[译]Introduction to GitLab Flow
原文地址:Introduction to GitLab Flow
Git allows a wide variety of branching strategies and workflows. Because of this, many organizations end up with workflows that are too complicated, not clearly defined, or not integrated with issue tracking systems. Therefore, we propose GitLab flow as a clearly defined set of best practices. It combines feature-driven development and feature branches with issue tracking.
Git允许多种分支策略和工作流。正因为如此,许多组织的工作流过于复杂,没有明确定义,或者没有与问题跟踪系统集成。因此,我们建议将gitlab-flow作为一组明确定义的最佳实践。它将特征驱动开发和特征分支与问题跟踪结合起来

Organizations coming to Git from other version control systems frequently find it hard to develop a productive workflow. This article describes GitLab flow, which integrates the Git workflow with an issue tracking system. It offers a simple, transparent, and effective way to work with Git.
从其他版本控制系统来到Git的组织经常发现很难开发出高效的工作流。本文描述了GitLab流程,它将Git工作流与问题跟踪系统集成在一起。它提供了使用Git的简单、透明和有效的方法
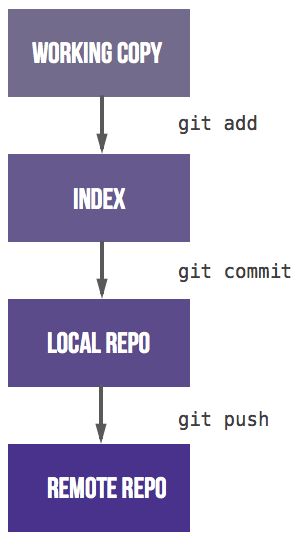
When converting to Git, you have to get used to the fact that it takes three steps to share a commit with colleagues. Most version control systems have only one step: committing from the working copy to a shared server. In Git, you add files from the working copy to the staging area. After that, you commit them to your local repo. The third step is pushing to a shared remote repository. After getting used to these three steps, the next challenge is the branching model.
在转换为Git后,您必须习惯于这样一个事实:与同事共享commit需要三个步骤。大多数版本控制系统只有一个步骤:从工作副本提交到共享服务器。在Git中,您可以将工作副本中的文件添加到临时区域。在那之后,你把它们交给你的本地仓库。第三步是推送到共享的远程存储库。在习惯了这三个步骤之后,下一个挑战是分支模型
Since many organizations new to Git have no conventions for how to work with it, their repositories can quickly become messy. The biggest problem is that many long-running branches emerge that all contain part of the changes. People have a hard time figuring out which branch has the latest code, or which branch to deploy to production. Frequently, the reaction to this problem is to adopt a standardized pattern such as Git flow and GitHub flow. We think there is still room for improvement. In this document, we describe a set of practices we call GitLab flow.
由于许多刚接触Git的组织对于如何使用它没有约定,它们的存储库很快就会变得混乱。最大的问题是出现了许多长期运行的分支,这些分支都包含了部分更改。人们很难弄清楚哪个分支有最新的代码,或者哪个分支要部署到生产环境中。通常,对这个问题的反应是采用一个标准化的模式,比如git-flow和github-flow。我们认为还有改进的余地。在本文中,我们描述了一组称为gitlab-flow的实践
Git flow and its problems
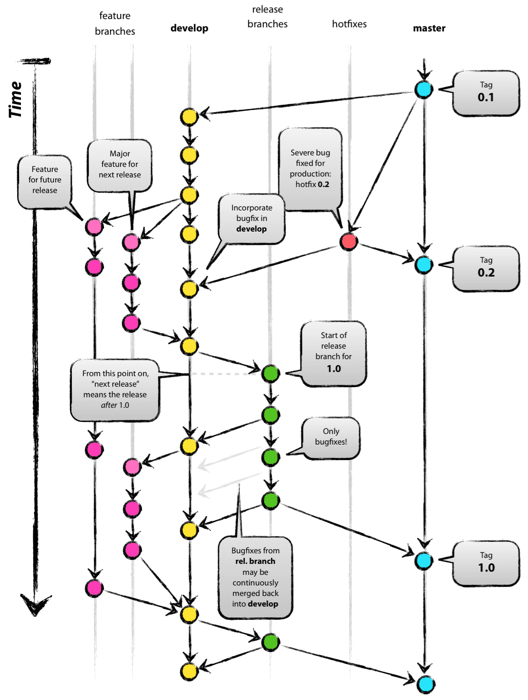
Git flow was one of the first proposals to use Git branches, and it has received a lot of attention. It suggests a master branch and a separate develop branch, as well as supporting branches for features, releases, and hotfixes. The development happens on the develop branch, moves to a release branch, and is finally merged into the master branch.
Git流是最早使用Git分支的提议之一,因此它受到了广泛的关注。它建议一个主(master)分支和一个单独的开发(develop)分支,以及功能(feature)、版本(release)和热修复(hotfix)的支持分支。开发发生在develop分支上,移动到release分支,最后合并到master分支
Git flow is a well-defined standard, but its complexity introduces two problems. The first problem is that developers must use the develop branch and not master. master is reserved for code that is released to production. It is a convention to call your default branch master and to mostly branch from and merge to this. Since most tools automatically use the master branch as the default, it is annoying to have to switch to another branch.
