[译]Breaking Down Mean Average Precision (mAP)
原文地址:Breaking Down Mean Average Precision (mAP)
最近在学习关于图像检索领域的评判指标,发现用的就是PR曲线以及mAP评估。不过在具体的精度和召回率定义上和之前目标检测任务中的计算方式会有差别。wiki上的相关文档:Evaluation measures (information retrieval),内容比较难以理解,在网上找到这篇文章,整体看下来发现干货满满,没有需要精简的地方,所以打算整篇翻译成中文,方便日后回顾。
引言
如果参与过PASCAL VOC以及COCO挑战,或者涉及过信息检索和重识别(ReID)任务,可能会非常熟悉mAP评估。
均值平均精度(mean average precision (mAP))或者有时候称之为AP是一个非常受欢迎的评估指标,在文档/信息检索以及目标检测任务上广泛使用。在wiki上mAP的定义如下:
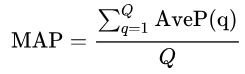
其中average precision (AP))。上述公式描述的是,给定查询AP,然后平均所有AP得到一个数值,称为mAP。通过mAP来量化模型对于这一次查询的性能。
上述定义听起来不太好理解,有很多没有解释的地方:查询集是什么?AP意味着什么?是不是就是精度的平均?
本文旨在解释上述问题,包括在目标检测以及信息检索任务上的mAP计算。同时后续文章也会探索为什么mAP对于信息检索和目标检测任务而言是一个很好的指标。
概述
- 基础知识
AP以及mAP(信息检索任务)AP以及mAP(目标检测任务)
基础知识
精度(precision)和召回率(recall)常用于评估分类模型的性能。mAP的计算跟这两个相关,首先来回顾精度和召回率的计算。
版本一
在统计学以及数据科学领域,在分类任务中给定类的精度(或者称之为阳性预测值(positive predicted value))由真阳性样本数(就是预测正样本中的真阳性样本个数(true positive (TP)))以及整体预测正样本数计算得出:
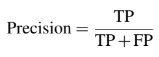
类似的,分类任务中给定类的召回率,也称之为真阳性率(true positive rate)或者敏感度(sensitivity)由TP以及正样本数计算得出:
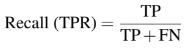
仅需查看这些公式,就能够推断出对于给定分类模型而言,必定在精度和召回率中间存在平衡。如果使用的是神经网络,那么通过调整最后一层Softmax阈值即可。
想要提高精度,那么就需要降低FP(false positive/假阳性,也就是预测为正样本,实际是负样本)数目,但是这样会相应的降低召回率。同样的,通过降低FN(false negative/假阴性,也就是预测为负样本,实际是正样本)的数目可以提高召回率,相应的会降低精度。对于信息检索和目标检测任务,通常希望精度很高(即预测的阳性样本都是TP)。
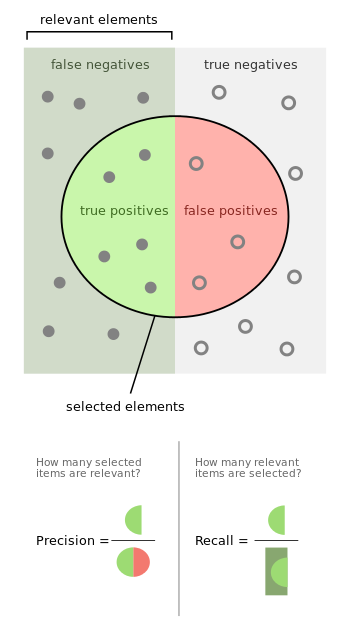
精度和召回率通常与其他指标一起使用,如准确率(accuracy)、F1分数(F1-score)、特异性(specificity,也称为真阴性率(TNR))、接收器操作特征(receiver operating characteristics, ROC)、提升(lift)和增益(gain)。
版本二
对于信息检索任务而言,对于精度和召回率的定义是有差异的。在wiki中定义的精度是与用户查询相关的检索文档(relevant document)与整体检索到的文档(retrived documents)之间的比率(As defined by Wiki, precision is defined as the ratio of the retrived documents that are relevant to user's query over the retrieved documents.)
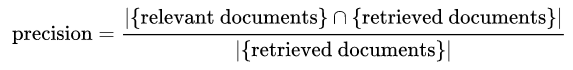
- 相关文档(
relevant document)可以看成是TP; - 检索文档(
retrieved documents)可以看成是TP+FP。
默认情况下,精度计算中会将所有参与的候选样本统计在内。当然也可以指定检索文档的数目,通常被称为截止等级(cut-off rank),仅会计算排序前几位的候选样本,这种测量称之为P@K。
下面举个例子来说明这种情况:一个典型的信息检索任务是用户向数据库进行查询,检索与查询非常相似的信息。假定输入查询在数据库中拥有3个正样本(也就是相关文档(relevant documents)),定义如下变量:
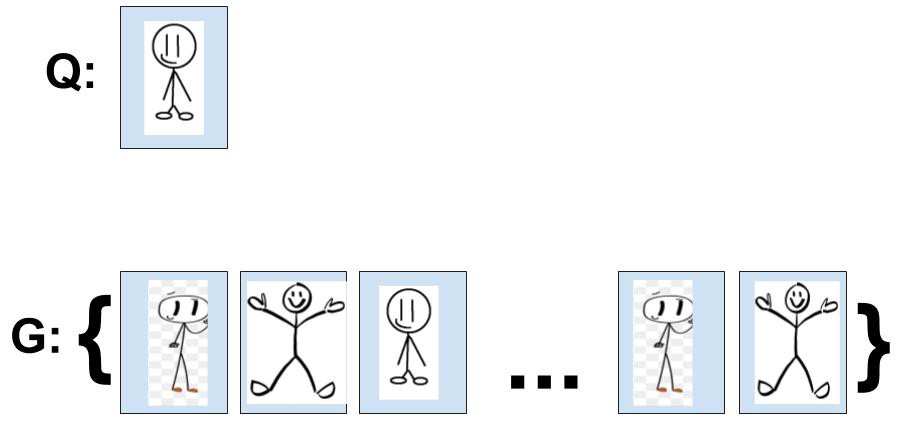
完成查询

