Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding
摘要
Neural networks are both computationally intensive and memory intensive, making them difficult to deploy on embedded systems with limited hardware resources. To address this limitation, we introduce "deep compression", a three stage pipeline: pruning, trained quantization and Huffman coding, that work together to reduce the storage requirement of neural networks by 35x to 49x without affecting their accuracy. Our method first prunes the network by learning only the important connections. Next, we quantize the weights to enforce weight sharing, finally, we apply Huffman coding. After the first two steps we retrain the network to fine tune the remaining connections and the quantized centroids. Pruning, reduces the number of connections by 9x to 13x; Quantization then reduces the number of bits that represent each connection from 32 to 5. On the ImageNet dataset, our method reduced the storage required by AlexNet by 35x, from 240MB to 6.9MB, without loss of accuracy. Our method reduced the size of VGG-16 by 49x from 552MB to 11.3MB, again with no loss of accuracy. This allows fitting the model into on-chip SRAM cache rather than off-chip DRAM memory. Our compression method also facilitates the use of complex neural networks in mobile applications where application size and download bandwidth are constrained. Benchmarked on CPU, GPU and mobile GPU, compressed network has 3x to 4x layerwise speedup and 3x to 7x better energy efficiency.
神经网络是计算密集型和内存密集型,因此很难在硬件资源有限的嵌入式系统上部署。为了解决这一限制,我们引入了“深度压缩”,这是一个三阶段流水线:剪枝、训练量化和霍夫曼编码,通过深度压缩技术可以将神经网络的存储需求降低35倍至49倍,而不影响其准确性。我们的方法首先通过只学习重要的连接来修剪网络。接下来,我们对权重进行量化以实现权重共享,最后,我们应用霍夫曼编码。完成前两步后,我们会重新训练网络以微调剩余的连接和量化质心。