[译]Selective Search for Object Detection (C++/Python)
学习论文Selective Search for Object Recognition,在网上查找相关资料时发现这篇文章,对于选择性搜索算法及其特征提取方式概括的比较好,所以翻译下来以便后续的学习
原文地址:Selective Search for Object Detection (C++ / Python)
In this tutorial, we will understand an important concept called “Selective Search” in Object Detection. We will also share OpenCV code in C++ and Python.
在本教程中,我们将了解一个重要的概念 - 基于选择性搜索的目标检测。文章末尾还包含了OpenCV示例
Object Detection vs. Object Recognition
目标检测 vs. 目标识别
An object recognition algorithm identifies which objects are present in an image. It takes the entire image as an input and outputs class labels and class probabilities of objects present in that image. For example, a class label could be "dog" and the associated class probability could be 97%.
目标识别算法识别图像中存在的对象。它将整个图像作为输入,并输出该图像中对象的类标签和类概率。例如,类标签可以是"dog",其关联的类概率为97%
On the other hand, an object detection algorithm not only tells you which objects are present in the image, it also outputs bounding boxes (x, y, width, height) to indicate the location of the objects inside the image.
另一方面,目标检测算法不仅告诉您图像中存在哪些对象,还输出边界框(x,y,width,height)以指示对象在图像中的位置
At the heart of all object detection algorithms is an object recognition algorithm. Suppose we trained an object recognition model which identifies dogs in image patches. This model will tell whether an image has a dog in it or not. It does not tell where the object is located.
所有目标检测算法的核心是目标识别算法。假设我们训练了一个目标识别模型,在图像块中识别狗。这个模型将判断图像中是否有狗,但它不知道狗的位置
To localize the object, we have to select sub-regions (patches) of the image and then apply the object recognition algorithm to these image patches. The location of the objects is given by the location of the image patches where the class probability returned by the object recognition algorithm is high.
为了定位目标,我们必须选择图像的子区域(小块),然后将目标识别算法应用于这些图像块。目标的位置由目标识别算法返回的类概率较高的图像块的位置给出
The most straightforward way to generate smaller sub-regions (patches) is called the Sliding Window approach. However, the sliding window approach has several limitations. These limitations are overcome by a class of algorithms called the “Region Proposal” algorithms. Selective Search is one of the most popular Region Proposal algorithms.
生成较小子区域(块)的最直接的方法称为滑动窗口方法。然而,滑动窗口方法有一些局限,而这些局限已经被"区域建议"算法所克服。选择性搜索是最流行的区域建议算法之一
Sliding Window Algorithm
滑动窗口算法
In the sliding window approach, we slide a box or window over an image to select a patch and classify each image patch covered by the window using the object recognition model. It is an exhaustive search for objects over the entire image. Not only do we need to search all possible locations in the image, we have to search at different scales. This is because object recognition models are generally trained at a specific scale (or range of scales). This results into classifying tens of thousands of image patches.
在滑动窗口方法中,我们将一个盒子或窗口滑动到一个图像上,选择一小块,并使用目标识别模型对窗口覆盖的每个图像块进行分类。它是对整个图像上的对象进行穷举搜索。我们不仅需要搜索图像中所有可能的位置,还需要在不同的尺度上进行搜索。这是因为目标识别模型通常是在特定的尺度(或尺度范围)下训练的。这将导致数万个图像块被分类
The problem doesn’t end here. Sliding window approach is good for fixed aspect ratio objects such as faces or pedestrians. Images are 2D projections of 3D objects. Object features such as aspect ratio and shape vary significantly based on the angle at which image is taken. The sliding window approach because computationally very expensive when we search for multiple aspect ratios.
问题还没有结束。滑动窗口方法适用于固定长宽比的物体,如人脸或行人。图像是三维物体的二维投影。对象特征,如纵横比和形状,根据拍摄图像的角度有很大的变化。滑动窗口方法,因为当我们搜索多个纵横比时,计算非常昂贵
Region Proposal Algorithms
区域建议算法
The problems we have discussed so far can be solved using region proposal algorithms. These methods take an image as the input and output bounding boxes corresponding to all patches in an image that are most likely to be objects. These region proposals can be noisy, overlapping and may not contain the object perfectly but amongst these region proposals, there will be a proposal which will be very close to the actual object in the image. We can then classify these proposals using the object recognition model. The region proposals with the high probability scores are locations of the object.
