A Gift from Knowledge Distillation
原文地址:A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning
摘要
We introduce a novel technique for knowledge transfer, where knowledge from a pretrained deep neural network (DNN) is distilled and transferred to another DNN. As the DNN performs a mapping from the input space to the output space through many layers sequentially, we define the distilled knowledge to be transferred in terms of flow between layers, which is calculated by computing the inner product between features from two layers. When we compare the student DNN and the original network with the same size as the student DNN but trained without a teacher network, the proposed method of transferring the distilled knowledge as the flow between two layers exhibits three important phenomena: (1) the student DNN that learns the distilled knowledge is optimized much faster than the original model, (2) the student DNN outperforms the original DNN, and (3) the student DNN can learn the distilled knowledge from a teacher DNN that is trained at a different task, and the student DNN outperforms the original DNN that is trained from scratch.
我们介绍了一种新的知识迁移技术,其中来自深层神经网络(DNN)的预训练知识被提取并迁移到另一个DNN。由于DNN通过多个层依次执行从输入空间到输出空间的映射,我们依据层间流动的信息来提取蒸馏知识,通过计算两层特征之间的内积来得到。当我们比较学生DNN和与学生DNN大小相同但未经教师网络训练的原始网络时,所提出的将两层之间的流动特征作为迁移知识进行蒸馏并传输的方法表现了三个重要现象:(1)学习蒸馏知识的学生DNN比原始模型训练得更快,(2)学生DNN优于原始DNN,(3)学生DNN可以从在不同任务中训练的教师DNN那里学习蒸馏知识,并且学生DNN优于从零开始训练的原始DNN。
引言
知识迁移的关键在于迁移教师网络的什么特征给学生网络。论文依据现实生活中教师给学生讲授题目的场景,提出将两层之间的特征关系作为高维特征,对学生进行蒸馏训练。
Gramian矩阵:计算两个特征向量的内积,其包含了特征之间的方向性,可以作为图像的纹理信息。
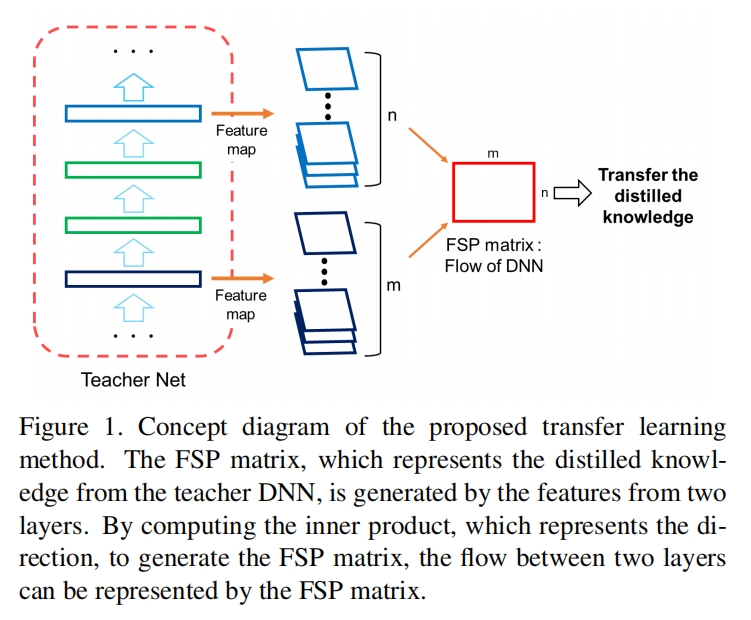
论文参考了Gramian矩阵的实现,对不同层提取的特征进行内积计算,得到the flow of solution procedure (FSP) matrix。
使用论文提出特征蒸馏算法能够实现以下优势:
- 快速优化。使用
FSP矩阵进行特征蒸馏后得到的学生网络初始化参数,能够帮助学生网络更快速的训练收敛; - 更高性能。经过论文提出的特征蒸馏算法训练过后的学生网络能够实现更高的性能;
- 迁移学习。教师网络可以在一个大数据集上进行训练,然后在一个小数据集上对学生网络进行性能迁移。
思路
论文把神经网络的计算过程比喻成现实中的教导过程:
- 将模型输入比喻成问题;
- 将模型输出比喻成答案;
- 将中间层计算特征比喻成解题过程中的中间结果。
比对之前的HT,其让学生网络的guided层去模拟教师网络的hint层,这种方式可以比喻成让学生简单的抄中间答案;相比之下,论文提出授人以鱼不如授人以渔,让学生学习整个解题流程,这样更有可能在遇到不同问题时得到更好的结果。
这种思路反映到算法中就是通过FSP矩阵计算不同层特征之间关系,学生网络模拟教师网络的FSP矩阵,以得到更好的初始化参数。
FSP矩阵
不同特征层之间的关系可以看成是两层特征之间的方向性。FSP矩阵计算公式如下:
\[ G_{i,j}(x;W) = \sum_{s=1}^{h}\sum_{t=1}^{w}\frac{F_{s,t,i}^{1}(x;W)\times F_{s,t,j}^{2}(x;W)}{h\times w} \]
- \(F^{1}\in R^{h\times w\times m}\)