剪枝将连接个数减少9x到13x;然后量化将每个连接的存储位数从32位减少到5位。在ImageNet数据集上,我们的方法将AlexNet所需的存储量减少了35倍,从240兆字节减少到6.9兆字节,并且不损失准确性。我们的方法将VGG-16网络的大小从552兆字节减少到11.3兆字节,减少了49倍,同样没有损失精度。这使得该模型能够保存在芯片内部的静态随机存取存储器高速缓存(SRAM),而不是芯片外部的动态随机存取存储器(DRAM)。我们的压缩方法促进了在应用程序大小和下载带宽受限的移动应用程序中使用复杂的神经网络。以中央处理器(CPU)、图形处理器(GPU)和移动图形处理器为基准,压缩网络的速度提高了3到4倍,能效提高了3到7倍。
必要性
在移动设备上应用深度神经网络模型存在以下约束:
- 应用商店普遍对于应用大小有约束,过大的深度模型不利于应用的发布;
- 能耗主要由内存访问决定。论文给出了一个报告:
- 在
45nm CMOS技术下,32位浮点加法耗费0.9pJ,32位SRAM缓存访问耗费5pJ,32位DRAM内存访问耗费640pJ,其是加法运算耗费能源的3个数量级,所以片外磁盘数据访问占据了最多的能量消耗; - 运行一个
10亿连接的神经网络,以20fps频率实现,1秒内的DRAM访问就需要(20Hz)(1G)(640pJ)=12.8W。
