高训练的复杂度和计算需求。
论文通过实验证明了单独搜索阶段产生的自动搜索策略对于更大的数据集和模型而言并不是最优的,因为增强策略的强度依赖于模型和数据集大小。论文提出一种新的自动搜索算法 - RandAugment,仅需通过简单的网格搜索即可创建一个极度缩减的搜索空间,不再需要额外的搜索阶段,在目标模型和数据集上应用即可。

AutoAugment
以AutoAugment为例,之前单独的搜索步骤的大体流程实现如下:
- 使用
PIL库定义的14种图像转换操作加上Cutout和SamplePairing作为搜索空间的基本操作; - 每个操作拥有两个超参数:发生的概率和操作的幅度。并且发生概率和幅度取值均被离散化,共分为
10级(0.1/0.2/.../0.9/1.0)和11级(设定一个取值范围后均匀采样); - 定义了策略(
policy)作为搜索空间的采样单元,每个策略包含了5个子策略(sub-policies),每个子策略包含了2个连续执行的图像转换,同时每个图像转换拥有两个超参数:应用该操作的概率和操作具体幅度值;
对于搜索空间而言,子策略的变换共有\((16\times 10\times 11)^{2}\)种,策略的变换共有\((16\times 10\times 11)^{10}\approx 2.9\times 10^{32}\)种可能排列。

RandAugment
RandAugment极大的缩减了搜索空间,大体做了如下两项调整:
调整一:每个转换的执行概率为均匀概率\(\frac{1}{K}\)。每个策略共采集\(N\)个转换,共有\(K^{N}\)种潜在策略;
调整二:和之前方法一致,通过线性尺度对增强强度进行量化。同时为了减小搜索空间,对每个策略中的所有转换执行单个全局操作强度\(M\)。
通过上述调整,RandAugment仅需两个超参数\(N\)和\(M\)即可控制整个搜索空间。其实现代码如下所示:

从上述实现中可以发现,\(N\)和\(M\)控制了正则化强度。\(N\)和\(M\)越大,表示转换空间越丰富,提高了正则化强度。
论文在实现中仅通过网格搜索就确定了这两个超参数的大小,并且在后续实验中超过或者持平之前所有的数据增强策略。
分析
独立搜索步骤存在系统性缺陷