git-flow是一个定义明确的标准,但是它的复杂性带来了两个问题。第一个问题是开发人员必须使用develop分支,而不是master。master用于保留生产环境代码。通常情况下会调用master作为默认分支,并且大多数分支将合并到这里。由于大多数工具自动使用master分支作为默认分支,因此不得不切换到另一个分支是很烦人的
The second problem of Git flow is the complexity introduced by the hotfix and release branches. These branches can be a good idea for some organizations but are overkill for the vast majority of them. Nowadays, most organizations practice continuous delivery, which means that your default branch can be deployed. Continuous delivery removes the need for hotfix and release branches, including all the ceremony they introduce. An example of this ceremony is the merging back of release branches. Though specialized tools do exist to solve this, they require documentation and add complexity. Frequently, developers make mistakes such as merging changes only into master and not into the develop branch. The reason for these errors is that Git flow is too complicated for most use cases. For example, many projects do releases but don’t need to do hotfixes.
git-flow的第二个问题是hotfix和release分支引入的复杂性。这些分支对一些组织来说可能是个好主意,但对绝大多数组织来说却是多余的。如今,大多数组织都实行持续交付(CD),这意味着可以部署您的默认分支。持续交付消除了对hotfix和release分支的需求,包括它们引入的所有仪式。这个仪式的一个例子是release分支的合并。尽管有专门的工具来解决这个问题,但是它们需要文档并增加复杂性。开发人员经常会犯一些错误,比如只将变更合并到master中,而不合并到develop分支中。这些错误的原因是git-flow对于大多数用例来说太复杂了。例如,许多项目都发布版本,但不需要做热修复
GitHub flow as a simpler alternative
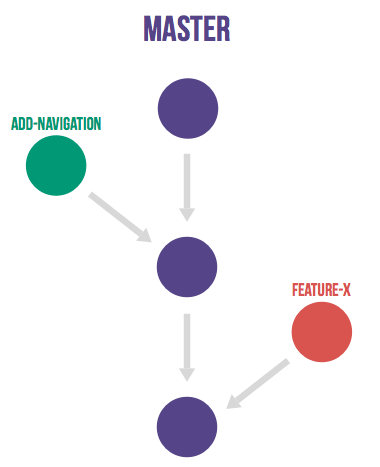
In reaction to Git flow, GitHub created a simpler alternative. GitHub flow has only feature branches and a master branch. This flow is clean and straightforward, and many organizations have adopted it with great success. Atlassian recommends a similar strategy, although they rebase feature branches. Merging everything into the master branch and frequently deploying means you minimize the amount of unreleased code, which is in line with lean and continuous delivery best practices. However, this flow still leaves a lot of questions unanswered regarding deployments, environments, releases, and integrations with issues. With GitLab flow, we offer additional guidance for these questions.
作为对git-flow的反馈,GitHub创建了一个更简单的替代方案。github-flow只有特征(feature)分支和主(master)分支。这一流程简洁明了,许多组织已经非常成功地采用了它。Atlassian推荐一个类似的策略,尽管他们会重新设置feature分支。将所有内容合并到master分支并频繁部署意味着您将未发布代码的数量降至最低,这符合精益和持续交付的最佳实践。然而,这个流程仍然有许多关于部署、环境、发布和问题集成的问题没有得到回答。通过gitlab-flow,我们为这些问题提供了额外的指导
Production branch with GitLab flow
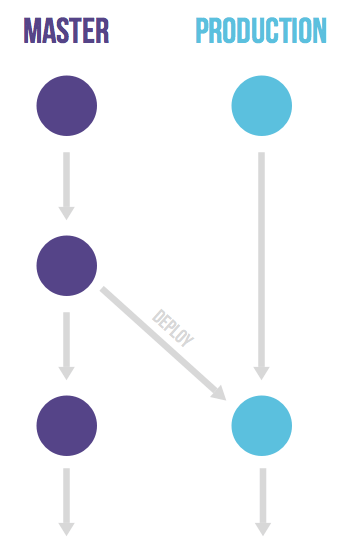
gitlab-flow的生产分支
GitHub flow assumes you can deploy to production every time you merge a feature branch. While this is possible in some cases, such as SaaS applications, there are many cases where this is not possible. One case is where you don’t control the timing of a release, for example, an iOS application that is released when it passes App Store validation. Another case is when you have deployment windows — for example, workdays from 10 AM to 4 PM when the operations team is at full capacity — but you also merge code at other times. In these cases, you can make a production branch that reflects the deployed code. You can deploy a new version by merging master into the production branch. If you need to know what code is in production, you can just checkout the production branch to see. The approximate time of deployment is easily visible as the merge commit in the version control system. This time is pretty accurate if you automatically deploy your production branch. If you need a more exact time, you can have your deployment script create a tag on each deployment. This flow prevents the overhead of releasing, tagging, and merging that happens with Git flow.