- 在
所以大模型约束了深度神经网络在移动端的推广,缩小网络大小是一个非常实际的需求。
深度压缩
简介
深度压缩技术是一个3阶段pipeline,如下图所示
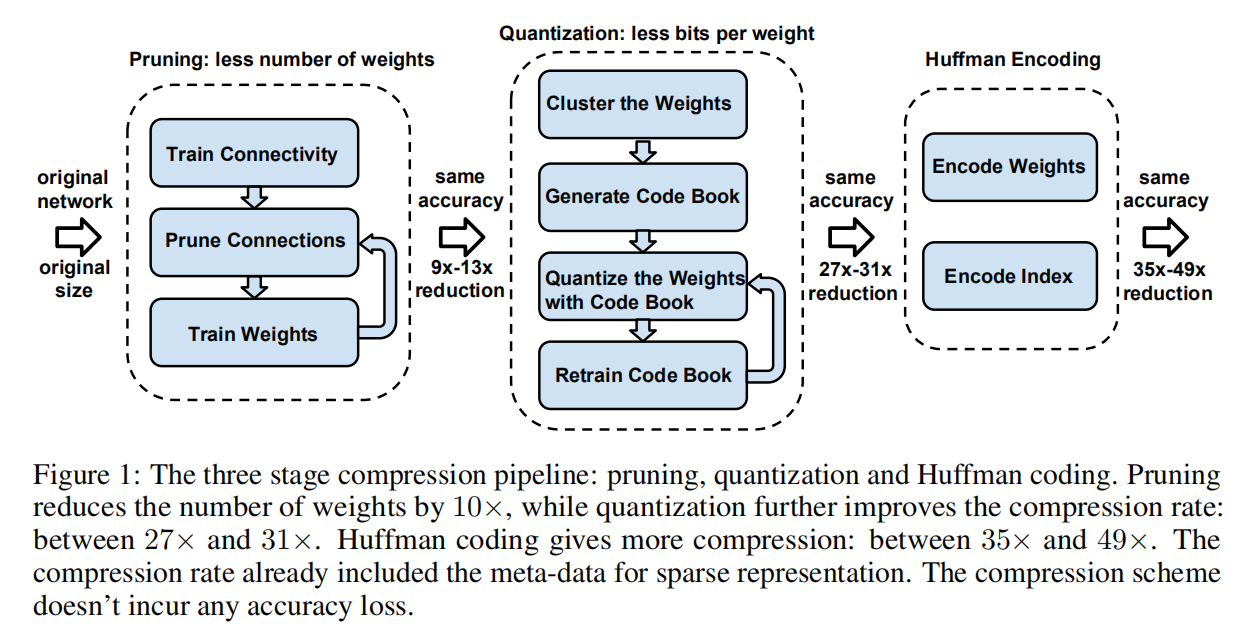
- 第一步:剪枝训练,移除冗余连接;
- 第二步:量化训练,对权重进行量化,对多个连接执行权重共享,通过训练恢复模型精度;
- 第三步:应用霍夫曼编码进一步压缩存储空间。
网络剪枝
应用3阶段剪枝算法进行网络剪枝操作:
- 首先进行正常的网络训练;
- 然后修剪不重要的剪枝;
- 最后重训练稀疏模型以恢复损失精度。
论文还进一步描述了存储稀疏矩阵的方式:通过压缩稀疏行(CSR)或者压缩稀疏列(CSC)模式提高压缩率,仅需
其实现如下图所示,具体描述参考相关阅读

另外,论文还提出通过相对坐标差而不是绝对位置(每行或者每列)来进一步压缩坐标的存储位数(卷积层仅需8位,全连接层仅需5位)。示例如下图所示
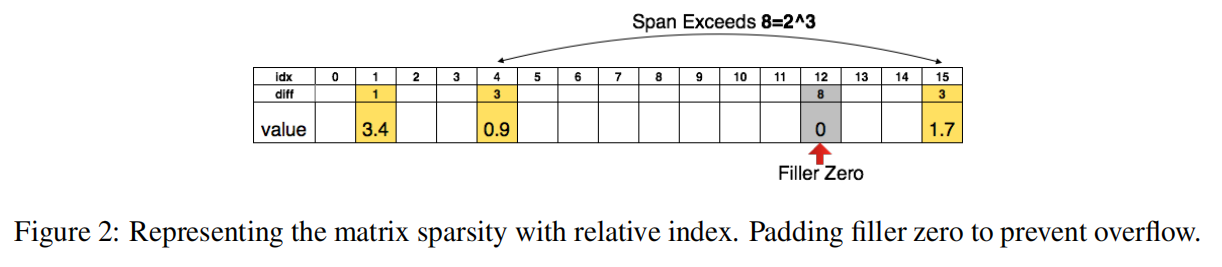
上图中假定最大存储位数是3位,那么其相对坐标差最大值为8,如果两个非0参数之间的坐标差超过了8,那么在中间插入一个填充值以防止数值溢出
训练量化
训练量化算法实现流程如下:
- 通过聚类算法量化每层网络的权重,处于同一簇的参数共享同一个大小;
- 重训练阶段,求和同一簇参数计算得到的梯度,对质心进行梯度下降训练。
权重共享
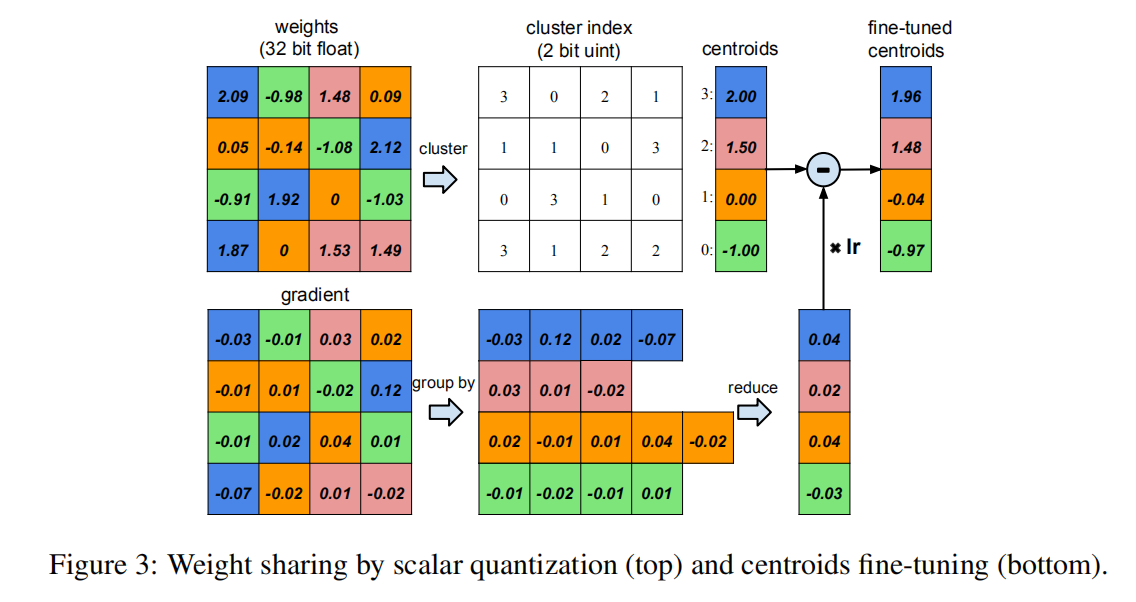
- 假定当前层有
4个输入神经元和4个输出神经元,所以其矩阵大小为 - 将权重量化到
4个区间(用4种颜色表示),在同一个区间内的参数共享同一个权重,如中上角所示; - 在训练阶段
- 不同位置参数计算得到不同大小的梯度,如左下角所示;
- 将处于同一簇的权重梯度进行求和,如中下角所示;
- 仅需对每个区间的质心进行梯度下降运算即可,如右图所示。
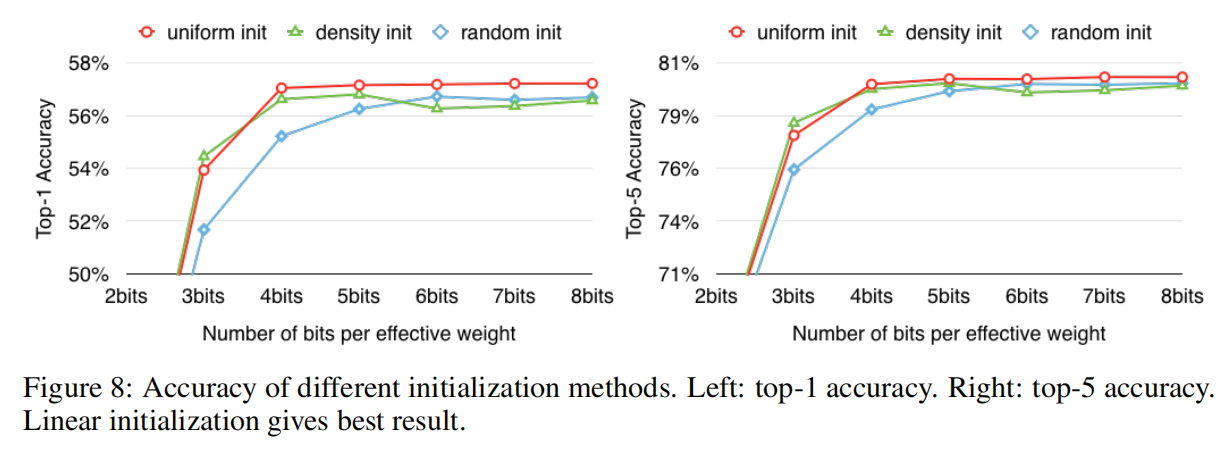
质心初始化
论文通过聚类算法将同层权重分类为3种初始化方式,如下图所示:
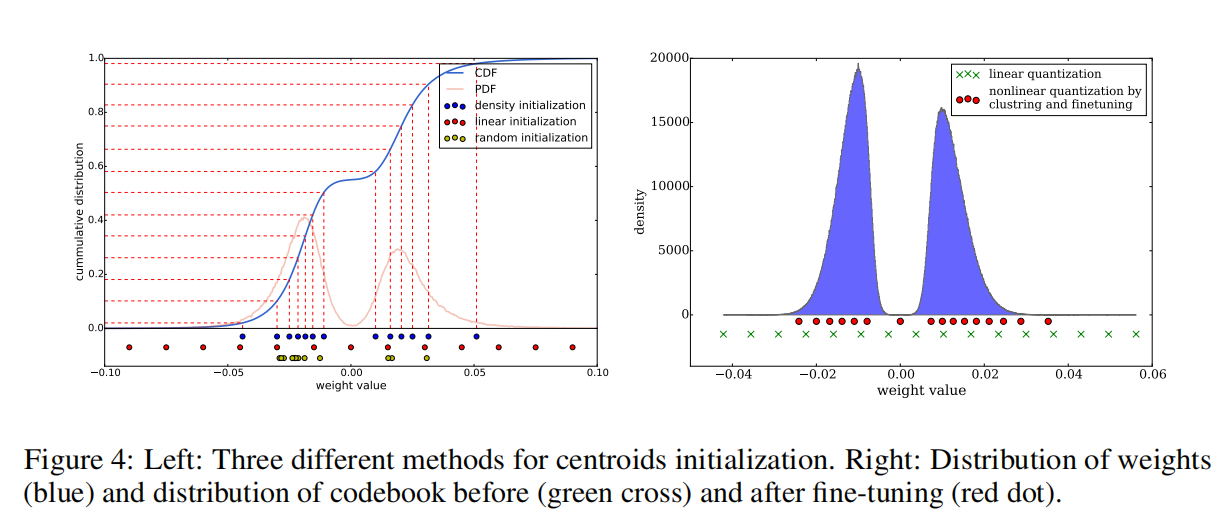
CDF表示权值的累积统计;PDF表示权值的直方图统计,在上图呈现双峰分布。
- 随机初始化。从参数矩阵中随机选择
- 基于密度初始化。在y轴上线性地分隔CDF,然后找到与CDF的水平交点,最后找到x轴上的垂直交点,该交点成为质心,如上图蓝点所示。这种方法使两个峰周围的质心更密集,但比随机初始化方法更分散;