独立训练阶段出现的核心假设:在小的代理任务上学习得到的增强策略可以应用到更大数据集上。在自动增强策略的开发中,这个前提确实成立,在小模型和小数据集上搜索得到的数据增强策略确实能够迁移到大模型和大数据集上。论文在这个假设的基础上进一步发展:代理任务生成的策略是不是最优的?换句话说,小代理任务是否是自动数据增强训练必须的?
论文将小代理任务拆分为两个维度:模型大小和数据集大小。使用CIFAR10作为测试数据集,训练了不同宽度的Wide-ResNet网络。对每个网络训练两种数据增强配置:一是基准数据增强(比如左右翻转和随机转换等等),二是RandAugment,\(K=14\),\(M=30\)(将转换强度均匀量化为30级,取值为\([0, 30]\),论文没说\(N\)大小)
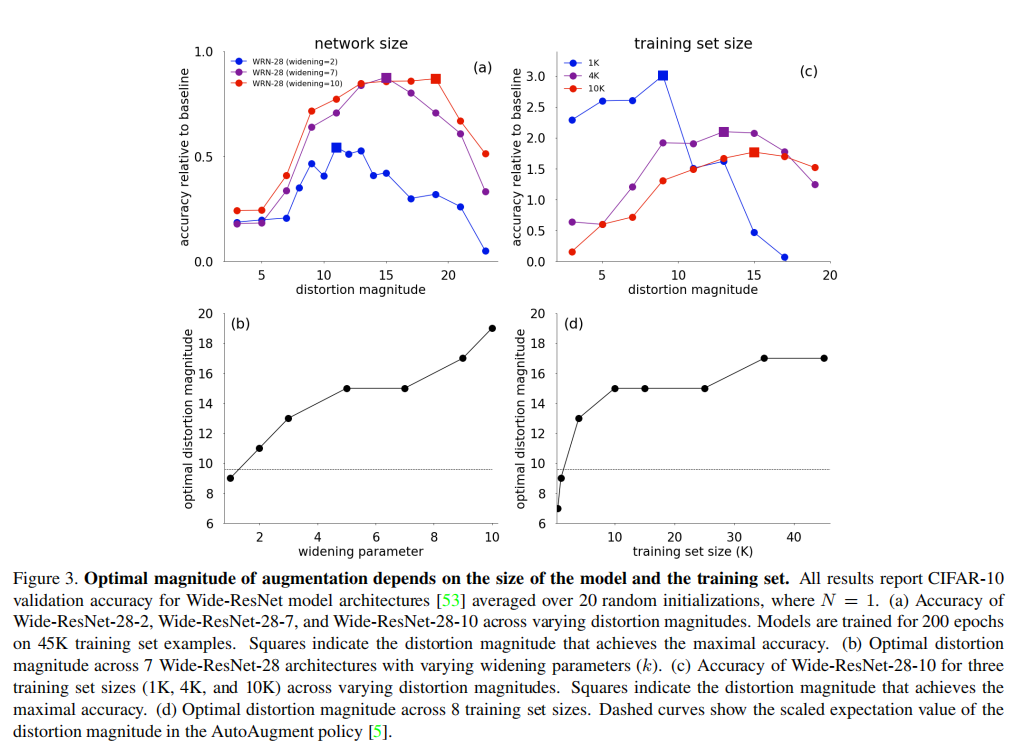
- 图3(a)记录了
3个不同宽度的Wide-ResNet在不同转换强度下的准确率; - 图3(b)记录了不同宽度的
Wide-ResNet在获取最好准确率的情况下所需的转换强度; - 图3(c)记录了
3个不同大小数据集的情况下Wide-ResNet-28-10在不同转换强度下的准确率; - 图3(d)记录了不同大小的数据集中获取最好准确率的情况下所需的转换强度。
从上述测试中可知,
- 在相同数据大小下,模型越大,需要更强的转换强度;
- 在相同模型配置下,数据集越大,需要更强的转换强度;
- 对超参数\(M\)使用网格搜索就可以获取得到非常高的准确率增益。
上述结论跟以往常识不相符,也就是更小的数据集才需要更大的数据增强来提高图像多样性。论文对这种反直觉行为给出的一个假设是,激进的数据增强会导致小数据集的低信噪比。
基础转换函数性能调研
在下面实验中可以发现RandAugment具有非常好的迁移性,不同任务和模型上均实现了最好的性能,所以RandAugment采集的转换函数对于数据集而言并不敏感。
论文同时调研了\(K=14\)转换中单个函数的依赖性,在CIFAR10上使用Wide-ResNet-28-2进行训练,随机从\(14\)种转换列表中进行采样。在训练过程中,移除了默认的翻转(flips)、填充裁剪(pad-and-crop)以及Cutout操作,仅关注于RandAugment +列表子集的训练效果。
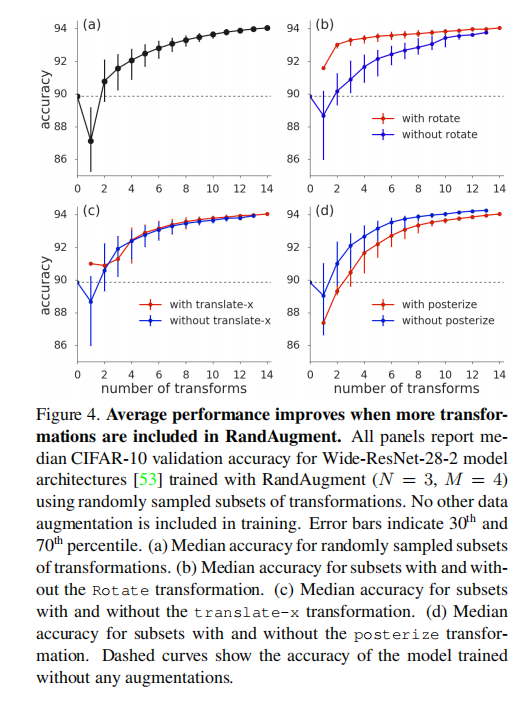
从图4(a)的训练结果可知,仅需2个基础转换的RandAugment训练即可获取超过1%的性能增益。