- \(R^{2}\in R^{h\times w\times n}\)
- \(G\in R^{m\times n}\)
- \(x\)表示输入图像;
- \(W\)表示模型权重。
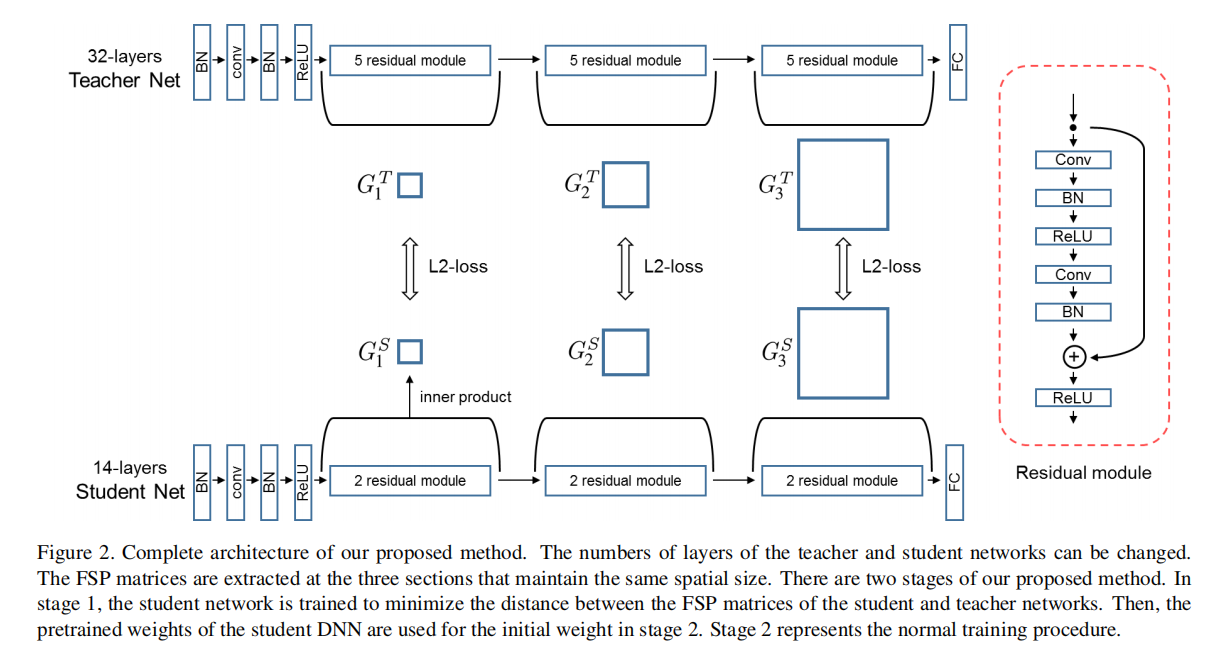
上图是蒸馏训练示意图。论文设计了两个残差网络(教师网络和学生网络),均包含了3个组(每个组包含了若干个残差块,同一组残差块输出的特征图大小相同)。
- 第一阶段:论文采集了每个组的输入输出特征图进行
FSP矩阵计算,共得到3个FSP矩阵。第一阶段的蒸馏训练就是最小化教师-学生网络之间对应的FSP矩阵大小; - 第二阶段:将第一阶段得到的学生网络参数作为初始化参数,然后进行学生网络的正常训练。
损失函数
假定教师网络生成了\(n\)个FSP矩阵\(G_{i}^{T}, i=1,...,n\),学生网络生成了\(n\)个FSP矩阵\(G_{i}^{S}, i=1,...,n\)。成对计算教师-学生网络中具有相同大小的FSP矩阵\((G_{i}^{T}, G_{i}^{S}), i=1,...,n\),使用\(L2\)范数作为每对矩阵的损失函数,整体损失函数定义如下:
\[ L_{FSP}(W_{t}, W_{s})=\frac{1}{N}\sum_{x}\sum_{i=1}^{n}\lambda_{i}\times \left \| (G_{i}^{T}(x; W_{t} - G_{i}^{S}(x;W_{s}))) \right \|_{2}^{2} \]
- \(\lambda_{i}\)表示每对
FSP矩阵的权重,在论文实验中采用的相同大小; - \(N\)表示成对数目。
实现流程
整体学习流程共分为两个阶段完成:
- 第一阶段训练就是最小化\(L_{FSP}\)损失函数,让学生网络的\(FSP\)矩阵尽可能的类似于教师网络;
- 第二阶段训练就是学生网络利用第一阶段训练得到的初始化参数,进行正常训练。

实验
论文设计了残差网络进行蒸馏训练:
- 使用每个
group中第一层和最后一层输出的特征图进行FSP矩阵计算; - 如果前后两层特征图大小不一致,那么就通过
max pooling方式保持大小一致;
论文实现了不同训练来验证不同目的:快速优化、更好性能和迁移学习。使用FitNets进行实验对照,其超参数设计如下:
- 第一阶段:基于
hint的训练- 使用
L2 loss作为基于hints训练的损失函数,共训练35000轮; - 使用教师-学生网络的中间层作为
hint和guided层; - 初始学习率设置为
1e-4,训练25000轮之后下降到1e-5;
- 使用
- 第二阶段:正常训练。保持和当前蒸馏算法一致的超参数