- 线性初始化。对原始权重的
[最小值,最大值]进行线性等分。这种初始化方法不依赖于权重的统计分布,与前两种方法相比是最分散的。
基于论文Learning both Weights and Connections for Efficient Neural Networks的观察,权重值越大表示该权重拥有更大的作用。使用随机初始化方法和基于密度初始化方法得到的初始质心的大小并不如线性初始化方法,理论上其聚类效果会不如线性初始化方法。通过实现也证明了这一点,如下图所示
量化压缩率
给定
对于上图中共有
霍夫曼编码
霍夫曼编码是常用的数据压缩算法。论文以AlexNet为例,其剪枝训练和量化训练后权重和下标分布如下图所示
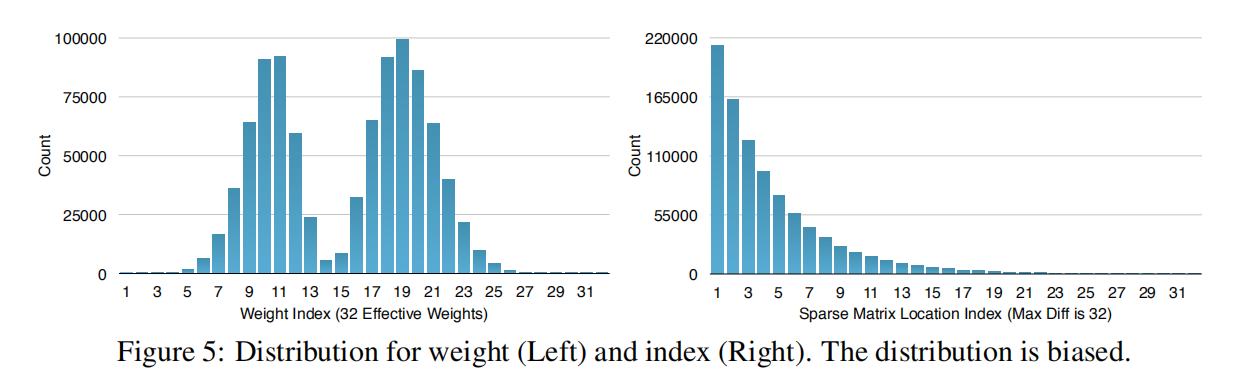
- 量化权重呈现双峰分布;
- 稀疏矩阵下标差大部分在
20以内;
通过霍夫曼编码,能够在节约20%-30%的存储空间。
实验
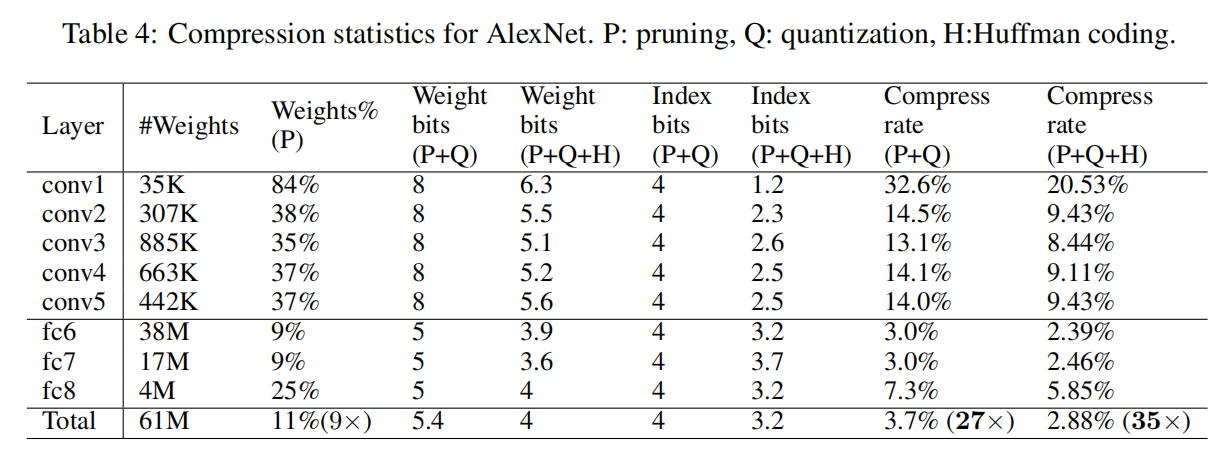
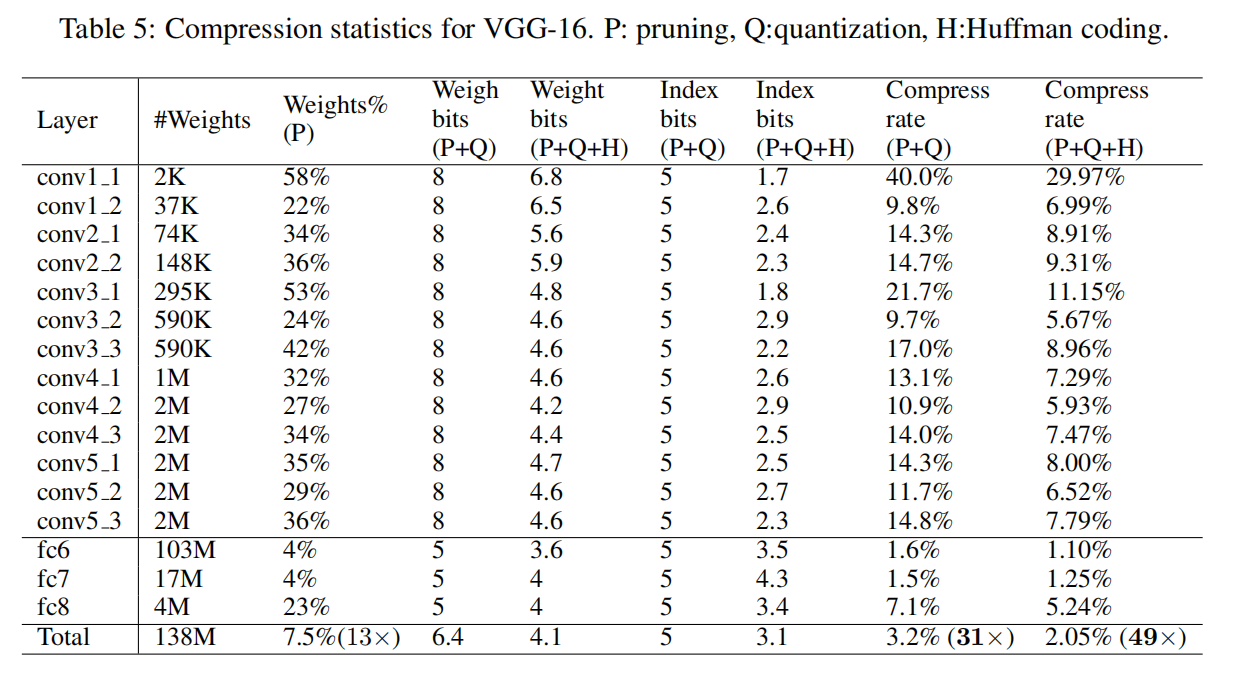
AlexNet/VGGNet-16
在ImageNet数据集上,AlexNet能够实现35倍的压缩率,VGGNet-16能够实现49倍的压缩率
剪枝/量化
