AutoAugment
原文地址:AutoAugment: Learning Augmentation Policies from Data
摘要
Data augmentation is an effective technique for improving the accuracy of modern image classifiers. However, current data augmentation implementations are manually designed. In this paper, we describe a simple procedure called AutoAugment to automatically search for improved data augmentation policies. In our implementation, we have designed a search space where a policy consists of many sub-policies, one of which is randomly chosen for each image in each mini-batch. A sub-policy consists of two operations, each operation being an image processing function such as translation, rotation, or shearing, and the probabilities and magnitudes with which the functions are applied. We use a search algorithm to find the best policy such that the neural network yields the highest validation accuracy on a target dataset. Our method achieves state-of-the-art accuracy on CIFAR-10, CIFAR-100, SVHN, and ImageNet (without additional data). On ImageNet, we attain a Top-1 accuracy of 83.5% which is 0.4% better than the previous record of 83.1%. On CIFAR-10, we achieve an error rate of 1.5%, which is 0.6% better than the previous state-of-the-art. Augmentation policies we find are transferable between datasets. The policy learned on ImageNet transfers well to achieve significant improvements on other datasets, such as Oxford Flowers, Caltech-101, Oxford-IIT Pets, FGVC Aircraft, and Stanford Cars.
数据增强是提高现代图像分类器精度的有效技术。然而,当前的数据扩充实现是手工设计的。在这篇文章中,我们描述了一个简单的过程,称为自动增强,以自动搜索改进数据增强策略。在我们的实现中,我们设计了一个搜索空间,其中策略由许多子策略组成,每个子策略都是为每个小批量中的每个图像随机选择的。子策略由两个操作组成,每个操作都是图像处理功能,如平移、旋转或剪切,以及应用这些功能的概率和幅度。我们使用搜索算法来寻找最佳策略,使得神经网络在目标数据集上产生最高的验证精度。我们的方法在CIFAR-10、CIFAR-100、SVHN和ImageNet上实现了最先进的准确性(无需额外数据)。在ImageNet上,我们获得了83.5%的top-1准确率,比之前的记录83.1%高0.4%。在CIFAR-10上,我们实现了1.5%错误率,比以前的最好记录高0.6%。我们发现增强策略可以在数据集之间转移。在ImageNet上学习的策略可以很好地在其他数据集上实现显著的改进,如Oxford Flowers、Caltech-101、Oxford-IIT Pets、FGVC Aircraft和Stanford Cars。
引言
数据扩充的目的:为了让模型学习到数据的不变性。比如水平翻转或者平移不变性。而且通过数据扩充的方式比网络设计更简单
Intuitively, data augmentation is used to teach a model about invariances in the data domain: classifying an object is often insensitive to horizontal flips or translation. Network architectures can also be used to hardcode invariances: convolutional networks bake in translation invariance [16, 32, 25, 29]. However, using data augmentation to incorporate potential invariances can be easier than hardcoding invariances into the model architecture directly.