- 其蒸馏温度设置为\(3\);
- \(KD\)训练的超参数\(lambda\)值线性的从
4降到1。
快速优化
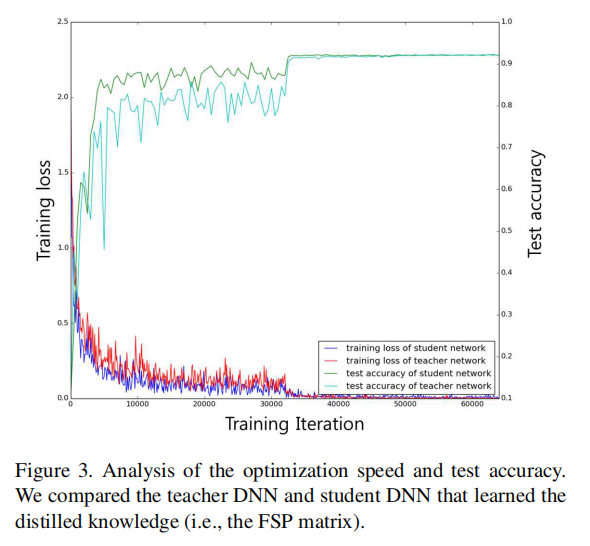
上图显示了基于CIFAR10数据集进行的教师网络(正常训练)和学生网络(第二阶段训练)的训练速度,可以发现学生网络可以更快的收敛和达到预期性能。
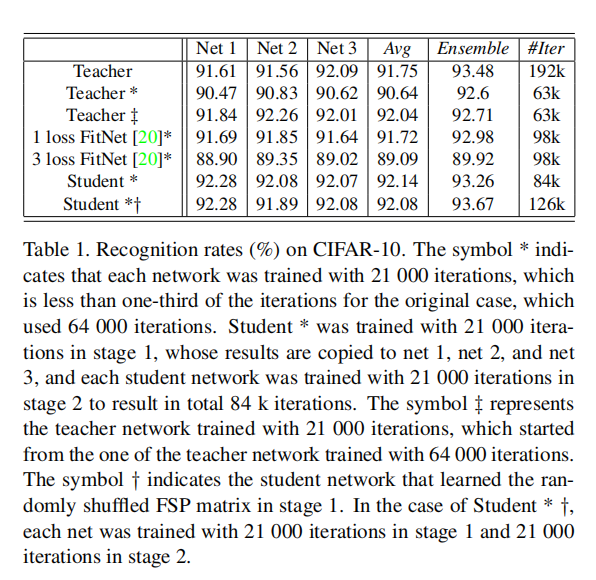
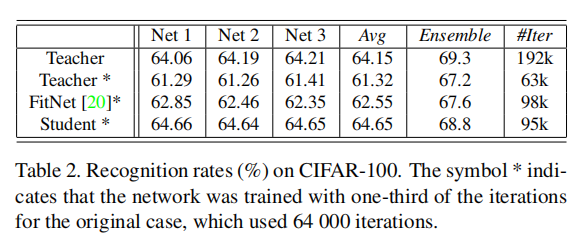
上表中给出了更详细的在CIFAR10数据集上的实验数据:
- 使用更短的时间训练教师网络(正常初始化训练)和学生网络(第二阶段训练),可以发现学生网络能够更快的收敛;
- 对比
1-loss FitNets(一个hints层)和3-loss FitNets(3个hints层),可以发现one-loss能够得到更好的效果;- 作者认为不考虑输入输出关系而只是简单的模拟输出结果,很难对网络进行训练;
- 直接复制同一份预训练参数,多个教师网络(
Net 1/Net 2/Net 3)的训练均能够在更短的时间内收敛,但是其集成结果并不理想,说明这样会增加了模型之间的相关性;
论文同样在CIFAR100上进行了实验,如下图所示,说明了FSP矩阵进行特征蒸馏的优异性
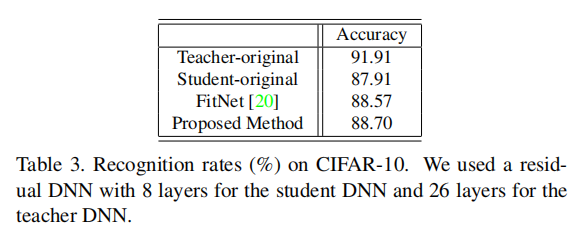
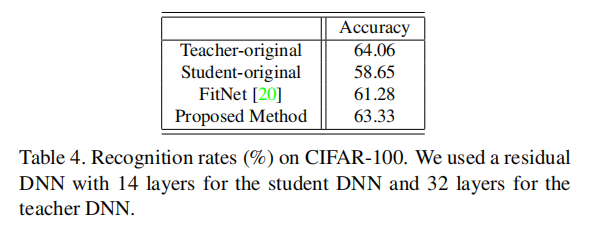
性能提升
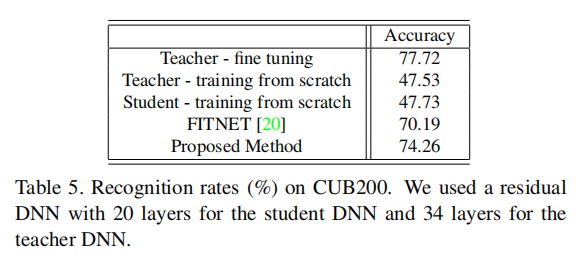
迁移学习
小结
本文和HT类似,都是两阶段的蒸馏训练,首先通过教师网络对学生网络的蒸馏得到一个很好的初始化参数,然后学生网络按照正常的方式进行训练能够更快速的收敛以及得到更高的性能。同时本文也验证了教师网络先在更大数据集上进行训练,然后在小数据集上对学生网络进行蒸馏训练的有效性。
进一步探索方向:
- 论文也没有给出超参数\(\lambda\)的取值啊?
- 论文没有给出在大数据集上进行预训练的学生网络的实验结果,包含以下场景:
- 大数据集训练学生网络,然后微调小数据集;
- 大数据集训练教师网络和学生网络,然后小数据集上蒸馏训练学生网络,最后小数据集训练学生网络;
- 通过迁移学习方式进行教师网络-学生网络蒸馏训练 vs. 同一数据集上进行教师网络-学生网络蒸馏训练。
- 对比当前常用的网络(
ResNet50/MobileNet),教师网络在CIFAR数据集上的训练精度太低了,有可能是因为目前从头开始训练,没有使用ImageNet预训练参数的缘故吧。