论文同时调研了单个转换对于训练的影响。将单个转换加入随机采集的子集进行训练,计算平均的验证精度,如下表所示
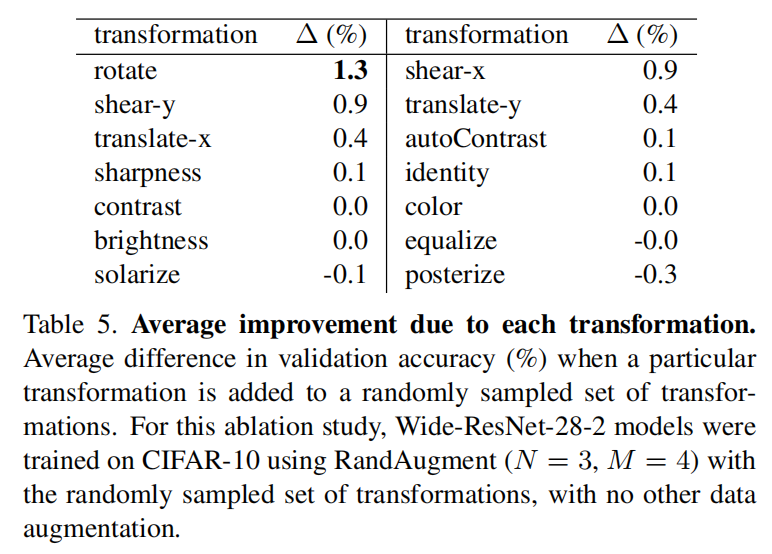
- 几何转换之间的性能增益差别最大;
- 一些颜色转换会导致平均精度退化;
rotate转换最有效果。
论文额外研究了在子集中加入/不加入rotate/translate-x/posterize转换的效果,发现rotate可以提高所有子集的性能,而posterize几乎损害了所有子集的性能。
表5显示了随机采样子集中增加单个转换来计算平均精度,通过这种方式来评估单个转换的有效性,发现有些颜色转换导致了平均精度退化;但从图4(a)中可以发现同时使用所有转换会获取更好的性能。
选择图像变换的概率学习
在RandAugment的默认设置中,每个转换的采样概率为均匀概率\(\frac{1}{K}\)。论文调研了每个转换拥有单独采样概率的影响。
从实验结果来看,单个转换独立采样概率确实提高了性能。只不过这种方式会极大提高训练时间,后续可以进一步展开研究。
全局强度\(M\)采样调研
论文尝试了4种不同方式来采样强度\(M\),
- 在两个值之间均匀随机采样;
- 在整个训练过程中使用常量强度;
- 在两个值之间线性增加强度;
- 随机采样,同时采样上线随训练过程增加。
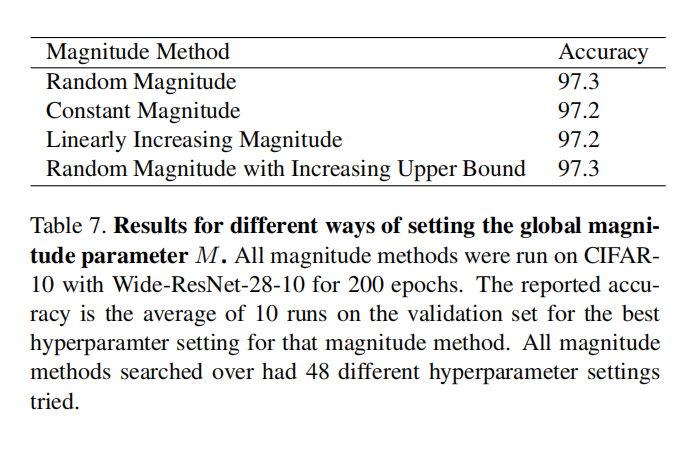
从训练结果来看,4种采样方式均能实现相近的准确率。为了缩减搜索空间,论文最终选择了全局固定常量\(M\)的方式。
独立强度\(M\)采样调研
论文也调研了固定其他转换的执行强度不变,仅改变单个转换的强度的条件下训练的性能。
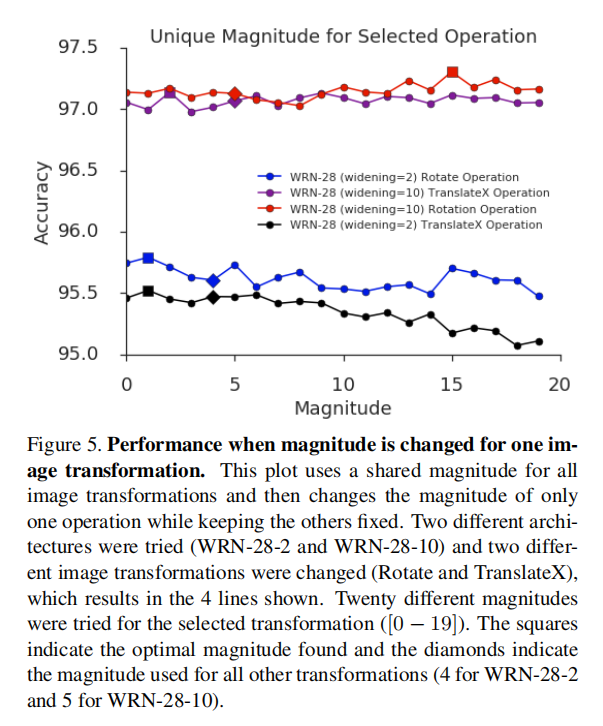
从训练结果来看,单独转换的强度调整对于最终精度的差异性非常小。
实验
CIFAR
训练设置:
Wide-ResNet- 轮数:
200 - 学习率:
0.1 - 批量:
128 - 权重衰减:
5e-4 - 学习率调度:余弦衰减
- 轮数:
Shake-Shake- 轮数:
1800 - 学习率:
0.01 - 批量:
128 - 权重衰减:
1e-3 - 学习率调度:余弦衰减
- 轮数:
ShakeDrop- 轮数:
1800 - 学习率:
0.05 - 批量:
64 - 权重衰减:
5e-5 - 学习率调度:余弦衰减
- 轮数:
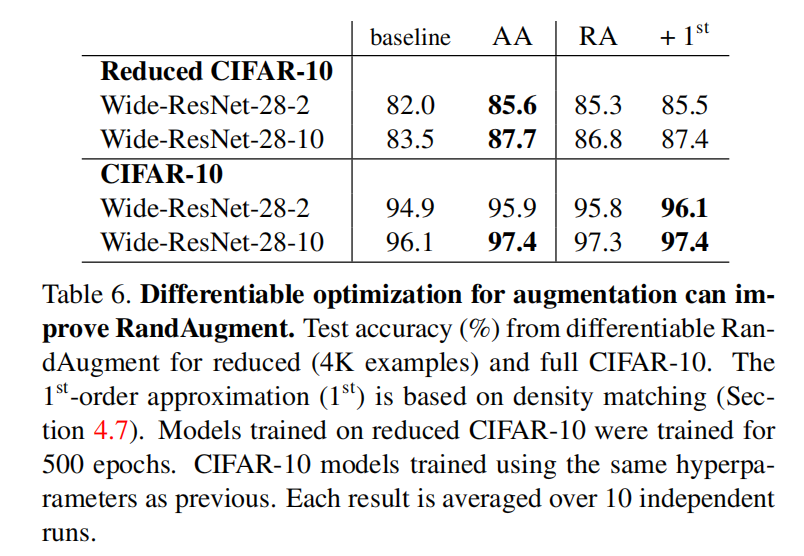
对于CIFAR10数据集,固定设置\(N=3\),网格搜索了\(M = [4, 5, 7, 9, 11]\)。
- 对于
Wide-ResNet-2,最好的结构是\(M=4\) - 对于
Wide-ResNet-10,最好的结构是\(M=5\); - 对于
Shake-Shake(26 2x96d),最好的结构是\(M=9\); - 对于
PyramidNet + ShakeDrop,最好的结构是\(M=7\)。
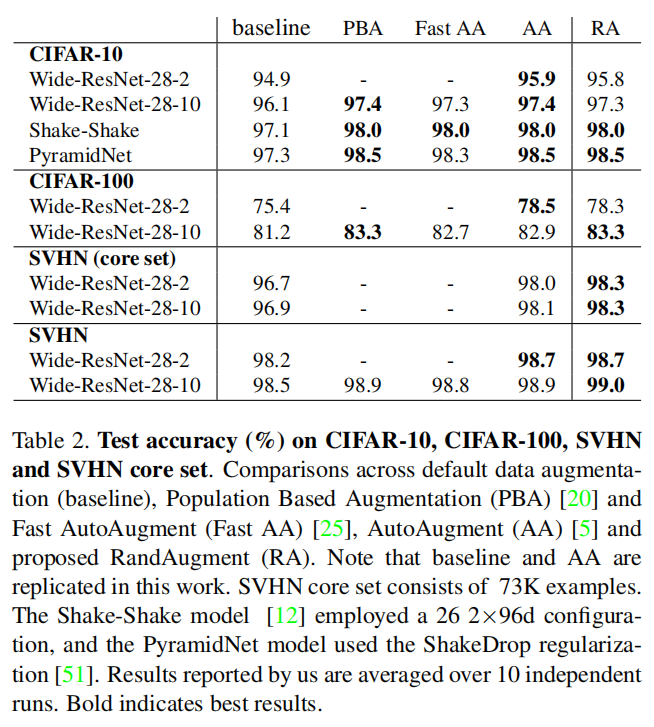
CIFAR10
在CIFAR-10数据集测试中,\(N\)和\(M\)分别采样了1个和5个样本,根据验证集(从训练集采集的5K数据)准确率中确定最优结果。从上图显示RandAugment在4种不同网络架构中实现了接近最好(在0.1%之内)或者最好的结果。
CIFAR100
论文在CIFAR100数据集中测试了Wide-ResNet-28-2和Wide-ResNet-28-10,基于5K验证集,网格搜索了2个\(N\)值(\(N={1, 2}\))和\(4\)个\(M\)值(\(M={2, 6, 10, 14}\))。
对于Wide-ResNet-28-2,最好的配置是\(N=1, M=2\);对于Wide-ResNet-28-10,最好的配置是\(N=2, M=14\)。
SVHN
SVHN包含了73K训练集图像(核心数据集), 另外还提供了531K额外扩充图像(扩充数据集)。论文在SVHN数据集中比较了Wide-ResNet-28-2和Wide-ResNet-28-10在包含/不包含额外扩充数据情况下使用RandAugment的性能。
- 对于
Wide-ResNet-28-2,仅使用核心数据集训练的结果比添加了扩充数据集的结果更好(98.3% vs. 98.2%); - 对于
Wide-ResNet-28-10,仅使用核心数据集训练的结果和添加了扩充数据集的结果相当(差距在0.2%以内); Wide-ResNet-28-10 + RandAugment的训练结果超越了之前在SVHN上最好的结果。
训练设置
- 在两种
