ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
原文地址:ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
摘要
Currently, the neural network architecture design is mostly guided by the indirect metric of computation complexity, i.e., FLOPs. However, the direct metric, e.g., speed, also depends on the other factors such as memory access cost and platform characterics. Thus, this work proposes to evaluate the direct metric on the target platform, beyond only considering FLOPs. Based on a series of controlled experiments, this work derives several practical guidelines for efficient network design. Accordingly, a new architecture is presented, called ShuffleNet V2. Comprehensive ablation experiments verify that our model is the state-of-the-art in terms of speed and accuracy tradeoff.
当前,神经网络体系结构的设计主要以计算复杂度的间接度量为指导,即FLOPs。然而,直接度量,例如速度,也取决于其他因素,例如内存访问成本和平台特性。因此,本文建议评估目标平台上的直接度量,而不仅仅是考虑FLOPs。本文在一系列受控实验的基础上,为有效的网络设计提供了一些实用的指导。因此,提出了一种新的体系结构,称为ShuffleNet V2。综合烧蚀实验证明,我们的模型在速度和精度方面是最先进的
章节内容
- 首先讨论了间接评价指标
FLOPs和直接评价指标Speed之间的差异性 - 其次论文推导了
4条设计原则,并设计了一个新的模型 -ShuffleNetV2 - 通过实验证明了新的模型能够达到更高的准确率和速度
FLOPs ?Speed !
最常用FLOPs(float-point operations,论文中称其为multiply-adds)来评价模型计算复杂度,不过这是一个间接性评价标准,它并没有考虑全面考虑可能影响实际使用速度的因素,所以会存在相近FLOPs的模型拥有不一样的执行速度。如下图(c/d)所示
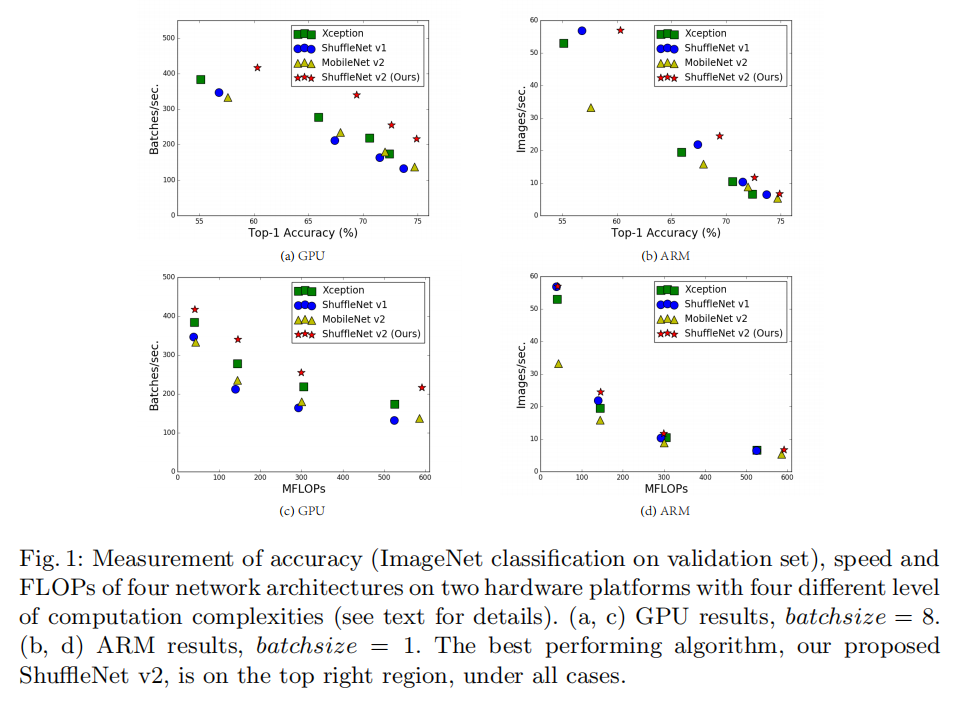
差异性
FLOPs和速度之间的差异主要分为两部分:
FLOPs并没有考虑一些会影响速度的重要因素,比如- 内存访问成本(
memory access cost, MAC)。对于包含大量MAC的开销会占据运行时的很大一部分 - 模型并行度。在相同
FLOPs的情况下,高并行度的模型能够运行更快
- 内存访问成本(
- 基于不同平台下,相同
FLOPs的操作可能存在不一样的运行时间(库优化的缘故)
设计原则
- 应该使用直接评价标准(
Speed)而不是简介评价标准(FLOPs) - 应该基于不同平台进行评估
设计准则
论文基于FLOPs和Speed的差异性提出了两个设计原则,并以此为基础进行了大量实验,从而推导出4条设计准则
实验环境
GPU: NVIDIA GeForce GTX 1080Ti以及CUDNN 7.0ARM: Qualcomm Snapdragon 810- 输入图像:
- 速度计算:平均
100次计算时间 - 评估网络:
ShuffleNetV1和MobileNetV2
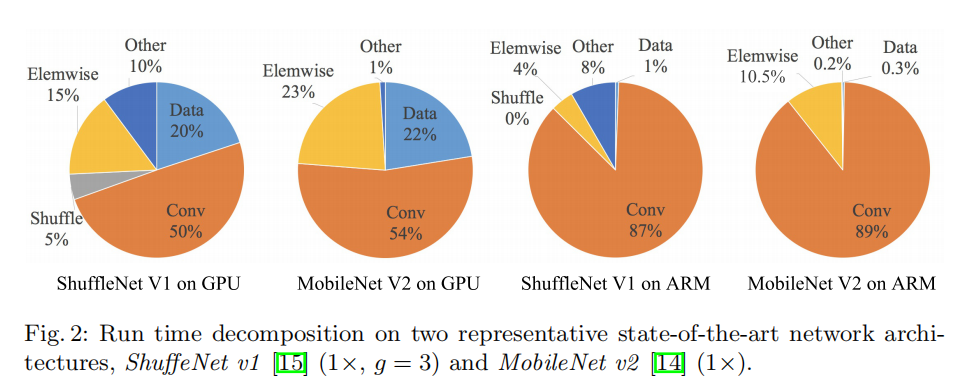
将整体运行时间分解成不同的操作,如上图所示
FLOPs仅考虑了卷积操作,而卷积操作在不同平台上耗费了不一样的时间- 数据
I/O、数据重排以及逐元素操作(张量加法/ReLU等)也耗费了很多的时间
G1:相同输入输出通道数能够保证最小MAC使用
G1: Equal channel width minimizes memory access cost (MAC)
在深度可分离卷积操作中,逐点卷积(FLOPs的情况下,不同
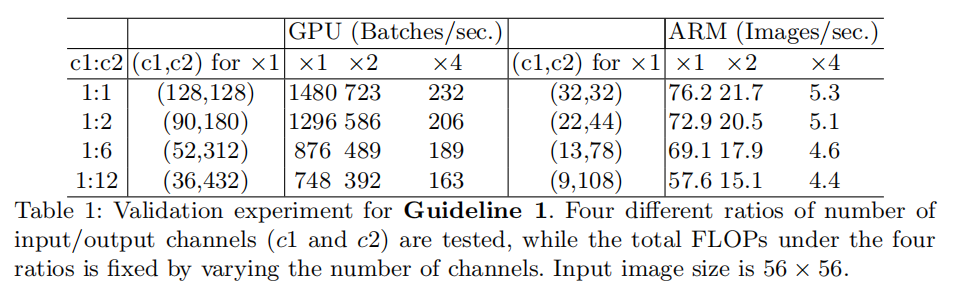
G2:过多的分组卷积操作会增加MAC使用
G2: Excessive group convolution increases MAC
在分组卷积操作中,更多的分组(
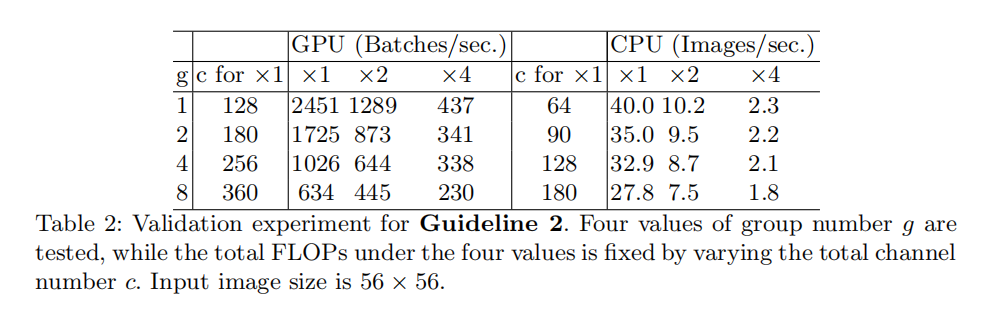
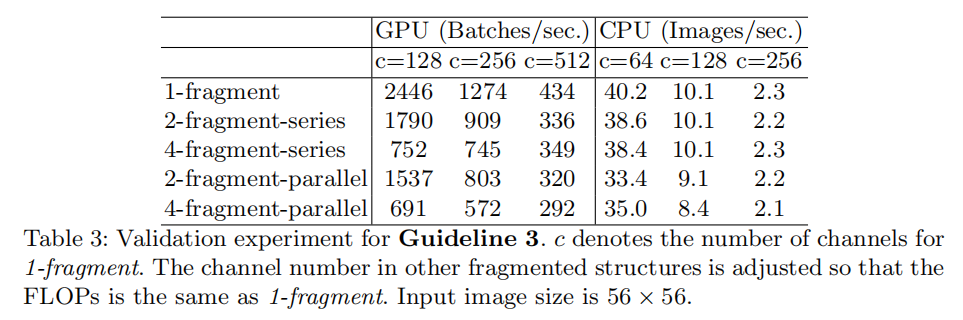
G3:网络碎片化降低了并行度
G3: Network fragmentation reduces degree of parallelism.
在GoogLeNet系列以及自动生成架构中,大量使用了多分支构建块,每个分支又包含了多次单独操作(称之为碎片操作fragmented opeators)。论文比较了网络碎片化对计算速度的影响,发现网络碎片化降低了模型并行度
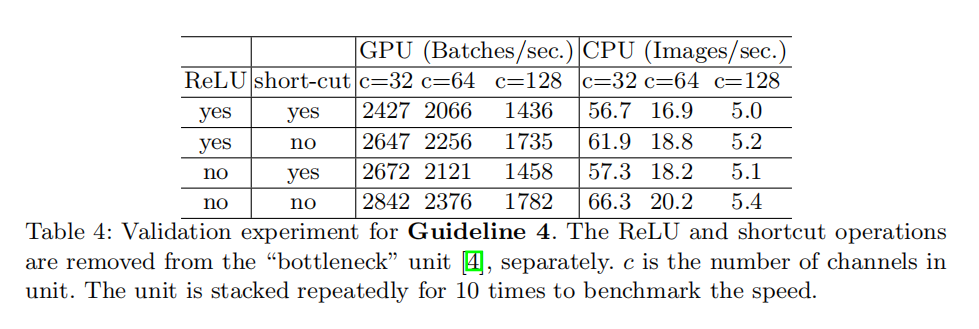
G4:不能忽略逐元素操作的时间
G4: Element-wise operations are non-negligible.