gitHub-flow假设您可以在每次合并feature分支时部署到生产环境中。虽然这在某些情况下是可能的,例如SaaS应用程序,但在许多情况下这是不可能的。一种情况是,您不能控制发布的时间,例如,当一个iOS应用程序通过应用商店验证时,它就会被发布。另一种情况是,当您有部署窗口时,例如,当操作团队满负荷时,工作日从上午10点到下午4点,但您也可以在其他时间合并代码。在这些情况下,您可以创建一个反映部署代码的生产(production)分支。您可以通过将master合并到production分支中来部署新版本。如果您需要知道生产中有什么代码,您可以只签出production分支来查看。随着版本控制系统中的合并提交,部署的大致时间是很容易看到的。如果您自动部署production分支,这一次非常准确。如果您需要更准确的时间,可以让您的部署脚本在每个部署上创建一个标签。这个流程防止了git-flow发生的发布、标记和合并的开销
Environment branches with GitLab flow
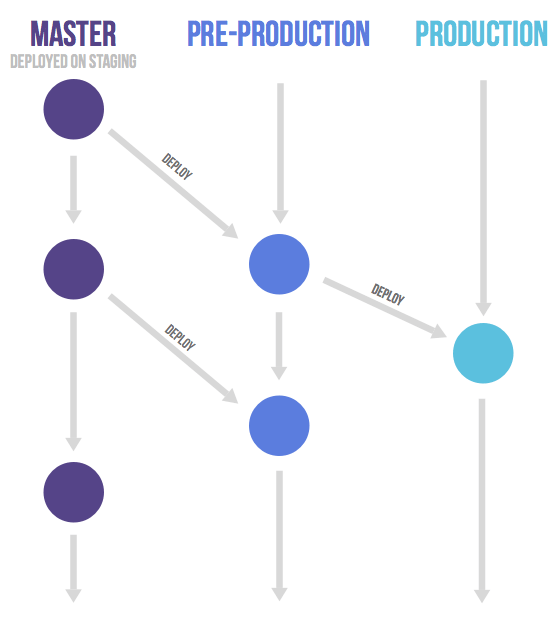
gitlab-flow的环境分支
It might be a good idea to have an environment that is automatically updated to the master branch. Only, in this case, the name of this environment might differ from the branch name. Suppose you have a staging environment, a pre-production environment, and a production environment. In this case, deploy the master branch to staging. To deploy to pre-production, create a merge request from the master branch to the pre-production branch. Go live by merging the pre-production branch into the production branch. This workflow, where commits only flow downstream, ensures that everything is tested in all environments. If you need to cherry-pick a commit with a hotfix, it is common to develop it on a feature branch and merge it into master with a merge request. In this case, do not delete the feature branch yet. If master passes automatic testing, you then merge the feature branch into the other branches. If this is not possible because more manual testing is required, you can send merge requests from the feature branch to the downstream branches.
拥有一个能够自动更新到master分支的环境可能是个好主意。仅在这种情况下,此环境的名称可能不同于分支名称。假设您有一个阶段(staging)环境、一个预生产(pre-production)环境和一个生产(production)环境。在这种情况下,将master分支部署到staging。要部署到pre-production,请创建从master分支到pre-production分支的合并请求。通过将pre-production分支合并到production分支来上线。这个工作流(提交只流向下游)确保在所有环境中测试一切。如果您需要实现一个hotfix提交,通常是在一个feature分支上开发它,并通过合并请求将其合并到master中。在这种情况下,暂时不要删除feature分支。如果master通过了自动测试,则可以将feature分支合并到其他分支中。如果因为需要更多的手动测试而无法做到这一点,您可以将合并请求从feature分支发送到下游分支
Release branches with GitLab flow
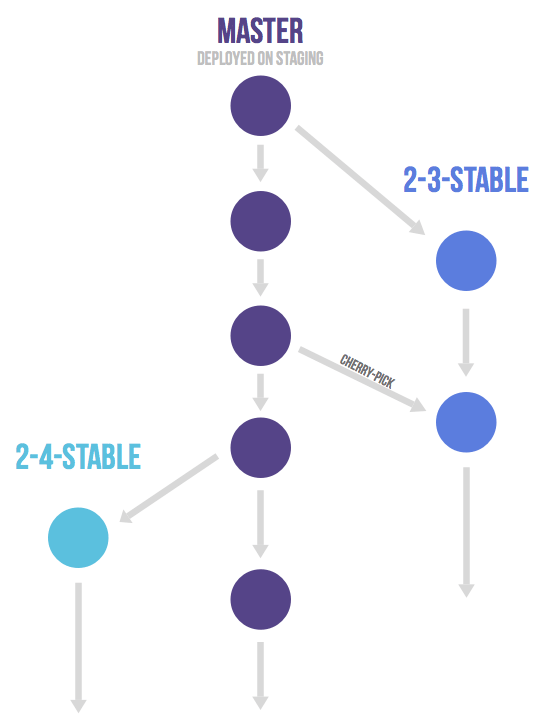
gitlab-flow的发布分支
You only need to work with release branches if you need to release software to the outside world. In this case, each branch contains a minor version, for example, 2-3-stable, 2-4-stable, etc. Create stable branches using master as a starting point, and branch as late as possible. By doing this, you minimize the length of time during which you have to apply bug fixes to multiple branches. After announcing a release branch, only add serious bug fixes to the branch. If possible, first merge these bug fixes into master, and then cherry-pick them into the release branch. If you start by merging into the release branch, you might forget to cherry-pick them into master, and then you’d encounter the same bug in subsequent releases. Merging into master and then cherry-picking into release is called an “upstream first” policy, which is also practiced by Google and Red Hat. Every time you include a bug fix in a release branch, increase the patch version (to comply with Semantic Versioning) by setting a new tag. Some projects also have a stable branch that points to the same commit as the latest released branch. In this flow, it is not common to have a production branch (or Git flow master branch).
如果你需要向外界发布软件,你只需要使用发布(release)分支。在这种情况下,每个分支包含一个次要版本,例如,2-3-稳定、2-4-稳定等。以master为起点创建稳定的分支,并尽可能晚地执行分支操作。通过这样做,您可以最大限度地减少将修复的bug应用到多个分支的时间长度。在宣布release分支后,只能给分支添加严重的bug修复。如果可能的话,首先将这些bug修复合并到master中,然后将它们合并到release分支中。如果您从合并release分支开始,您可能会忘记将它们加入master,然后您会在后续的发布中遇到相同的错误。合并到master中,然后精选到release中被称为“上游优先”政策,这也是谷歌和红帽的做法。每次在发布分支中包含bug修复时,通过设置新标签来增加补丁版本(以符合语义版本控制)。一些项目也有一个稳定的分支,指向与最新发布的分支相同的提交。在这个流程中,production分支(或git-flow master分支)并不常见
Merge/pull requests with GitLab flow
gitlab-flow的合并/拉取请求
Merge or pull requests are created in a Git management application. They ask an assigned person to merge two branches. Tools such as GitHub and Bitbucket choose the name "pull request" since the first manual action is to pull the feature branch. Tools such as GitLab and others choose the name "merge request" since the final action is to merge the feature branch. In this article, we’ll refer to them as merge requests.
