SSD: Single Shot MultiBox Detector
原文地址:SSD: Single Shot MultiBox Detector
摘要
We present a method for detecting objects in images using a single deep neural network. Our approach, named SSD, discretizes the output space of bounding boxes into a set of default boxes over different aspect ratios and scales per feature map location. At prediction time, the network generates scores for the presence of each object category in each default box and produces adjustments to the box to better match the object shape. Additionally, the network combines predictions from multiple feature maps with different resolutions to naturally handle objects of various sizes. SSD is simple relative to methods that require object proposals because it completely eliminates proposal generation and subsequent pixel or feature resampling stages and encapsulates all computation in a single network. This makes SSD easy to train and straightforward to integrate into systems that require a detection component. Experimental results on the PASCAL VOC, COCO, and ILSVRC datasets confirm that SSD has competitive accuracy to methods that utilize an additional object proposal step and is much faster, while providing a unified framework for both training and inference. For 300 × 300 input, SSD achieves 74.3% mAP\(^{1}\) on VOC2007 test at 59 FPS on a Nvidia Titan X and for 512 × 512 input, SSD achieves 76.9% mAP, outperforming a comparable state-of-the-art Faster R-CNN model. Compared to other single stage methods, SSD has much better accuracy even with a smaller input image size. Code is available at: https://github.com/weiliu89/caffe/tree/ssd .
我们提出了一种利用单个深层神经网络检测图像中目标的方法。我们的方法名为SSD,将边界框的输出空间离散化为一组默认框,这些默认框具有不同的长宽比和基于不同特征图的比例。在预测时,网络为每个默认框中每个目标类别的存在生成分数,并对框进行调整以更好地匹配目标形状。此外,该网络将来自不同分辨率的多个特征图的预测结合起来,以更好地处理各种大小的目标。SSD相对于需要目标建议的方法来说是简单的,因为它完全消除了建议生成和随后的像素或特征重采样阶段,并将所有计算封装在单个网络中。这使得SSD易于训练,并可直接集成到需要检测组件的系统中。在PASCAL VOC、COCO和ILSVRC数据集上的实验结果证实,SSD与利用额外的目标建议步骤的方法相比有更高的准确性,并且速度快得多,同时为训练和推理提供了统一的框架。对于300 × 300输入,SSD在Nvidia Titan X上以59 FPS的速度在VOC2007测试中实现了74.3%的mAP\(^{1}\),对于512 × 512输入,SSD实现了76.9%的mAP,优于同等水平Faster R-CNN模型。与其他单阶段训练方法相比,SSD即使在较小的输入图像尺寸下也具有更高的精度。代码地址:https://github.com/weiliu89/caffe/tree/ssd
\(^{`}\) We achieved even better results using an improved data augmentation scheme in follow-on experiments: 77.2% mAP for 300×300 input and 79.8% mAP for 512×512 input on VOC2007. Please see Sec. 3.6 for details
\(^{1}\) 在后续实验中,我们使用改进的数据扩充方案获得了更好的结果:在2007 VOC数据集中,300×300输入下得到77.2% mAP以及512×512输入下得到79.8% mAP。详情请见3.6小节
算法实现
