SQUEEZENET
原文地址:SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
摘要
Recent research on deep convolutional neural networks (CNNs) has focused primarily on improving accuracy. For a given accuracy level, it is typically possible to identify multiple CNN architectures that achieve that accuracy level. With equivalent accuracy, smaller CNN architectures offer at least three advantages: (1) Smaller CNNs require less communication across servers during distributed training. (2) Smaller CNNs require less bandwidth to export a new model from the cloud to an autonomous car. (3) Smaller CNNs are more feasible to deploy on FPGAs and other hardware with limited memory. To provide all of these advantages, we propose a small CNN architecture called SqueezeNet. SqueezeNet achieves AlexNet-level accuracy on ImageNet with 50x fewer parameters. Additionally, with model compression techniques, we are able to compress SqueezeNet to less than 0.5MB (510× smaller than AlexNet).
最近对深度卷积神经网络的研究主要集中在提高精度上。对于给定的准确度级别,通常存在多个达到该准确度级别的CNN架构。准确地说,小型CNN架构至少有三个优点:(1)小型CNN架构在分布式训练中需要更少的服务器间通信。(2)小型CNN架构需要更少的带宽来将一个新模型从云中导出到一辆自动驾驶汽车上。(3)小型CNN架构更适合部署在FPGAs和其他内存有限的硬件上。为了提供所有这些优势,我们提出了一种小型CNN架构,称为SqueezeNet。SqueezeNet在减少50倍参数的情况下在ImageNet上实现了AlexNet级别的精度。此外,通过模型压缩技术,我们能够将SqueezeNet压缩到小于0.5MB(比AlexNet小510倍)