到目前为止,我们讨论的问题可以用区域建议算法来解决。这些方法将图像作为输入,输出图像中最可能是目标的所有块相对应的边界框。这些区域建议可能是有噪声的,重叠的,并且可能不完全包含对象,但是在这些区域建议中,将有一个建议非常接近图像中的实际对象。然后我们可以使用目标识别模型对这些建议进行分类。高概率得分的区域建议就是目标的位置
Region proposal algorithms identify prospective objects in an image using segmentation. In segmentation, we group adjacent regions which are similar to each other based on some criteria such as color, texture etc. Unlike the sliding window approach where we are looking for the object at all pixel locations and at all scales, region proposal algorithm work by grouping pixels into a smaller number of segments. So the final number of proposals generated are many times less than sliding window approach. This reduces the number of image patches we have to classify. These generated region proposals are of different scales and aspect ratios.
区域建议算法通过分割识别期望的对象。在分割过程中,我们根据颜色、纹理等准则组合彼此相似的相邻区域。与滑动窗口方法不同,滑动窗口方法是在所有像素位置和所有尺度上查找对象,区域建议算法通过将像素分组成更小的段来工作。因此,最终生成的建议数比滑动窗口方法少许多倍。这减少了我们需要分类的图像块的数量。这些生成的区域建议具有不同的比例和纵横比
An important property of a region proposal method is to have a very high recall. This is just a fancy way of saying that the regions that contain the objects we are looking have to be in our list of region proposals. To accomplish this our list of region proposals may end up having a lot of regions that do not contain any object. In other words, it is ok for the region proposal algorithm to produce a lot of false positives so long as it catches all the true positives. Most of these false positives will be rejected by object recognition algorithm. The time it takes to do the detection goes up when we have more false positives and the accuracy is affected slightly. But having a high recall is still a good idea because the alternative of missing the regions containing the actual objects severely impacts the detection rate.
区域建议方法的一个重要特性是具有很高的召回率。这只是一种奇特的说法,即包含我们正在寻找的对象的区域必须在我们的区域建议列表中。为了实现这一点,我们的区域建议列表可能会有很多区域不包含任何对象。换句话说,区域建议算法只要能够捕捉到所有的真阳性,产生大量的假阳性是可以接受的。因为这些假阳性大多会被目标识别算法拒绝。当我们有更多的假阳性并且准确度受到轻微影响时,检测所需的时间就会增加。但是高召回率仍然是一个好主意,因为丢失包含实际对象的区域会严重影响检测率
Several region proposal methods have been proposed such as 1. Objectness 2. Constrained Parametric Min-Cuts for Automatic Object Segmentation 3. Category Independent Object Proposals 4. Randomized Prim 5. Selective Search
Amongst all these region proposal methods Selective Search is most commonly used because it is fast and has a very high recall.
有如下几种区域建议算法:
- Objectness
- Constrained Parametric Min-Cuts for Automatic Object Segmentation
- Category Independent Object Porposals
- Randomized Prim
- Selective Search
在所有这些区域建议方法中,选择性搜索是最常用的,因为它速度快,召回率高
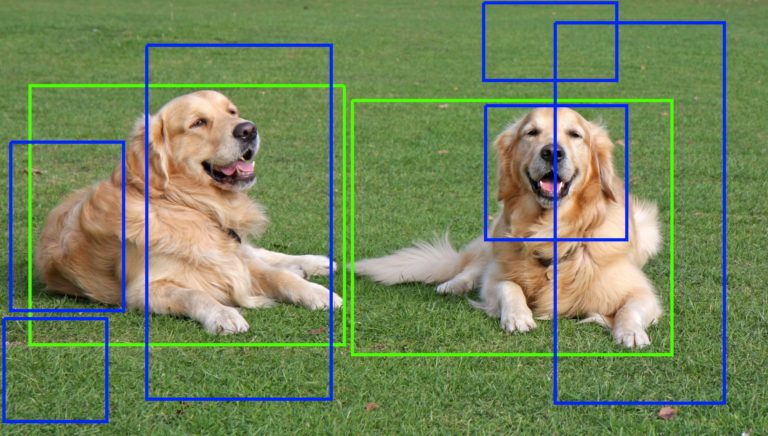
Blue Boxes: False Positives; Green Boxes: True Positives
蓝色框:假阳性;绿色框:真阳性
Selective Search for Object Recognition
作用于目标识别的选择性搜索
What is Selective Search?
什么是选择性搜索?
Selective Search is a region proposal algorithm used in object detection. It is designed to be fast with a very high recall. It is based on computing hierarchical grouping of similar regions based on color, texture, size and shape compatibility.