合并或拉取请求是在Git管理应用程序中创建的。他们要求指定的人合并两个分支。GitHub和Bitbucket等工具选择名称“拉取请求”(pull request),因为第一个手动操作是拉取特征分支。GitLab等工具称之为“合并请求”(merge request),因为最终的操作是合并特征分支。在本文中,我们将它们称为合并请求
If you work on a feature branch for more than a few hours, it is good to share the intermediate result with the rest of the team. To do this, create a merge request without assigning it to anyone. Instead, mention people in the description or a comment, for example, “/cc @mark @susan.” This indicates that the merge request is not ready to be merged yet, but feedback is welcome. Your team members can comment on the merge request in general or on specific lines with line comments. The merge request serves as a code review tool, and no separate code review tools should be needed. If the review reveals shortcomings, anyone can commit and push a fix. Usually, the person to do this is the creator of the merge request. The diff in the merge request automatically updates when new commits are pushed to the branch.
如果您在一个feature分支上工作了几个小时以上,最好与团队的其他成员共享中间结果。为此,请创建一个合并请求,而不是直接将其分配给其他人。相反,在描述或评论中提及人,例如,“/cc @mark @susan”。这表示合并请求尚未准备好合并,但欢迎反馈。您的团队成员可以对合并请求进行一般性评论,也可以对带有行评论的特定行进行评论。合并请求用作代码审查时不需要单独的代码审查工具。如果审查发现了缺点,任何人都可以提交并推动解决方案。通常要这样做的人是合并请求的创建者。当新提交被推送到分支时,合并请求中的差异会自动更新
When you are ready for your feature branch to be merged, assign the merge request to the person who knows most about the codebase you are changing. Also, mention any other people from whom you would like feedback. After the assigned person feels comfortable with the result, they can merge the branch. If the assigned person does not feel comfortable, they can request more changes or close the merge request without merging.
当您准备好要合并的特征分支时,请将合并请求分配给最了解您正在更改的代码库的人。此外,提及你希望得到反馈的任何其他人。当被指派的人对结果感到满意后,他们可以合并分支。如果被分配的人感觉不舒服,他们可以请求更多更改或关闭合并请求而不合并
In GitLab, it is common to protect the long-lived branches, e.g., the master branch, so that most developers can’t modify them. So, if you want to merge into a protected branch, assign your merge request to someone with maintainer permissions.
在GitLab中,保护长期存在的分支是很常见的,例如master分支,这样大多数开发人员就不能修改它们。因此,如果您想合并到受保护的分支,请将合并请求分配给具有维护者权限的人
After you merge a feature branch, you should remove it from the source control software. In GitLab, you can do this when merging. Removing finished branches ensures that the list of branches shows only work in progress. It also ensures that if someone reopens the issue, they can use the same branch name without causing problems.
合并feature分支后,应将其从源代码管理软件中删除。在GitLab中,合并时可以这样做。移除已完成的分支可确保分支列表仅显示正在进行的工作。它还确保了如果有人重新打开问题,他们可以使用相同的分支名称而不会造成问题
Note: When you reopen an issue you need to create a new merge request.
注意:当你重新打开一个问题的时候,你需要重建一个新的合并请求
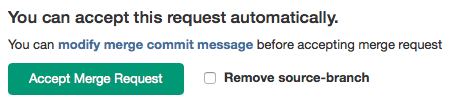
Issue tracking with GitLab flow
GitLab flow is a way to make the relation between the code and the issue tracker more transparent.
gitlab-flow是一种使代码和问题跟踪器之间的关系更加透明的方法
Any significant change to the code should start with an issue that describes the goal. Having a reason for every code change helps to inform the rest of the team and to keep the scope of a feature branch small. In GitLab, each change to the codebase starts with an issue in the issue tracking system. If there is no issue yet, create the issue, as long as the change will take a significant amount of work, i.e., more than 1 hour. In many organizations, raising an issue is part of the development process because they are used in sprint planning. The issue title should describe the desired state of the system. For example, the issue title "As an administrator, I want to remove users without receiving an error" is better than "Admin can’t remove users."
对代码的任何重大更改都应该从描述目标的问题开始。每一次代码变更都有一个原因,这有助于通知团队的其他成员,并保持一个小范围的feature分支。在GitLab中,对代码库的每次更改都从问题跟踪系统中的一个问题开始。如果还没有问题,创建问题,只要更改需要大量工作,即超过1小时即可。在许多组织中,提出问题是开发过程的一部分,因为它们用于冲刺规划。问题标题应该描述系统的期望状态。例如,问题标题“作为管理员,我希望在没有收到错误的情况下删除用户”优于“管理员不能删除用户”
When you are ready to code, create a branch for the issue from the master branch. This branch is the place for any work related to this change.
当准备好编程后,从master分支为问题创建一个分支。该分支是与此变更相关的任何工作的场所
Note: The name of a branch might be dictated by organizational standards.
注意:此分支名由组织标准决定
When you are done or want to discuss the code, open a merge request. A merge request is an online place to discuss the change and review the code.