论文探索了逐元素操作(比如ReLU/AddTensor/AddBias等)对计算复杂度的影响,发现其同样耗费了不菲的时间
小结
基于上述4条设计准则,推导出高效的网络应该包含以下实现:
- 使用
平衡卷积(相同的输入输出通道数) - 注意分组卷积的数目
- 减少碎片化操作
- 减少逐元素操作
模型架构
ShuffleNet Unit
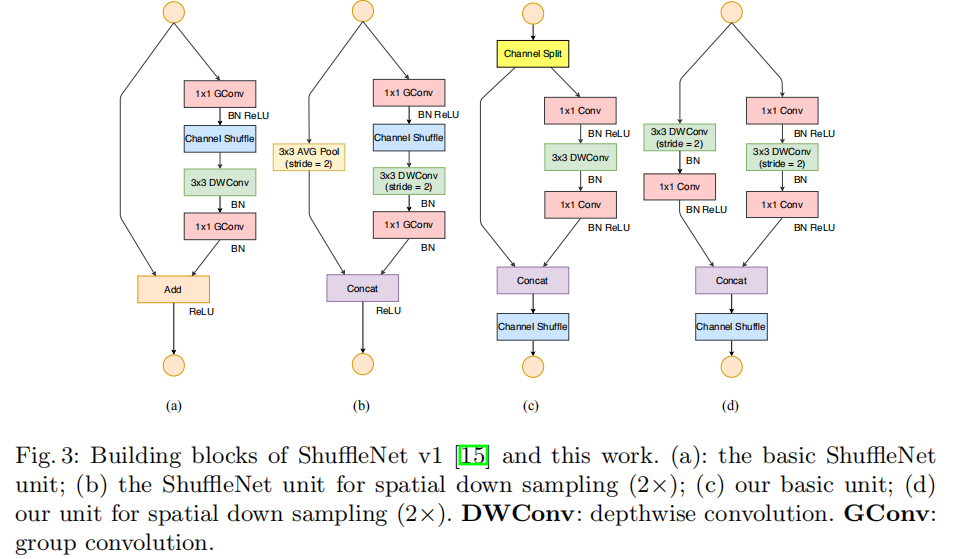
Channel Split:将输入特征图通道数(ShuffleNetV2不再使用分组卷积操作Channel Shuffle:通道重排操作,实现上述两组特征图的信息交流DW Conv:深度卷积操作
整体架构
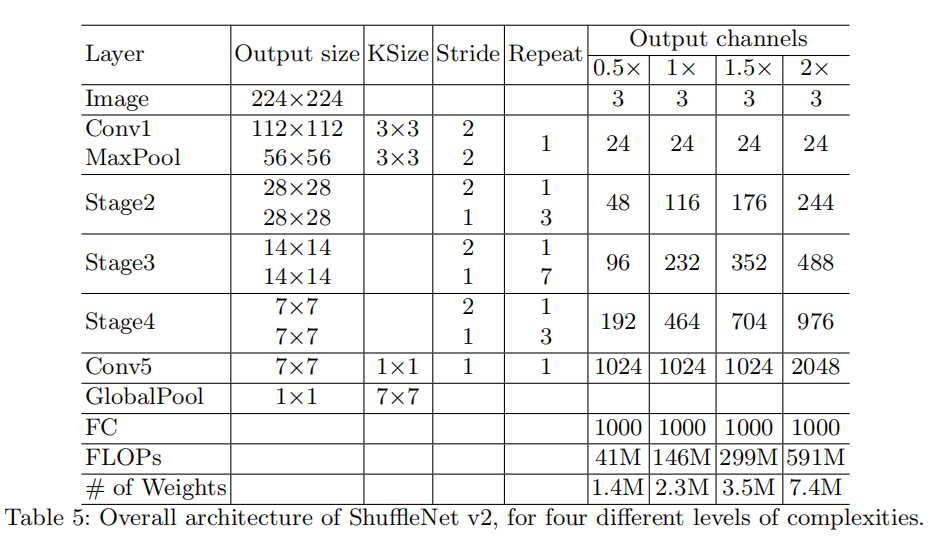
实现架构类似于ShuffleNetV1,不过不再基于分组数设计相近FLOPs的模型,而是实现了4个不同计算复杂度的模型
小结
论文基于直接评价指标(Speed)进行计算复杂度分析,着重分析了内存访问成本、逐元素操作、模型并行度以及不同平台的影响,提出了4条设计准则。最后,论文基于ShuffleNetV1提出了V2架构
未找到相关的 Issues 进行评论
请联系 @zjykzj 初始化创建