使用上面的精度计算公式,可以计算如下:
类似的,在Wiki中定义的召回率是与用户查询相关的检索文档与相关文档的比率(the recall formula defined by Wiki is given as the ratio retrieved documents that are relevant to user' s query over the relevant documents.)
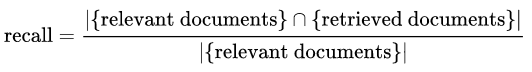
在使用所有的检索文档的情况下,召回率计算总是100%,因此不常作为评估指标。
AP以及mAP(信息检索任务)
AP
熟悉P@K的计算后,接下来开始AP(Average Precision,平均精度)的计算,它能够更好地衡量模型对查询结果
- 上面是
AP@n的计算公式 GTP表示the total number of ground truth positives,也就是真值标签/正样本的数目;n表示参与检索的文档数目;
和上面精度的计算公式联系在一起,就可以计算得到AP的结果:
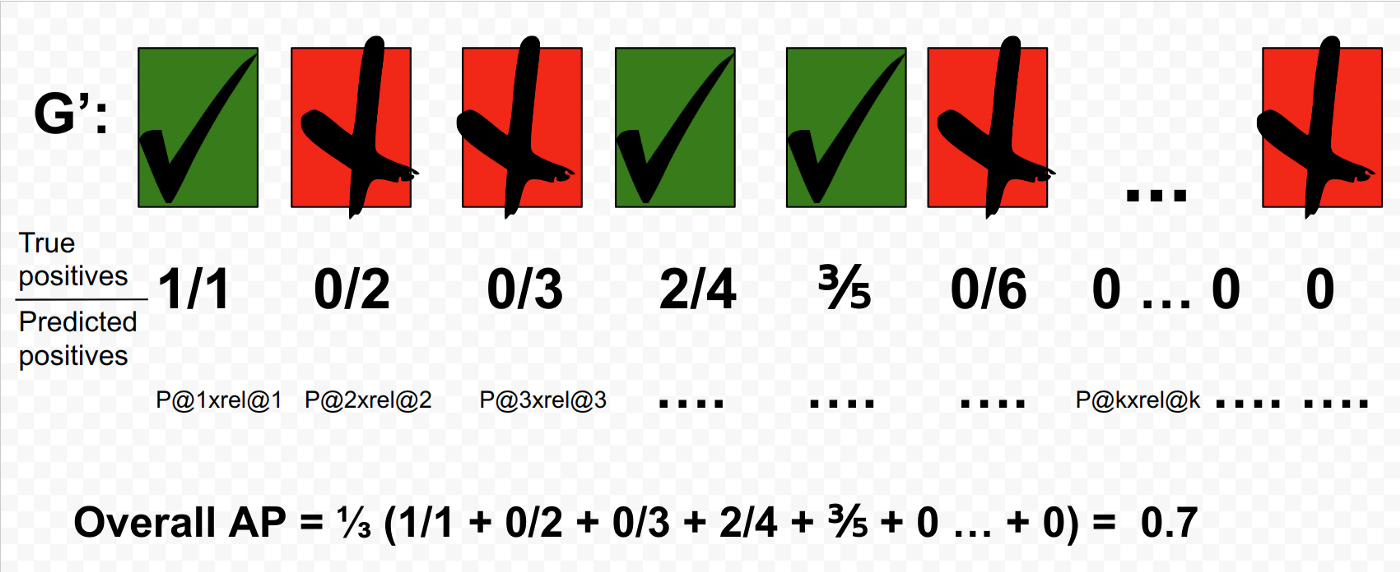
上述查询中整体AP的计算结果是0.7。需要注意的是因为我们已经了解了仅有3个相关文档,所以AP@5就等于整体AP。下面是另一次查询结果,这一次可以获取得到AP=1:

AP的作用是惩罚那些无法将TPs排序到前面的模型(What AP does, in this case, is to penalise models that are not able to sort G’ with TPs leading the set.)。它通过数值来量化模型基于相似函数GTP数目而不是整个查询总数,可以更好的表示查询质量。
mAP
对于每次查询AP。用户可以查询任意次数,而mAP即是简单的将这个查询计算的AP进行平均:
注意:上述公式和Wiki描述的一致,只是写法有差异。
AP以及mAP(目标检测任务)
IoU
计算目标检测任务的AP,首先需要了解IoU(Intersection over Union,交并比)的概念。IoU指的是预测边界框和真值边界框的交集和并集之间比例:
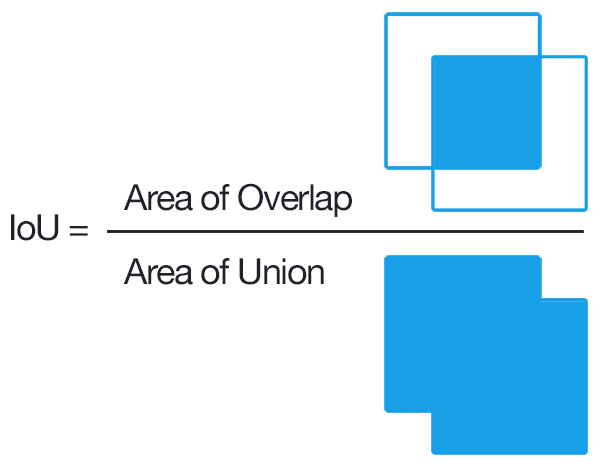
通过IoU来判断预测边界框是否是TP,FP还是FN。由于假设每个图像中都有一个目标,因此不会对TN进行评估。假定检测图像如下所示:

上述图像包含了一个行人和一匹马以及对应的真值边界框。首先对行人进行检测,忽略马,得到一个预测框。通常来说,会将IoU>0.5的预测框视为TP。如下所示:
- 真阳性(
True Positive / TP, IoU>0.5):下图中预测框(黄色)和真值框(蓝色)的IoU大于0.5,并且分类正确