当您完成或想要讨论代码时,请打开合并请求。合并请求是一个讨论变更和审查代码的在线场所
If you open the merge request but do not assign it to anyone, it is a "Work In Progress" merge request. These are used to discuss the proposed implementation but are not ready for inclusion in the master branch yet. Start the title of the merge request with [WIP] or WIP: to prevent it from being merged before it’s ready.
如果您打开合并请求,但没有将其分配给任何人,则它是一个“正在进行中”的合并请求。这些用于讨论提议的实施,但是还没有准备好包含在master分支中。用[WIP]或WIP:开始合并请求的标题,以防止在准备好之前将其合并
When you think the code is ready, assign the merge request to a reviewer. The reviewer can merge the changes when they think the code is ready for inclusion in the master branch. When they press the merge button, GitLab merges the code and creates a merge commit that makes this event easily visible later on. Merge requests always create a merge commit, even when the branch could be merged without one. This merge strategy is called “no fast-forward” in Git. After the merge, delete the feature branch since it is no longer needed. In GitLab, this deletion is an option when merging.
当您认为代码准备就绪时,请将合并请求分配给审阅者。当审阅者认为代码可以包含在master分支中时,他们可以合并这些更改。当他们按下合并按钮时,GitLab会合并代码并创建一个合并提交,这样以后就可以很容易地看到这个事件。合并请求总是创建合并提交,即使分支可以在没有合并提交的情况下进行合并。这种合并策略在Git中被称为“无快进”(no fast-forward)。合并后,删除feature分支,因为不再需要它。在GitLab中,这种删除是合并时的一个选项
Suppose that a branch is merged but a problem occurs and the issue is reopened. In this case, it is no problem to reuse the same branch name since the first branch was deleted when it was merged. At any time, there is at most one branch for every issue. It is possible that one feature branch solves more than one issue.
假设一个分支被合并,但出现了一个问题,该问题被重新打开。在这种情况下,重用相同的分支名称没有问题,因为第一个分支在合并时被删除了。在任何时候,每个问题最多只有一个分支。一个feature分支可能解决多个问题
Linking and closing issues from merge requests
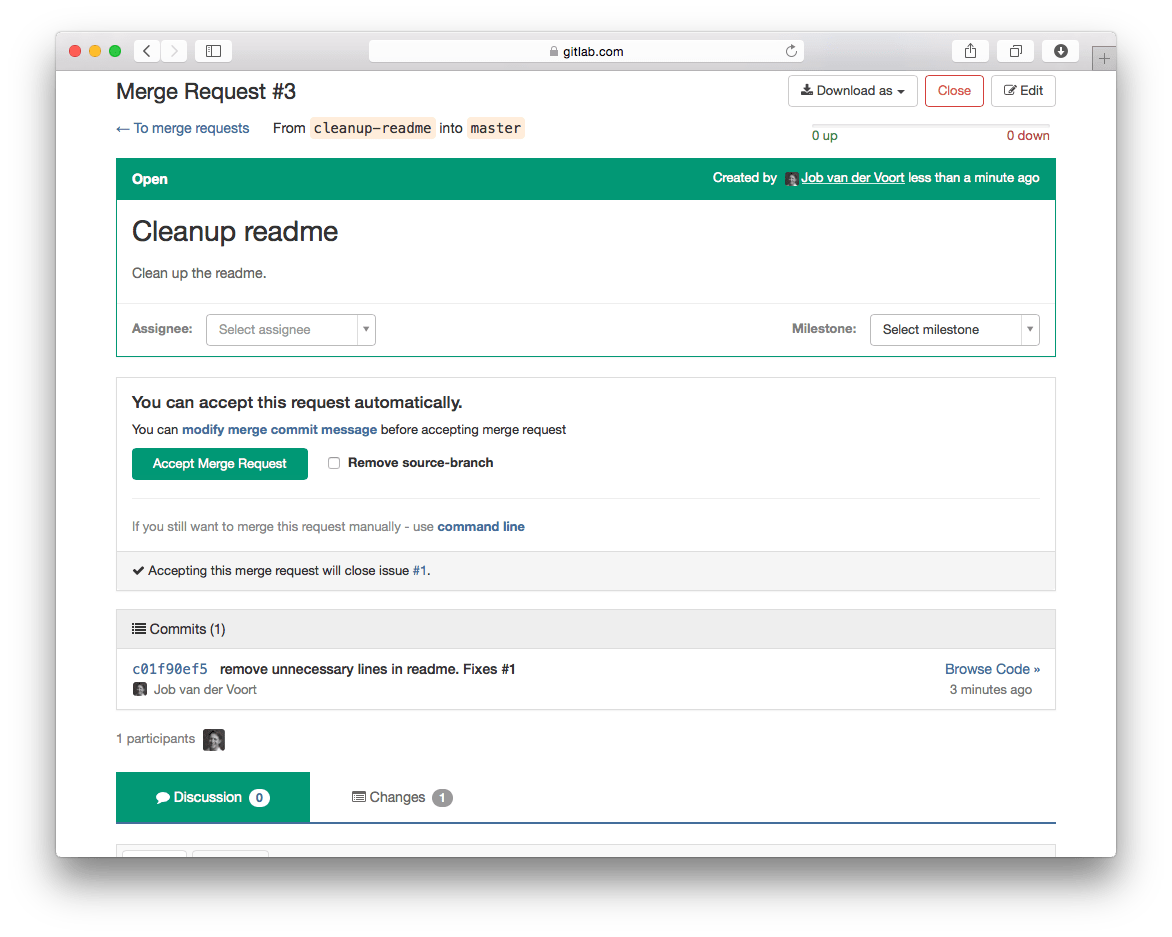
从合并请求中链接和关闭问题
Link to issues by mentioning them in commit messages or the description of a merge request, for example, "Fixes #16" or "Duck typing is preferred. See #12." GitLab then creates links to the mentioned issues and creates comments in the issues linking back to the merge request.