选择性搜索是一种用于目标检测的区域建议算法。它的速度很快,召回率很高。它基于颜色、纹理、大小和形状兼容性计算相似区域的分层分组
Selective Search starts by over-segmenting the image based on intensity of the pixels using a graph-based segmentation method by Felzenszwalb and Huttenlocher. The output of the algorithm is shown below. The image on the right contains segmented regions represented using solid colors.
选择性搜索从基于像素强度的图像过度分割开始,使用Felzenszwalb和Huttenlocher实现的基于图的分割方法,该算法输出如下所示。右侧的图像包含使用纯色表示的分段区域


Can we use segmented parts in this image as region proposals? The answer is no and there are two reasons why we cannot do that: 1. Most of the actual objects in the original image contain 2 or more segmented parts 2. Region proposals for occluded objects such as the plate covered by the cup or the cup filled with coffee cannot be generated using this method
我们可以用这个图像中的分割部分作为区域建议吗?答案是否定的,不能这样做的原因有两个:
- 原始图像中的大多数实际对象包含2个或更多分段部分
- 无法使用此方法生成被遮挡对象的区域建议,例如杯子覆盖的板或装满咖啡的杯子
If we try to address the first problem by further merging the adjacent regions similar to each other we will end up with one segmented region covering two objects.
如果我们试图通过进一步合并彼此相似的相邻区域来解决第一个问题,我们最终将得到一个覆盖两个对象的分段区域
Perfect segmentation is not our goal here. We just want to predict many region proposals such that some of them should have very high overlap with actual objects.
完美的分割并不是我们的目标。我们只想预测许多区域提案,以便其中一些提案与实际对象有很高的重叠
Selective search uses oversegments from Felzenszwalb and Huttenlocher’s method as an initial seed. An oversegmented image looks like this.
选择性搜索使用来自Felzenszwalb和Huttenlocher的方法得到的过度分段作为初始种子。过度分段图像如下所示:

Selective Search algorithm takes these oversegments as initial input and performs the following steps 1. Add all bounding boxes corresponding to segmented parts to the list of regional proposals 2. Group adjacent segments based on similarity 3. Go to step 1
选择性搜索算法将这些分段作为初始输入,并执行以下步骤:
- 将与分段部分相对应的所有边界框添加到区域方案列表中
- 基于相似度组合相邻分段
- 回到第一步
At each iteration, larger segments are formed and added to the list of region proposals. Hence we create region proposals from smaller segments to larger segments in a bottom-up approach. This is what we mean by computing “hierarchical” segmentations using Felzenszwalb and Huttenlocher’s oversegments.
在每次迭代中,都会形成较大的分段并将其添加到区域建议列表中。因此,我们采用自下而上的方法,从较小的部分到较大的部分创建区域建议。这就是我们所说的使用Felzenszwalb和Huttenlocher的过度分段计算“层次”分段
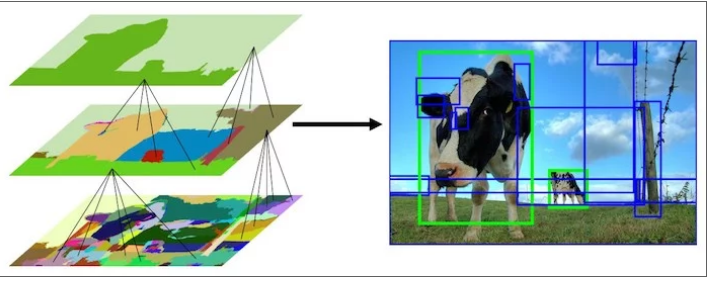
This image shows the initial, middle and last step of the hierarchical segmentation process.
上述图像显示了分层分割过程的初始、中间和最后一步
Similarity
相似度
Let’s dive deeper into how do we calculate the similarity between two regions.
让我们深入探讨如何计算两个区域之间的相似度
Selective Search uses 4 similarity measures based on color, texture, size and shape compatibility.
选择性搜索使用基于颜色、纹理、大小和形状兼容性的4种相似性度量
Color Similarity
颜色相似度
A color histogram of 25 bins is calculated for each channel of the image and histograms for all channels are concatenated to obtain a color descriptor resulting into a 25×3 = 75-dimensional color descriptor.
为图像的每个通道计算25个bin的颜色直方图,并将所有通道的直方图连接起来,以获得25×3=75维的颜色描述符
Color similarity of two regions is based on histogram intersection and can be calculated as:
两个区域的颜色相似度基于直方图相交,可计算为:
\[ s_{color}(r_{i},r_{j})=\sum_{k=1}^{n}\min(c_{i}^{k}, c_{j}^{k}) \]
\(c_{i}^{k}\) is the histogram value for \(k^{th}\) bin in color descriptor.