- 假阳性(
False Positive / FP):两种情况下将预测边界框视为FP:
IoU < 0.5- 重复的边界框

- 假阴性(
False Negative / FN):当检测模型没有检测得到这个目标时,称为假阴性。存在两种情况下:
- 没有检测结果

- 存在预测框并且
IoU>0.5,但是错误分类,此时也视为FN

PR曲线
在完成TP/FP/FN的定义后,就可以计算测试集中给定类的精度和召回率。每个预测边界框都会给予预测置信度,通常由softmax层给出,将会被用于排序。这种情况非常类似于信息检索任务,只不过不需要额外的相似度函数
插值精度
在绘制PR曲线之前,需要了解插值精度(interpolated precision):每个召回级别
对PR曲线进行插值的目的是减少因检测排序的微小变化而引起的“摆动”的影响。完成上述定义后,就可以开始绘制PR曲线。假定行人类的一个检测图像拥有3个TP和4个FP,通过上述公式计算相应的精度,召回率以及插值精度。
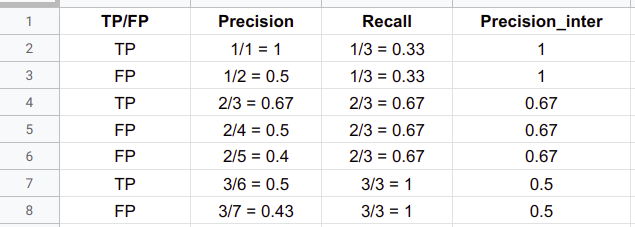
上表中每一行表示一个预测边界框,按置信度进行排序。绘制的PR曲线如下:
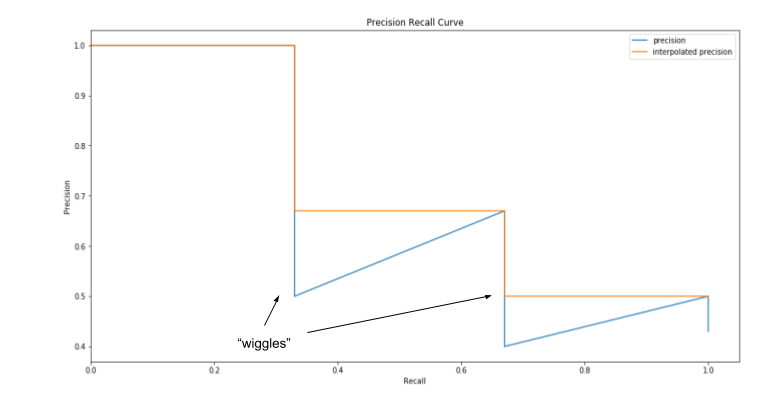
通过计算PR曲线下面积可以得到AP,将召回率取值等分为11份:
其它的示例可以参考:mAP (mean Average Precision) for Object Detection
mAP
完成所有类别的AP计算后,mAP即是这些AP的平均值。另外需要注意的是,在一些论文中混淆了AP和mAP的使用。
其他
除了PASCAL VOC计算方式外,还存在其他计算方式,比如COCO提供了6种新的AP计算方式。其中3种是通过不同的IoU来计算AP:
AP:在IoU=0.50:0.05:0.95情况下计算AP(主要挑战指标);AP@IoU=0.5:传统计算方式,和上述一致;AP@IoU=0.75:进阶难度,计算IoU>0.75的AP。
针对AP=0.5:0.05:0.95,指的是从IoU=0.5开始,每次递增0.05直到0.95大小。这样能够计算10个不同IoU阈值下的AP,完成后取均值得到最终的AP大小。
剩余3种方式的区别在于计算不同图像尺度下的AP:
AP:AP:AP:
COCO计算可以更好地区分模型性能,因为一些数据集比其他数据集有更多的小目标。
未找到相关的 Issues 进行评论
请联系 @zjykzj 初始化创建