SVHN数据集上,均在RandAugment之后应用了Cutout操作; - 模型:
Wide-ResNet-28-2和Wide-ResNet-28-10 Core SVHN- 学习率:
5e-3 - 权重衰减:
5e-3 - 轮数:
200 - 学习率调度:余弦衰减
- 固定\(N=3\)
- 网格搜索\(M=[5, 7, 9, 11]\)
- 学习率:
Full SVHN- 学习率:
5e-3 - 权重衰减:
1e-3 - 轮数:
160 - 学习率调度:余弦衰减
- 固定\(N=3\)
- 网格搜索\(M=[5, 7, 9, 11]\)
- 学习率:
在Core SVHN数据集上,对于Wide-ResNet-28-2和Wide-ResNet-28-10,最好的强度均为\(M=9\);在Full SVHN数据集上,对于Wide-ResNet-28-2而言,最好的强度是\(M=5\),对于Wide-ResNet-28-10而言,最好的强度是\(M=7\)。
ImageNet
之前的自动增强策略在小代理任务上获得了非常好的性能增益,但是迁移到更大数据集(比如ImageNet,特别是应用于更大模型)上时并没有体现出很好的效果。比如AutoAugment在ImageNet上(+0.4% for AmoebaNet-C and +0.1% for EfficientNet-B5)。论文给出的一个解释是可能是因为小代理任务的类别数太少了,相对于ImageNet 1000类而言。

- 在小模型上(
ResNet),RandAugment的性能和AutoAugment/Fast AutoAugment相当; - 在大模型上,相对于基准增强策略最高有
1.3%的增益。对于EfficientNet-B7,实现了最好的85%准确率。
训练设置:
ResNet- 轮数:
180 - 图像大小:
224x224 - 权重衰减:
1e-4 - 动量:
0.9 - 学习率:
0.1,以256为基数进行缩放 - 全局批量大小:
4096,使用32个workers - 网格搜索\(N=[1, 2, 3]\)
- 网格搜索\(M=[5, 7, 9, 11, 13, 15]\)
- 轮数:
EfficientNet- 轮数:
350 - 批量大小:
4096,使用256个workers - 学习率:
0.016,以256为基数进行缩放 - 优化器:
RMSProp,动量0.9,\(\epsilon=0.001\),衰减0.9 - 权重衰减:
1e-5 - 对于
EfficientNet-B5- 图像大小为
456x456 - 网格搜索\(N=[1, 2, 3]\)
- 网格搜索\(M=[8, 11, 14, 17, 21]\)
- 图像大小为
- 对于
EfficietNet-B7- 图像大小为
600x600 - 网格搜索\(N=[1, 2, 3]\)
- 网格搜索\(M=[17, 25, 28, 31]\)
- 图像大小为
- 在
RandAugment之前应用默认的水平翻转(horizontal flipping)和随机裁剪(random crops)
- 轮数:
对于ResNet-50而言,最好的RandAugment超参数配置是\(N=2, M=9\);对于EfficientNet-B5而言,\(N=2/3, M=17\);对于EfficientNet-B7而言,\(N=2, M=28\)
COCO
使用RetinaNet,以ResNet-101和ResNet-200作为Backbone。训练结果如下:
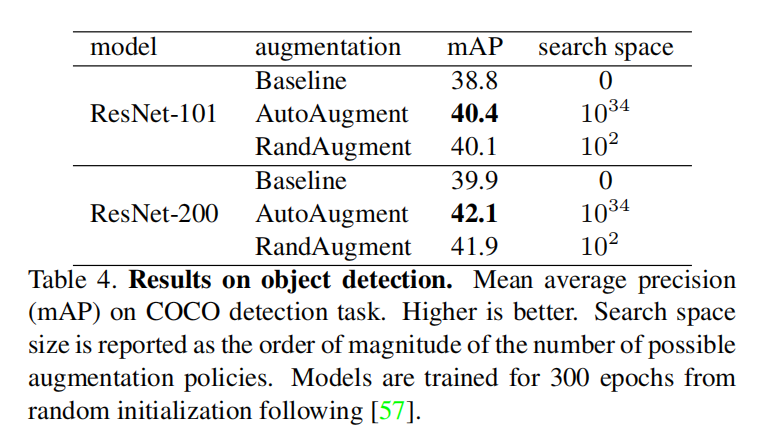
从上表中,RandAugment相对于基准增强策略提供了mAP,而AutoAugment实现了最好的效果。不过AutoAugment需要以下两个条件:
AutoAugment添加了额外针对图像定位边界框进行增强的转换;AutoAugment花费了大约15K GPU小时用于搜索最佳策略。
小结
RandAugment提供了在大数据集上进行数据增强搜索的可能性,目前它仅需网格搜索即可获取最好的性能。
论文重点:
- 数据增强的最佳强度依赖于模型大小和训练集大小,所以在小代理数据集上进行增强策略的搜索是次优的方法;
- 创建了一个极度简化的搜索空间,仅包含
2个超参数(每个策略采样个数\(N\)和策略中每个转换执行强度\(M\))。可以使用简单的网格搜索为模型和数据集定制增强策略,不再需要独立的搜索步骤; - 通过
RandAugment的使用,在目标分类和目标检测任务中实现了最好的增强效果。
未来的研究方向:
- 在能够保证有限的训练资源和时间的情况下,如何释放更多参数的训练以提高性能;
- 如何根据给定的任务定制转换集(不仅仅是
PIL提供的转换函数),以进一步提高给定模型的预测性能。