通过在提交消息或合并请求的描述中提及问题来链接到问题,例如,“修复#16”或“Duck typing is preferred. See #12.”。GitLab然后创建指向上述问题的链接,并在链接回合并请求的问题中创建注释
To automatically close linked issues, mention them with the words “fixes” or “closes,” for example, “fixes #14” or “closes #67.” GitLab closes these issues when the code is merged into the default branch.
要自动关闭链接的问题,请用“fixes”或“closes”来提及它们,例如,“fixes #14”或“closes #67”。当代码被合并到默认分支时,GitLab会关闭这些问题
If you have an issue that spans across multiple repositories, create an issue for each repository and link all issues to a parent issue.
如果问题跨越多个存储库,请为每个存储库创建一个问题,并将所有问题链接到父问题
Squashing commits with rebase
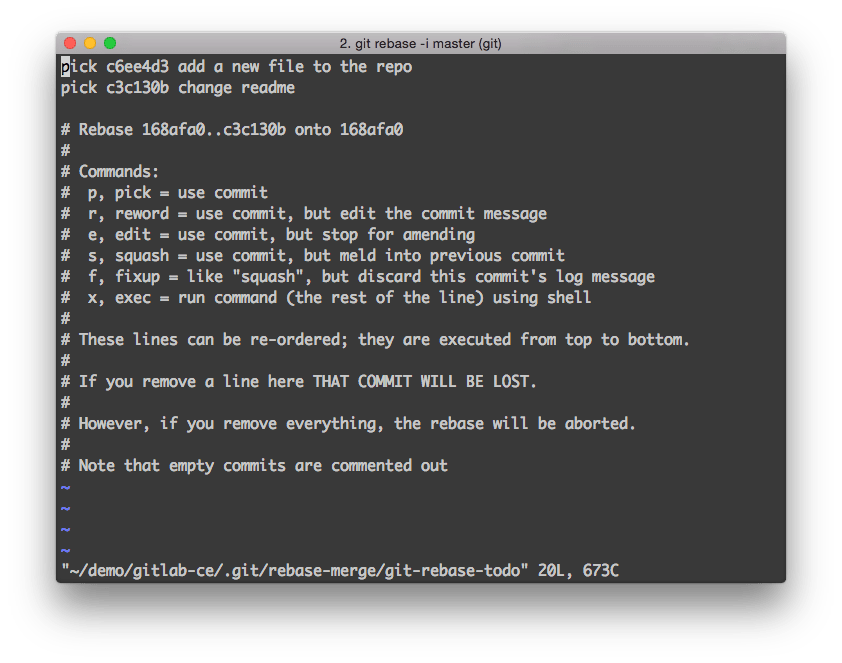
With Git, you can use an interactive rebase (rebase -i) to squash multiple commits into one or reorder them. This functionality is useful if you want to replace a couple of small commits with a single commit, or if you want to make the order more logical.
使用Git,您可以使用交互式基础(rebase -i)将多个提交压缩成一个或重新排序。如果您想用单个提交替换几个小提交,或者如果您想使顺序更符合逻辑,此功能非常有用
However, you should never rebase commits you have pushed to a remote server. Rebasing creates new commits for all your changes, which can cause confusion because the same change would have multiple identifiers. It also causes merge errors for anyone working on the same branch because their history would not match with yours. Also, if someone has already reviewed your code, rebasing makes it hard to tell what changed since the last review.
但是,您永远不应该将您已推送至远程服务器的提交进行rebase。rebase会为您的所有更改创建新的提交,这可能会导致混淆,因为相同的更改会有多个标识符。它还会导致在同一分支上工作的其他人出现合并错误,因为他们的历史记录与您的不匹配。此外,如果有人已经审查了您的代码,那么rebase会使您很难判断自上次审查以来发生了什么变化
You should also never rebase commits authored by other people. Not only does this rewrite history, but it also loses authorship information. Rebasing prevents the other authors from being attributed and sharing part of the
git blame.
您也不应该改变由其他人编写的提交。这不仅重写了历史,而且还丢失了作者信息。Rebasing prevents the other authors from being attributed and sharing part of the git blame
If a merge involves many commits, it may seem more difficult to undo. You might think to solve this by squashing all the changes into one commit before merging, but as discussed earlier, it is a bad idea to rebase commits that you have already pushed. Fortunately, there is an easy way to undo a merge with all its commits. The way to do this is by reverting the merge commit. Preserving this ability to revert a merge is a good reason to always use the “no fast-forward” (--no-ff) strategy when you merge manually.
如果合并涉及许多提交,那么撤销可能会更加困难。您可能会想在合并前将所有更改压缩成一个提交来解决这个问题,但是如前所述,rebase您已经推动的提交的基础是一个坏主意。幸运的是,有一种简单的方法可以撤消与其所有提交的合并。方法是恢复合并提交。保留这种恢复合并的能力是在手动合并时始终使用“无快进”(--no-ff)策略的一个很好的理由
Note: If you revert a merge commit and then change your mind, revert the revert commit to redo the merge. Git does not allow you to merge the code again otherwise.