The SqueezeNet architecture is available for download here: https://github.com/DeepScale/SqueezeNet
SqueezeNet架构实现参考以下网址:https://github.com/DeepScale/SqueezeNet
轻量化模型优势
- 在训练中更有效率。服务器之间的通信是限制分布式
CNN训练可扩展性的因素之一。对于分布式数据并行训练,通信开销与模型中的参数数量成正比。简而言之,小型CNN需要更少的交流,因此训练速度更快 - 向客户导出新模型时开销更小。比如
Telsa等公司采用在线更新的方式,定期将新模型导入到客户的汽车中。在这种情况下,更小的模型能够减少更新时间,提高传输安全性 - FPGAs以及嵌入式硬件部署。对于内存以及存储空间有限制的硬件而言,模型的大小至关重要
相关工作
在RELEATED WORK小节,论文讨论了4个部分:
- 模型压缩
CNN微架构CNN宏架构- 神经网络设计空间探索
模型压缩
以有损方式压缩训练好的CNN模型,能够使用很小的参数就能够达到很好的精度。当前已出现了多种模型压缩(model compress)方法:
SVD(singular value decomposition)Network Pruning(网络剪枝): 用零替换低于某个阈值的参数以形成稀疏矩阵,最后在稀疏的CNN上执行几次迭代训练Deep Compression: Network Pruning with quantization + huffman encoding
CNN微架构
由具有特定固定组织的多个卷积层组成的各种更高级的构建块或模块(比如Inception、BottleBlock),使用术语CNN微架构(CNN Microarchitecture)来指代各个模块的特定组织和维度
CNN宏架构
CNN微架构指的是单个层或者模块结构,将多个模块组成端到端的CNN体系结构的系统级别组织称为CNN宏架构(CNN macroarchitecture)
bypass connections:跨越多个层或者模块的连接。比如ResNet的残差连接
神经网络设计空间探索
神经网络设计空间探索(Neural Network Design Space Exploration)包含以下方面:
- 微架构的选择
- 宏架构的选择
- 求解器(
solver) - 其他超参数
SqueezeNet
设计策略
- 使用
9倍小于 - 减少
- 在网络后期进行下采样,以便卷积层具有大的激活图。其他都保持不变的情况下,大的激活图(由于延迟下采样)可以导致更高的分类精度
