Temporal Relational Reasoning in Videos
原文地址:Temporal Relational Reasoning in Videos
复现地址:ZJCV/TRN
摘要
Temporal relational reasoning, the ability to link meaningful transformations of objects or entities over time, is a fundamental property of intelligent species. In this paper, we introduce an effective and interpretable network module, the Temporal Relation Network (TRN), designed to learn and reason about temporal dependencies between video frames at multiple time scales. We evaluate TRN-equipped networks on activity recognition tasks using three recent video datasets - Something-Something, Jester, and Charades - which fundamentally depend on temporal relational reasoning. Our results demonstrate that the proposed TRN gives convolutional neural networks a remarkable capacity to discover temporal relations in videos. Through only sparsely sampled video frames, TRN-equipped networks can accurately predict human-object interactions in the Something-Something dataset and identify various human gestures on the Jester dataset with very competitive performance. TRN-equipped networks also outperform two-stream networks and 3D convolution networks in recognizing daily activities in the Charades dataset. Further analyses show that the models learn intuitive and interpretable visual common sense knowledge in videos.
时间关系推理是智能物种的一个基本属性,它能够将对象或实体随时间而发生的有意义的变化联系起来。在本文中,我们介绍了一个有效的和可解释的网络模块,时间关系网络(TRN),旨在学习和推理视频帧之间在多个时间尺度上的时间依赖关系。我们使用三个最新的视频数据集(Something Something、Jester和Charades)评估插入TRN模块的网络在活动识别任务中的性能,这些数据集基本上依赖于时态关系推理。我们的结果表明,提出的TRN给卷积神经网络一个显著的能力用于发现视频中的时间关系。通过稀疏采样的视频帧,插入TRN模块的网络可以准确地预测Something-Something数据集中的人-物交互以及识别Jester数据集中的各种手势,具有很强的性能。在识别Charades数据集中的日常活动方面,插入TRN模块的网络也优于双流网络和3D卷积网络。进一步的分析表明,该模型在视频中可以学习到直观的、可解释的视觉常识知识。
什么是时间关系推理
时间关系推理(temporal relational reasoning):能够理解物体或者目标在不同时间下发生的变化,也就是说,能够根据过去时间发生的动作,推理出物体或目标的行为,进一步推理出后续将发生的事情。对于时间关系推理而言,时间和行为对应。
行为识别可分为两种模型:
- 基于时间关系推理:不可以打乱时间顺序。可区分为短时关系和长时关系(由多个短时关系组成)
- 基于外观以及行为:可以打乱时间顺序
对于依赖于时间关系推理的行为而言,打乱时间顺序后的视频片段(比如后几帧视频插入到前面来)会给出不一样的行为解释

上图中的4个行为依次是:
- 戳破罐子使其倒塌;
- 堆饼干;
- 整理衣柜;
- 竖起大拇指。
数据集分类
相应的数据集也可以分为两种:
- 基本上依赖于时间关系推理:
Something-Something/Jester/Charades - 仅仅依赖于动作和行为:
UCF101/Sport1M/THUMOS
短时关系和长时关系
简单的说,就是有些行为发生的时间很短,而有些行为发生的时间很长(一般长时关系都可以拆解成多个短时关系)。对于行为识别模型而言,输入的帧数有限(几帧到几十帧不等,更多帧的化对于模型大小以及运行时间都是一个挑战),有可能无法获取完整的长时关系信息。对于长时关系建模,可以通过稀疏采样的方式获取足够信息;而对于短时行为和长时行为识别,可以通过TRN模块进行不同时间尺度的关系建模
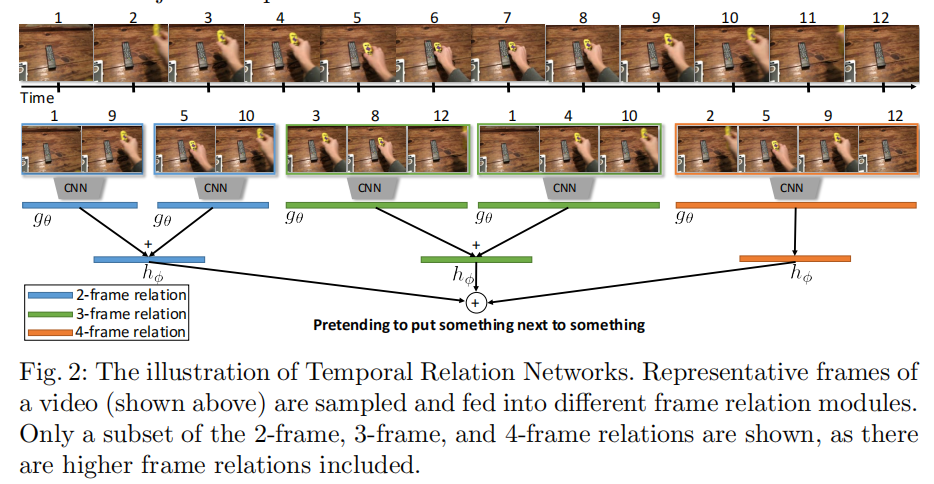
Temporal Relation Networks
TRN(temporal relation network)模块受A simple neural network module for relational reasoning启发,基于TSN,采集不同时间尺度的视频信息()
时间关系定义
\[ T_{2}(V) = h_{φ}(\sum_{i<j}g_{\theta}(f_{i}, f_{j})) \]
- \(V\)指的是大小为\(n\)的有序帧序列\(V={f_{1}, f_{2}, ..., f_{n}}\)
- \(f_{i}\)表示视频序列中的第\(i\)帧
- \(h_{φ}\)和\(g_{\theta}\)表示特征提取函数
在实际运行过程中,使用多层感知器(multilayer perceptions,MLP,就是神经网络)计算逐对帧之间的关系;同时为了简化计算,会均匀采样成队的\(i\)和\(j\)
上面描述的是两帧时间关系定义,下面扩展到三帧时间关系定义
\[ T_{3}(V) = h_{φ}^{'}(\sum_{i<j<k}g_{\theta}^{'}(f_{i}, f_{j}, f_{k})) \]
多尺度时间关系
通过捕获多个时间尺度下的时间关系,以此来建模长时和短时关系
\[ MT_{N}(V) = T_{2}(V) + T_{3}(V) ... + T_{N}(V) \]
- \(T_{d}\)捕获了\(d\)张有序帧之间的时间关系
- 每个\(T_{d}\)均有自个的\(h_{φ}\)和\(g_{\theta}\)(也就是说,使用独立的神经网络计算
2帧/3帧/.../N帧关系)