注意:如果您回复合并提交,然后改变主意,请恢复提交以重做合并。否则Git不允许您再次合并代码
Reducing merge commits in feature branches

减少特征分支的合并提交
Having lots of merge commits can make your repository history messy. Therefore, you should try to avoid merge commits in feature branches. Often, people avoid merge commits by just using rebase to reorder their commits after the commits on the master branch. Using rebase prevents a merge commit when merging master into your feature branch, and it creates a neat linear history. However, as discussed in the section about rebasing, you should never rebase commits you have pushed to a remote server. This restriction makes it impossible to rebase work in progress that you already shared with your team, which is something we recommend.
有很多合并提交会使您的存储库历史变得混乱。因此,您应该尽量避免在feature分支中进行合并提交。通常,人们通过在master分支上提交之后使用rebase来重新排序提交来避免合并提交。使用rebase可防止在将master合并到feature分支时进行合并提交,并创建整洁的线性历史。但是,正如rebase一节中讨论的,您永远不应该rebase您已经推送到远程服务器的提交。这一限制使得您无法对已经与您的团队共享的正在进行的工作进行重定基准,这是我们推荐的
Rebasing also creates more work, since every time you rebase, you have to resolve similar conflicts. Sometimes you can reuse recorded resolutions (rerere), but merging is better since you only have to resolve conflicts once. Atlassian has a more thorough explanation of the tradeoffs between merging and rebasing on their blog.
重定基准也会产生更多的工作,因为每次重定基准时,都必须解决类似的冲突。有时您可以重用ecorded resolutions(rerere),但是合并更好的选择,因为您只需解决一次冲突。Atlassian在他们的博客上对合并和重定基础之间的权衡有更透彻的解释
A good way to prevent creating many merge commits is to not frequently merge master into the feature branch. There are three reasons to merge in master: utilizing new code, resolving merge conflicts, and updating long-running branches.
防止创建许多合并提交的一个好方法是不要频繁地将master合并到feature分支中。在master中合并有三个原因:使用新代码、解决合并冲突和更新长期运行的分支
If you need to utilize some code that was introduced in master after you created the feature branch, you can often solve this by just cherry-picking a commit.
如果您需要利用在创建feature分支后master新引入的一些代码,您通常可以通过挑选提交来解决这个问题
If your feature branch has a merge conflict, creating a merge commit is a standard way of solving this.
如果您的feature分支有合并冲突,创建合并提交是解决这一问题的标准方法
Note: Sometimes you can use .gitattributes to reduce merge conflicts. For example, you can set your changelog file to use the union merge driver so that multiple new entries don’t conflict with each other.
注意:有时你可以使用.gitattributes文件来减少合并冲突。例如,您可以变更日志文件以使用联合合并驱动程序,以便多个新条目不会相互冲突
The last reason for creating merge commits is to keep long-running feature branches up-to-date with the latest state of the project. The solution here is to keep your feature branches short-lived. Most feature branches should take less than one day of work. If your feature branches often take more than a day of work, try to split your features into smaller units of work.
创建合并提交的最后一个原因是让长期运行的功能分支与项目的最新状态保持同步。这里的解决方案是让您的feature分支仅有短暂生命周期。大多数feature分支应该不到一天的工作时间。如果您的feature分支经常需要一天以上的工作时间,请尝试将您的功能分成更小的工作单元
If you need to keep a feature branch open for more than a day, there are a few strategies to keep it up-to-date. One option is to use continuous integration (CI) to merge in master at the start of the day. Another option is to only merge in from well-defined points in time, for example, a tagged release. You could also use feature toggles to hide incomplete features so you can still merge back into master every day.
如果您需要让一个feature分支保持开放一天以上,有几种策略可以让它保持最新。一种选择是在一天开始时使用连续集成(CI)合并到主服务器中。另一种选择是只从定义明确的时间点合并进来,例如,标记的版本。您也可以使用功能切换来隐藏不完整的功能,这样您仍然可以每天合并回master
Note: Don’t confuse automatic branch testing with continuous integration. Martin Fowler makes this distinction in his article about feature branches:
“I’ve heard people say they are doing CI because they are running builds, perhaps using a CI server, on every branch with every commit. That’s continuous building, and a Good Thing, but there’s no integration, so it’s not CI.”
注意:不要混淆自动分支测试和持续集成。马丁·福勒在他关于特征分支的文章中做了这样的区分
"我听人们说他们在做CI,因为他们在每个分支上提交时运行构建程序,可能使用CI服务器。这种持续构建是一件好事,但是没有集成,所以它不是CI。"
In conclusion, you should try to prevent merge commits, but not eliminate them. Your codebase should be clean, but your history should represent what actually happened. Developing software happens in small, messy steps, and it is OK to have your history reflect this. You can use tools to view the network graphs of commits and understand the messy history that created your code. If you rebase code, the history is incorrect, and there is no way for tools to remedy this because they can’t deal with changing commit identifiers.
总之,您应该尝试预防合并提交,但不要消除它们。您的代码库应该是干净的,但是您的历史应该代表实际发生的事情。软件开发是以小而混乱的步骤进行的,让你的历史来反映这一点是可以的。您可以使用工具查看提交的网络图,并理解创建代码的混乱历史。如果您重新设置代码的基础,历史是不正确的,并且工具没有办法补救这一点,因为它们不能处理更改提交标识符
Commit often and push frequently
经常提交以及频繁推送
Another way to make your development work easier is to commit often. Every time you have a working set of tests and code, you should make a commit. Splitting up work into individual commits provides context for developers looking at your code later. Smaller commits make it clear how a feature was developed, and they make it easy to roll back to a specific good point in time or to revert one code change without reverting several unrelated changes.