\(c_{i}^{k}\)表示颜色描述符中第\(k\)个bin的直方图值
Texture Similarity
纹理相似度
Texture features are calculated by extracting Gaussian derivatives at 8 orientations for each channel. For each orientation and for each color channel, a 10-bin histogram is computed resulting into a 10x8x3 = 240-dimensional feature descriptor.
纹理特征是通过提取每个通道8个方向上的高斯导数来计算的。对于每个方向和每个颜色通道,计算10个bin的直方图,得到10x8x3=240维特征描述符
Texture similarity of two regions is also calculated using histogram intersections.
两个区域的纹理相似度也使用直方图相交计算:
\[ s_{texture}(r_{i}, r_{j}) = \sum_{k=1}^{n} \min (t_{i}^{k}, t_{j}^{k}) \]
\(t_{i}^{k}\) is the histogram value for \(k^{th}\) bin in texture descriptor
\(t_{i}^{k}\)表示纹理描述符中第\(k\)个bin的直方图值
Size Similarity
大小相似度
Size similarity encourages smaller regions to merge early. It ensures that region proposals at all scales are formed at all parts of the image. If this similarity measure is not taken into consideration a single region will keep gobbling up all the smaller adjacent regions one by one and hence region proposals at multiple scales will be generated at this location only. Size similarity is defined as:
大小相似度鼓励较小的区域尽早合并。它确保在图像的所有部分形成所有比例的区域建议。如果不考虑这种相似性度量,则单个区域将逐个吞噬所有较小的相邻区域,因此仅在此位置生成多个尺度的区域建议。大小相似度定义如下:
\[ s_{size}(r_{i}, r_{j}) = 1 - \frac {size(r_{i}) + size(r_{j})}{size(im)} \]
where \(size(im)\) is size of image in pixels
其中\(size(im)\)指的是图像的像素大小
Shape Compatibility
形状兼容度
Shape compatibility measures how well two regions (\(r_i\) and \(r_j\)) fit into each other. If \(r_i\) fits into \(r_j\) we would like to merge them in order to fill gaps and if they are not even touching each other they should not be merged.
形状兼容度判定两个区域(\(r_{i}\)和\(r_{j}\))的匹配程度。如果\(r_{i}\)与\(r_{j}\)相匹配,希望将它们合并能够填补框的空白,如果它们甚至没有相互接触,则不应合并
Shape compatibility is defined as:
形状兼容度定义如下:
\[ s_{fill}(r_{i},r_{j}) = 1 - \frac{size(BB_{ij}) - size(r_{i}) - size(r_{j})}{size(im)} \]
where \(size(BB_{ij})\) is a bounding box around \(r_{i}\) and \(r_{j}\)
其中\(size(BB_{ij})\)是围绕\(r_{i}\)和\(r_{j}\)的边界框
Final Similarity
The final similarity between two regions is defined as a linear combination of aforementioned 4 similarities.
两个区域之间的最终相似度定义为上述4个相似度的线性组合
\[ s(r_{i}, r_{j}) = a_{1}s_{color}(r_{i}, r_{j}) + a_{2}s_{texture}(r_{i}, r_{j}) + a_{3}s_{size}(r_{i}, r_{j}) + a_{4}s_{fill}(r_{i}, r_{j}) \]
where \(r_i\) and \(r_j\) are two regions or segments in the image and \(a_i \in {0, 1}\) denotes if the similarity measure is used or not.
其中\(r_i\)和\(r_j\)是图像中的两个区域或段,\(a_{i}\in {0,1}\)表示是否使用了相似性度量
Results
结果
Selective Search implementation in OpenCV gives thousands of region proposals arranged in decreasing order of objectness. For clarity, we are sharing results with top 200-250 boxes drawn over the image. In general 1000-1200 proposals are good enough to get all the correct region proposals.
OpenCV中的选择性搜索实现给出了数千个按目标降序排列的区域建议。为了清晰起见,我们将与图像上绘制的前200-250个框共享结果。总的来说,1000-1200份建议足以得到所有正确的区域建议

Selective Search Code
选择性搜索实现代码
OpenCV提供了选择性搜索算法的使用示例,包含了C++版本和Python版本
/path/to/opencv_contrib/modules/ximgproc/samples/selectivesearchsegmentation_demo.cpp/path/to/opencv_contrib/modules/ximgproc/samples/selectivesearchsegmentation_demo.py