AutoAugment实现
文章提出了一种自动增强策略,通过强化学习搜索算法从一堆基础的图像转换功能中找到一个最优组合,从而能够得到最高的验证精度
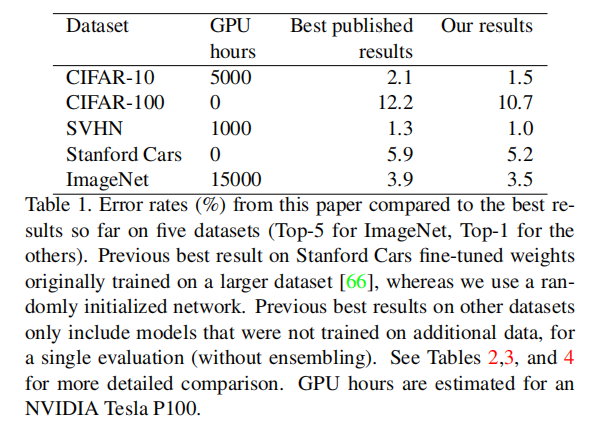
整体架构
上图表示自动增强算法的整体架构图,其包含两个关键组件:
- 搜索空间:使用多少个基础图像扩充功能,每个图像扩充拥有几个超参数等
- 搜索算法:论文使用强化学习作为搜索算法(即使那个
controller,控制策略采样方向)
其实现流程如下:
- 搜索算法采集数据扩充策略
- 使用固定的网络架构和训练流程,配合该搜索策略进行训练;
- 训练完成后评估得到验证精度
- 利用
搜索空间
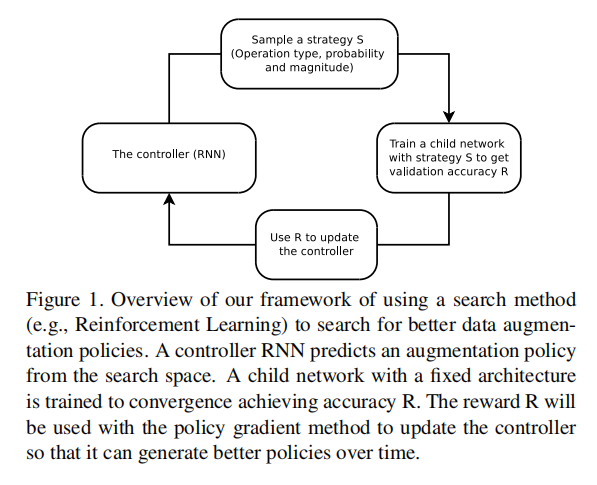
基本操作
论文使用PIL库定义的14种图像转换操作加上Cutout和SamplePairing作为搜索空间的基本操作。完整操作如下:
ShearX/Y, TranslateX/Y, Rotate, AutoContrast, Invert, Equalize, Solarize, Posterize, Contrast, Color, Brightness, Sharpness, Cutout , Sample Pairing
每个操作拥有两个超参数:发生的概率
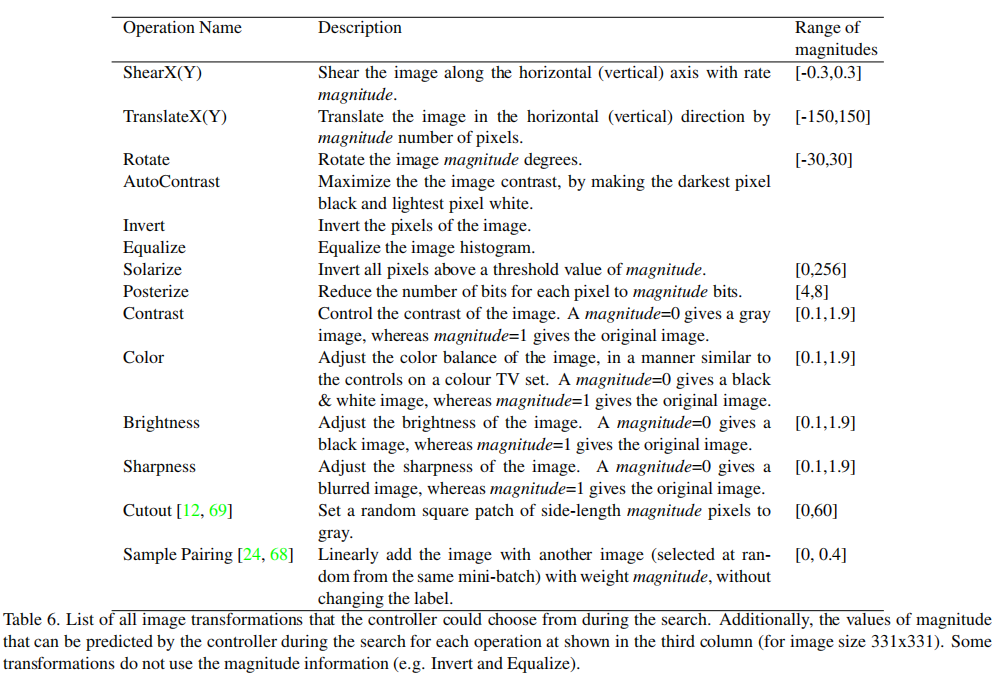
策略
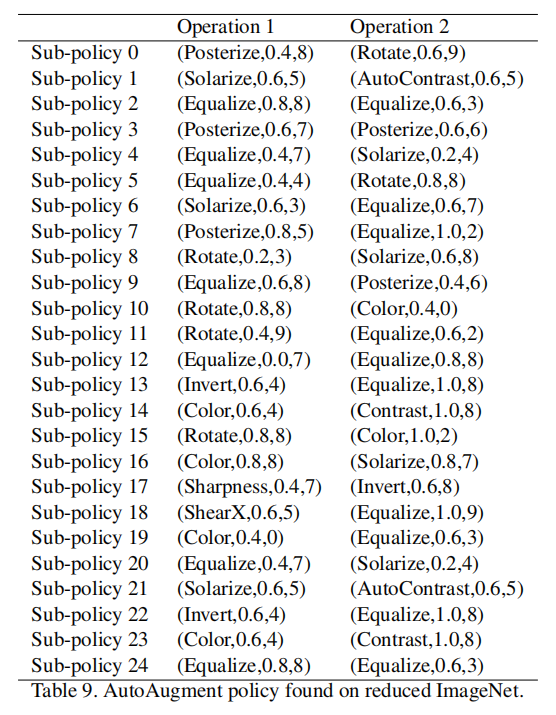
论文定义了策略(policy)作为搜索空间的采样单元,每个策略包含了5个子策略(sub-policies),每个子策略包含了2个连续执行的图像转换,同时每个图像转换拥有两个超参数:应用该操作的概率和操作具体幅度值
示例
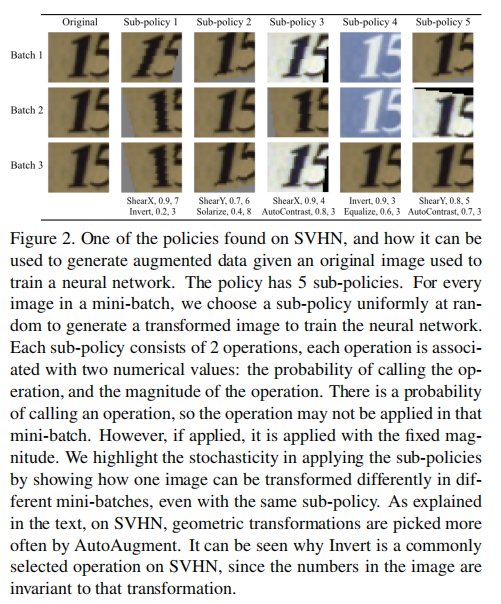
小结
子策略的变换共有
搜索算法
强化学习
...