论文研究了分开进行剪枝操作和训练量化操作的结果,如下图所示
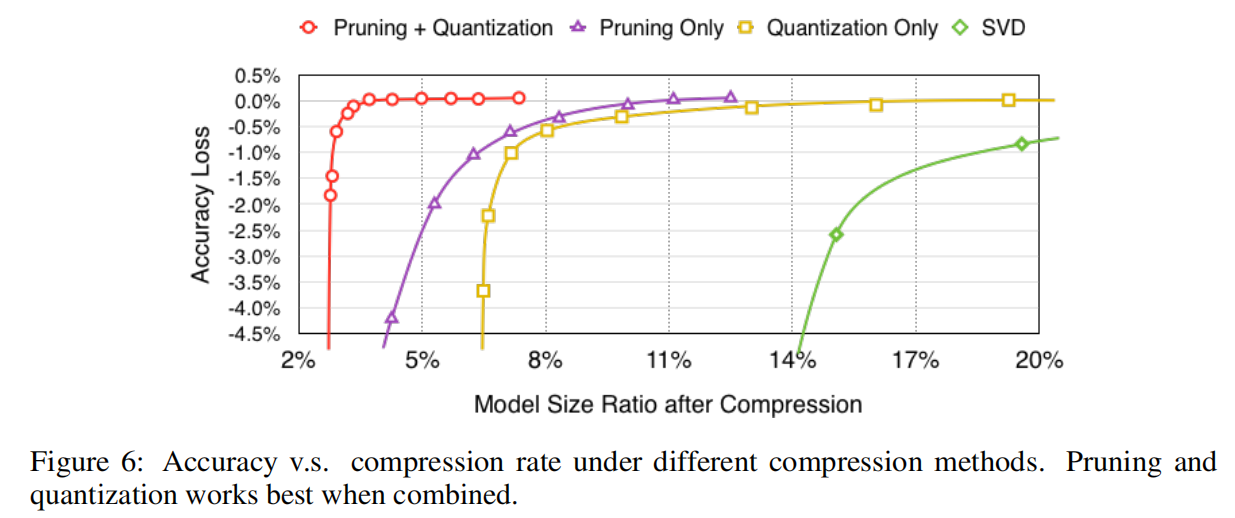
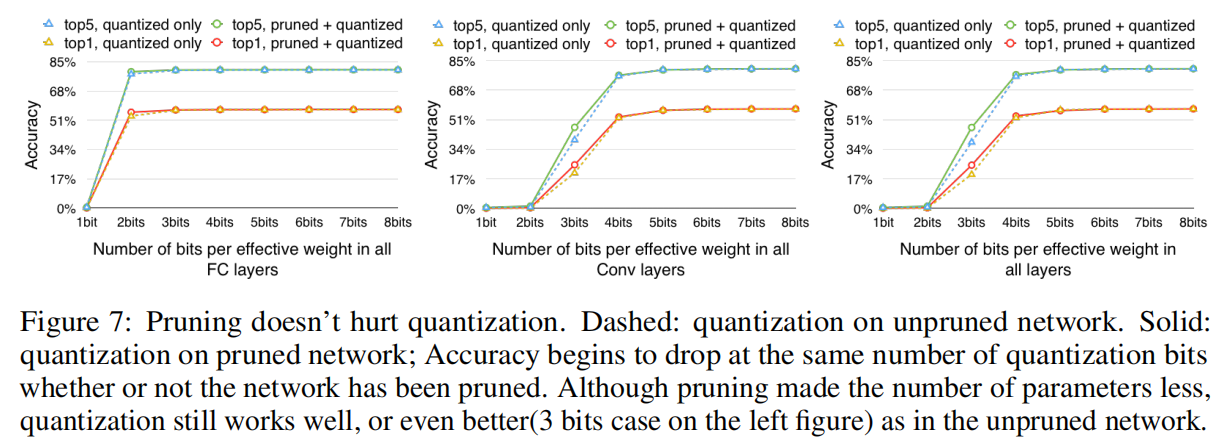
从实验结果可知,剪枝训练和量化训练能够相互促进,得到更好的压缩率。论文给出的一个观点是未剪枝训练的冗余参数过多,不利于量化时聚类算法的质心计算;而剪枝后模型的参数空间变小,能够得到更小的量化误差,从而实现更好的压缩率。
速度/能源
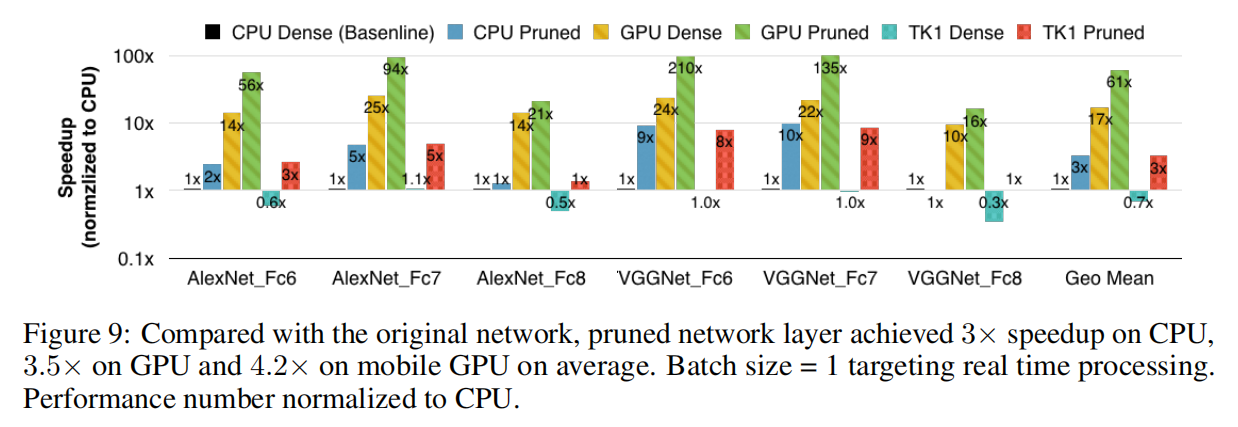
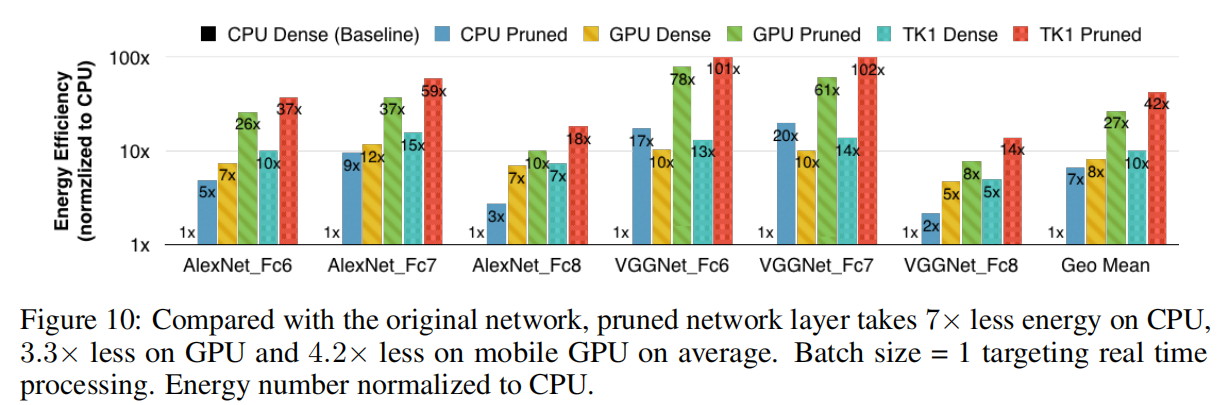
论文在CPU、GPU和移动端GPU上实验了剪枝层的速度和耗费能源。从实验结果可知,剪枝算法确实能够有效加速运算以及减少能源消耗。
小结
韩松博士在之前提出了3阶段训练的剪枝算法,这一次,他在剪枝算法的基础上进一步实现了训练量化算法和霍夫曼编码,综合三种技术实现了新的3阶段深度压缩流程,达到了更高的压缩率,允许深度网络在嵌入式应用上拥有更低的存储空间和能源消耗,同时提高了运算速度。
论文最大的贡献在于结合剪枝算法和训练量化算法,两者在实验中互不影响,综合这两种算法能够达到更高的压缩率。
Gitalk 加载中 ...