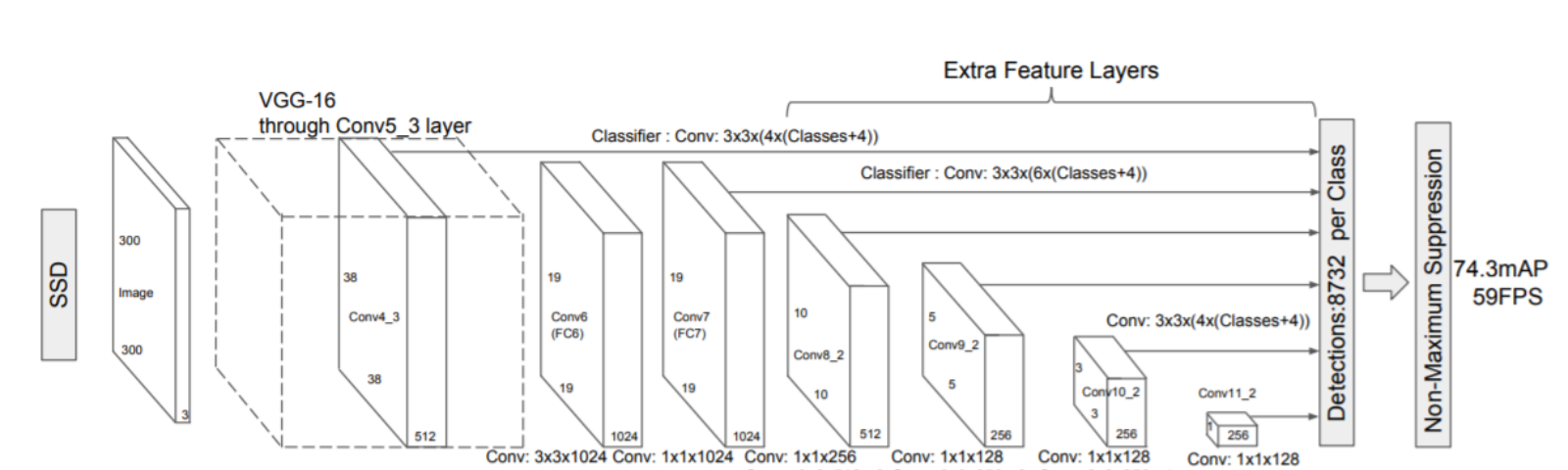
- 使用同一个基础网络,提取多个不同分辨率的特征图,为预测和分类提供特征
- 设置先验框:在每个特征图的每个
cell上设置一组不同尺度、不同长宽比的先验框 - 将多个特征图输入后续模型,计算得到预测的回归目标\(t\)、类别以及分类概率(通过卷积滤波器实现)
- 训练阶段:
- 结合每个图像的标注框,计算回归目标\(t_{*}\)以及对应类别
- 计算分类损失(
Softmax Loss)和定位损失(Smooth L1 Loss) - 梯度更新和学习率调度
- 测试阶段:
- 结合先验框和回归目标\(t\),计算真正的预测边界框
NMS处理,过滤各类别的重叠预测框- 分类概率过滤,去除小于分类概率阈值的预测框
- 取前几个预测框作为最后的结果
算法贡献
- 提出了
SSD(single-shot detector),比之前的YOLO更快,达到Faster R-CNN的检测精度 SSD在特征图上执行卷积操作,在一组固定的候选框上预测得到类别成绩和边界框坐标- 为了获得高检测精度,
SSD从不同比例的特征图中产生不同比例的预测,并通过纵横比明确地分离预测 - 这些设计特点带来了简单的端到端训练和高精度,即使是在低分辨率输入图像上,进一步提高了速度与精度的权衡
- 实验包括对不同输入大小的模型进行时间和精度分析,并与一系列最新的方法进行比较
PyTorch实现
参考:object-detection-algorithm/SSD
实现技巧分析
SSD算法使用了多个实现技巧, 包括
- 数据扩充
- 添加不同长宽比的先验框
- 使用扩张卷积(
atrous convolution)
论文测试了不同实现技巧对于算法性能的影响

实验表明上述实现技巧均能够提升模型性能
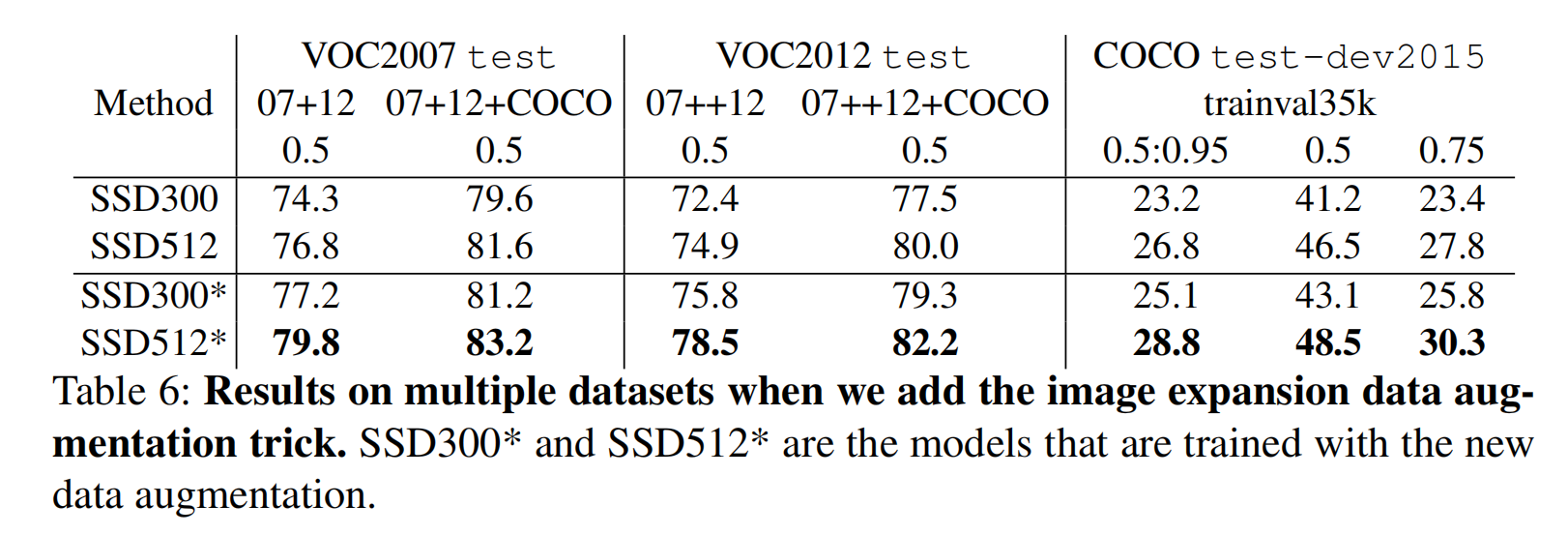
- 数据扩充对于性能提升很明显(提高了
8.8%) - 更多的不同长宽比的模型能够提高模型性能
- 扩展卷积能够加快模型计算(如果使用原始
VGG16网络,计算时间下降了20%)
特征图分析
论文评估了不同分辨率的特征图的数量对于性能的影响

在保持先验框数目大致相同的情况下,更多的特征图更有利于性能提升
模型性能
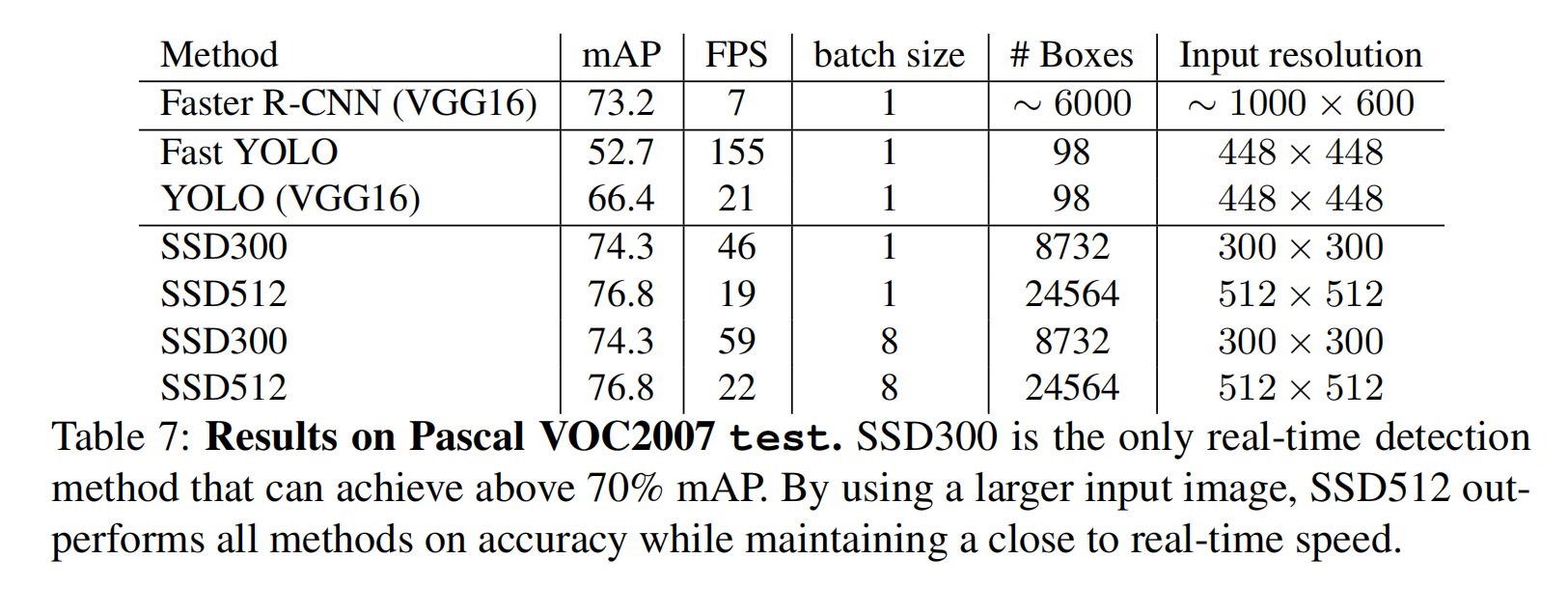
模型推导
SSD算法在进行NMS之前,先使用大小为0.01的置信度阈值过滤大部分的检测框;再对每个类别使用0.45的重叠阈值进行过滤
完成NMS处理之后,还可以额外添加一个置信度阈值(比如0.5)进行过滤;最后选择Top-K(这也是一个超参数)个检测框
小结
- 相比于
YOLO_v1算法,SSD在保持高FPS的情况下,通过数据扩充和多尺度卷积图计算,提高了对小尺度目标的检测能力 - 相比于
Faster RCNN算法,SSD通过先验框的设置,实现了端到端的检测,极大的提高了FPS