小结
- 控制器每次生成
30个softmax预测,分别用于5个子策略以及每个策略的策略类型、发生概率和幅度值 - 对于每个数据集,控制器大约会采集
15,000个策略 - 完成搜索后,将
5个最好验证精度的策略(共25个子策略)级联在一起,作为数据集的数据扩充实现
训练和结果
论文比较了两种方式的数据扩充:
AutoAugment-direct:针对某个数据集进行搜索得到一组数据增强策略AutoAugment-transfer:将其他数据集搜索得到的数据增强策略作用于该数据集,验证自动增强算法得到的数据增强策略的可迁移性
AutoAugment-direct
论文在CIFAR-10/CIFAR-100/SVHN/ImageNet数据集上进行了直接搜索,不过为了加快搜索时间,论文使用了缩减数据集(reduced),比如CIFAR10,从原来的50,000个样本中采样了4,000个数据进行训练
训练策略
- 用于
CIFAR10- 模型:
Wide-ResNet-40-2(40层,宽度因子为2) - 训练次数:
120轮 - 权重衰减:
1e-4 - 学习率:
0.01 - 学习率策略:一个退火周期的余弦学习衰减
- 模型:
- 用于
ImageNet- 模型:
Wide-ResNet-40-2(40层,宽度因子为2) - 训练次数:
200轮 - 权重衰减:
1e-5 - 学习率:
0.1 - 学习率策略:一个退火周期的余弦学习衰减
- 模型:
训练结果
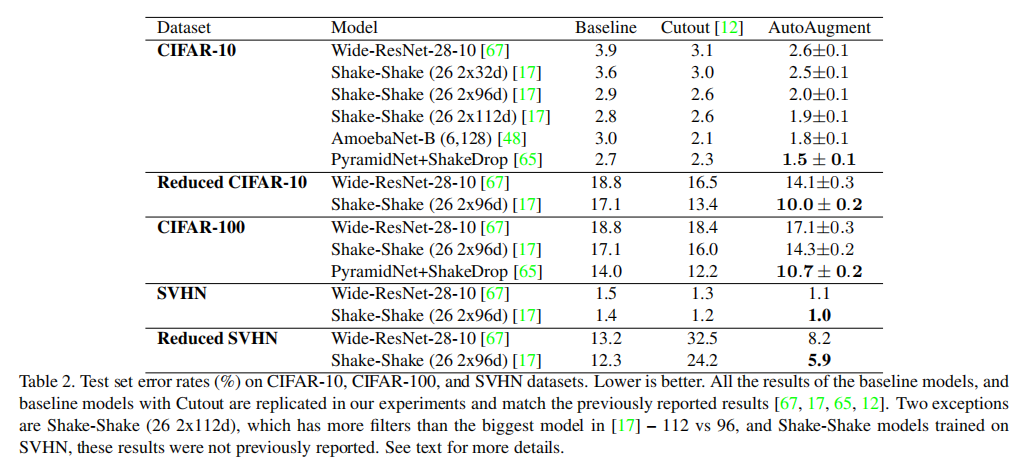
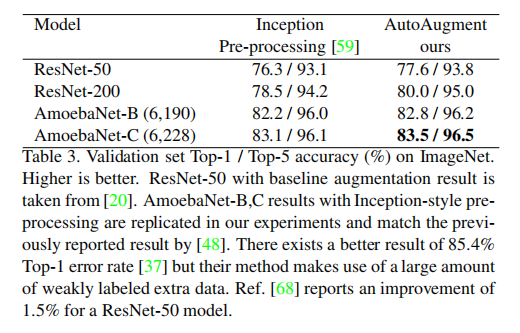
分析
从结果上看,不同数据集上搜索得到自动增强策略组合不一样:
- 在
CIFAR-10上,AutoAugment得到的更多的是基于颜色的转换,比如Equalize, AutoContrast, Color, and Brightness;而很少使用类似于ShearX/Y的几何操作 - 在
SVHN上,AutoAugment得到的更多的是基于几何的转换,比如Invert, Equalize, ShearX/Y, and Rotate。论文给出的解释是数据集中的门牌号通常是自然剪切和倾斜的,所以使用基于几何的数据扩充可以提高几何变换的不变性 - 在
ImageNet上,基于颜色的转换和基于几何的转换都很常见
AutoAugment-transfer
使用ImageNet学习得到的数据增强策略应用于其他数据集,以判断其迁移能力
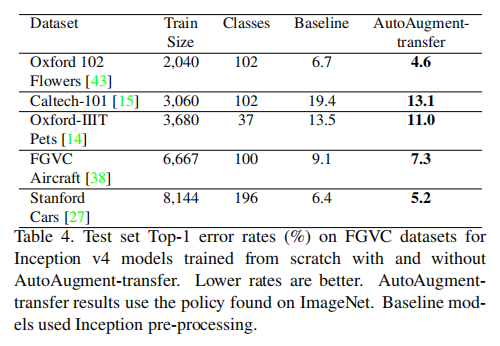
数据增强策略
CIFAR-10

SVHN

ImageNet
未找到相关的 Issues 进行评论
请联系 @zjykzj 初始化创建