让你的开发工作更容易的另一个方法是经常提交。每次你有了一套测试和代码后就应该提交。将工作划分成单次提交为以后开发人员查看您的代码提供了环境。较小的提交可以清楚地说明一个特征是如何开发的,并且可以很容易地回滚到一个特定的好时间点,或者在不需要恢复几个更改的情况下恢复一个代码更改
Committing often also makes it easy to share your work, which is important so that everyone is aware of what you are working on. You should push your feature branch frequently, even when it is not yet ready for review. By sharing your work in a feature branch or a merge request, you prevent your team members from duplicating work. Sharing your work before it’s complete also allows for discussion and feedback about the changes, which can help improve the code before it gets to review.
提交也会使得工作分享变得容易,这很重要,这样每个人都知道你在做什么。您应该经常推动您的feature分支,即使它还没有准备好进行审查。通过在feature分支或合并请求中共享您的工作,您可以防止团队成员重复工作。在工作完成之前共享您的工作还允许对变更进行讨论和反馈,这有助于在代码评审之前对其进行改进
How to write a good commit message
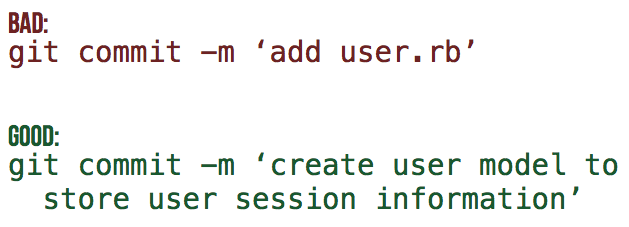
A commit message should reflect your intention, not just the contents of the commit. It is easy to see the changes in a commit, so the commit message should explain why you made those changes. An example of a good commit message is: "Combine templates to reduce duplicate code in the user views." The words "change," "improve," “fix,” and “refactor” don’t add much information to a commit message. For example, “Improve XML generation” could be better written as “Properly escape special characters in XML generation.” For more information about formatting commit messages, please see this excellent blog post by Tim Pope
提交消息应该反映您的意图,而不仅仅是提交的内容。很容易看到提交中的更改,所以提交消息应该解释您为什么做出这些更改。一个好的提交消息的例子是:“组合模板以减少用户视图中的重复代码”。关键字“改变”、“改进”、“修复”和“重构”这些词不会给提交消息添加太多信息。例如,“改进XML生成”可以更好地写成“在XML生成中正确转义特殊字符”。有关格式化提交消息的更多信息,请参见蒂姆·波普的这篇精彩博客文章
Testing before merging
合并前测试
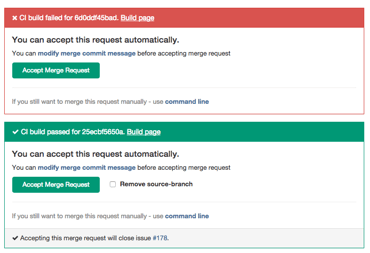
In old workflows, the continuous integration (CI) server commonly ran tests on the master branch only. Developers had to ensure their code did not break the master branch. When using GitLab flow, developers create their branches from this master branch, so it is essential that it never breaks. Therefore, each merge request must be tested before it is accepted. CI software like Travis CI and GitLab CI show the build results right in the merge request itself to make this easy.
在旧的工作流中,连续集成服务器通常只在master分支上运行测试。开发人员必须确保他们的代码不会破坏master分支。当使用GitLab流时,开发人员从master分支创建他们的分支,所以它永远不会中断是非常重要的。因此,在接受每个合并请求之前,必须对其进行测试。像Travis CI和GitLab CI这样的CI软件会在合并请求本身中显示构建结果,以便于实现
There is one drawback to testing merge requests: the CI server only tests the feature branch itself, not the merged result. Ideally, the server could also test the master branch after each change. However, retesting on every commit to master is computationally expensive and means you are more frequently waiting for test results. Since feature branches should be short-lived, testing just the branch is an acceptable risk. If new commits in master cause merge conflicts with the feature branch, merge master back into the branch to make the CI server re-run the tests. As said before, if you often have feature branches that last for more than a few days, you should make your issues smaller.
测试合并请求有一个缺点:CI服务器只测试feature分支本身,而不测试合并结果。理想情况下,服务器也可以在每次更改后测试master分支。然而,每次提交给master时重新测试计算量很大,这意味着您更频繁地等待测试结果。因为feature分支应该是短期的,所以只测试分支是可以接受的风险。如果master服务器中的新提交导致与feature分支的合并冲突,请将master服务器合并回分支,以使CI服务器重新运行测试。如前所述,如果您经常有持续几天以上的feature分支,您应该将问题变小
Working with feature branches
使用特征分支工作
When creating a feature branch, always branch from an up-to-date master. If you know before you start that your work depends on another branch, you can also branch from there. If you need to merge in another branch after starting, explain the reason in the merge commit. If you have not pushed your commits to a shared location yet, you can also incorporate changes by rebasing on master or another feature branch. Do not merge from upstream again if your code can work and merge cleanly without doing so. Merging only when needed prevents creating merge commits in your feature branch that later end up littering the master history.
创建feature分支时,始终使用最新的master分支代码。如果你在开始工作前知道你的工作依赖于另一个分支,你也可以从那个分支fork。如果启动后需要合并到另一个分支,请在合并提交中解释原因。如果您尚未将提交推送到共享位置,也可以通过在master分支或另一个feature分支上rebase合并更改。如果您的代码可以在不合并的情况下干净地工作和合并,请不要再从上游合并。只有在需要时合并才能防止在您的feature分支中创建合并提交,而合并提交最终会丢弃master历史记录
未找到相关的 Issues 进行评论
请联系 @zjykzj 初始化创建