策略1和2用于减少CNN的参数数量,同时试图保持准确性。策略3是关于在有限的参数预算下最大限度地提高准确性
Fire模块
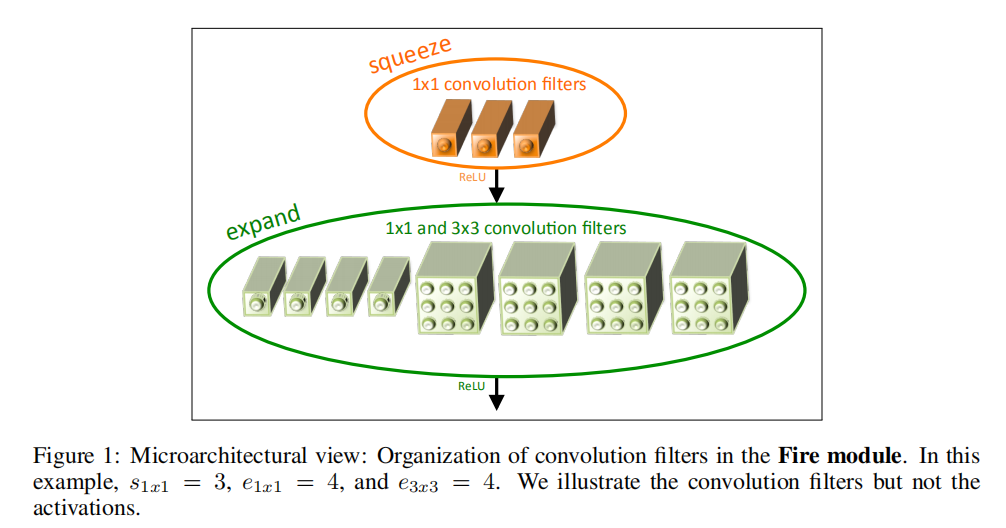
Fire模块由两个层组成:
squeeze卷积层:仅包含expand卷积层:包含了
包含3个超参数:
squeeze层中滤波器的数目expand层中expand层中
其设计原则:
1squeeze层来限制输入数据体的深度,符合策略3
架构细节
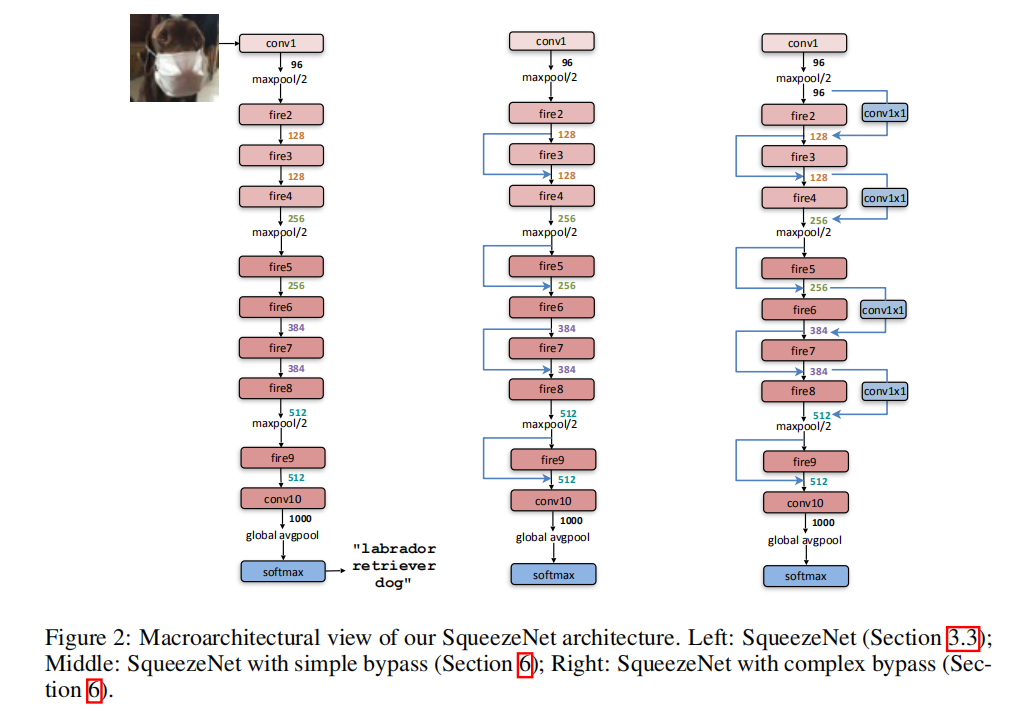
其模型从输入到输出如下所示:
- 卷积层(
conv1) - 连续
8个Fire模块(fire2-9) - 全连接层(
conv10)
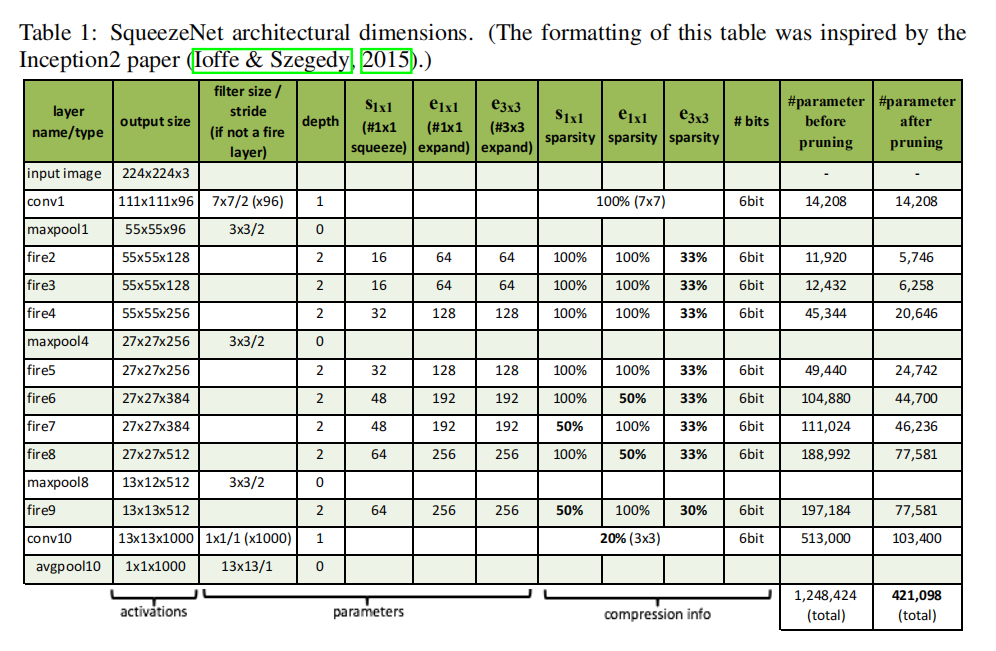
对于Fire模块而言,逐步增加滤波器个数;在conv1/fire4/fire8/conv10之后执行步长为2的最大池化操作。完整参数设置如表一所示
训练/测试
训练
文章很贴心的给出了详细的训练细节
- 为了保证
- 使用
ReLU激活函数 - 在
Fire 9模块后执行50%的随机失活 - 初始学习率为
0.04,在训练过程中线性降低
测试
文章比较了AlexNet和SqueezeNet的参数数目以及训练准确度,包含了压缩版本如下表所示:
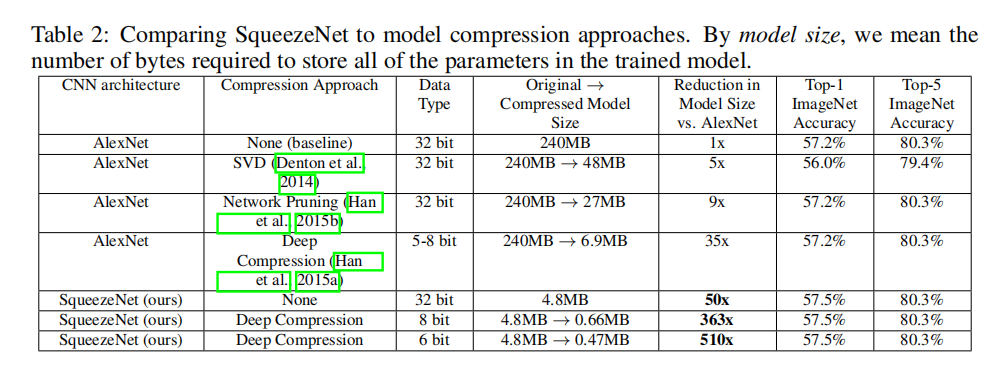
- 原始
AlexNet模型使用32bit数据类型,模型大小为240MB- 通过
SVD,能够实现48MB的模型大小,压缩了近5倍 - 通过网络剪枝,能够实现
27MB的模型大小,压缩了近9倍 - 通过模型压缩,使用
5-8bit数据类型,能够实现6.9MB的模型大小,压缩了近35倍
- 通过
- 原始
SqueezeNet模型使用32bit数据类型,模型大小为4.8MB。相比于原始AlexNet模型,压缩了近50倍;相比于压缩后的AlexNet模型,压缩了近1.4倍- 通过
8bit的模型压缩,能够实现0.66MB的模型大小。相比于原始AlexNet模型,压缩了近363倍 - 通过
6bit的模型压缩,能够实现0.47MB的模型大小。相比于原始AlexNet模型,压缩了近510倍
- 通过
通过实验证明小模型在保留基准精度的情况下,也能够使用模型压缩方法进行有效压缩
SqueezeNet+Bypass
文章同时比较了残差连接的影响,其结构如图2所示。实验结果如下表所示

使用简单的残差连接设置后可以得到更好的检测准确度
小结
SqueezeNet对模型大小进行了进一步探索,证明了轻量化模型的可用性。具体实现参考zjZSTU/LightWeightCNN
未找到相关的 Issues 进行评论
请联系 @zjykzj 初始化创建