[译]Fast R-CNN
原文地址:Fast R-CNN
Fast R-CNN在R-CNN的基础上进一步发展,充分利用卷积神经网络进行目标检测和分类
Abstract
This paper proposes a Fast Region-based Convolutional Network method (Fast R-CNN) for object detection. Fast R-CNN builds on previous work to efficiently classify object proposals using deep convolutional networks. Compared to previous work, Fast R-CNN employs several innovations to improve training and testing speed while also increasing detection accuracy. Fast R-CNN trains the very deep VGG16 network 9× faster than R-CNN, is 213× faster at test-time, and achieves a higher mAP on PASCAL VOC 2012. Compared to SPPnet, Fast R-CNN trains VGG16 3×faster, tests 10× faster, and is more accurate. Fast R-CNN is implemented in Python and C++ (using Caffe) and is available under the open-source MIT License at https://github.com/rbgirshick/fast-rcnn.
本文提出一种快速的基于区域的卷积神经网络目标检测方法(Fast R-CNN)。Fast R-CNN在之前工作的基础上,利用深度卷积神经网络对目标方案进行有效分类。与以往的工作相比,Fast R-CNN在提高训练和测试速度的同时,也提高了检测精度。Fast R-CNN使用VGG16网络,训练速度比R-CNN快9倍,测试速度快213倍,同时在PASCAL VOC 2012上实现了更高的mAP。和SPPnet相比,Fast R-CNN使用VGG16网络,训练速度快3倍,测试速度快10倍,同时更加精确。Fast RCNN已在Python和C++中实现(使用Caffe),基于开放源码MIT许可下使用:https://github.com/rbgirshick/fast-rcnn
Introduction
Recently, deep ConvNets [14, 16] have significantly improved image classification [14] and object detection [9, 19] accuracy. Compared to image classification, object detection is a more challenging task that requires more complex methods to solve. Due to this complexity, current approaches (e.g., [9, 11, 19, 25]) train models in multi-stage pipelines that are slow and inelegant.
最近一段时间,深度卷积网络[14, 16]显著提高了图像分类[14]和目标检测[9, 19]精度。和图像分类相比,目标检测是更有挑战性的任务,需要更多的复杂方法去解决。由于这种复杂性,目前使用多阶段流水线的训练模型方法(例如,[9, 11, 19,25])显得缓慢并且不优雅
Complexity arises because detection requires the accurate localization of objects, creating two primary challenges. First, numerous candidate object locations (often called “proposals”) must be processed. Second, these candidates provide only rough localization that must be refined to achieve precise localization. Solutions to these problems often compromise speed, accuracy, or simplicity.
复杂性是因为检测需要精确定位目标,从而产生两个主要挑战。首先,必须处理许多候选目标位置(通常称为“建议”)。其次,这些候选建议只提供粗略的定位,必须对其进行改进才能实现精确的定位。这些问题的解决方案往往会影响速度、准确性或简单性
In this paper, we streamline the training process for state-of-the-art ConvNet-based object detectors [9, 11]. We propose a single-stage training algorithm that jointly learns to classify object proposals and refine their spatial locations.
在本文中,我们简化了最好的基于ConvNet的目标检测器的训练过程[9,11]。我们提出一个单阶段训练算法,共同学习分类目标建议并细化其空间位置
The resulting method can train a very deep detection network (VGG16 [20]) 9× faster than R-CNN [9] and 3×faster than SPPnet [11]. At runtime, the detection network processes images in 0.3s (excluding object proposal time) while achieving top accuracy on PASCAL VOC 2012 [7] with a mAP of 66% (vs. 62% for R-CNN).{1}
本文最后通过训练一个极深检测网络(VGG16[20]),9倍快于R-CNN[9],3倍快于SPPnet[11]。在运行阶段,检测网络每0.3秒处理一张图像(去除目标建议时间),同时在PASCAL VOC 2012[7]上实现了66%的最高精度(vs. R-CNN有62%){1}
{1}:All timings use one Nvidia K40 GPU overclocked to 875 MHz.
所有计时使用一块Nvidia K40 GPU,超频至875 MHz
R-CNN and SPPnet
The Region-based Convolutional Network method (RCNN) [9] achieves excellent object detection accuracy by using a deep ConvNet to classify object proposals. R-CNN, however, has notable drawbacks:
基于区域的卷积网络方法(RCNN)[9]通过使用深度卷积网络来分类目标建议,实现了极高的目标检测精度。然而,R-CNN存在以下缺陷:
- Training is a multi-stage pipeline. R-CNN first fine-tunes a ConvNet on object proposals using log loss. Then, it fits SVMs to ConvNet features. These SVMs act as object detectors, replacing the softmax classifier learnt by fine-tuning. In the third training stage, bounding-box regressors are learned.
- Training is expensive in space and time. For SVM and bounding-box regressor training, features are extracted from each object proposal in each image and written to disk. With very deep networks, such as VGG16, this process takes 2.5 GPU-days for the 5k images of the VOC07 trainval set. These features require hundreds of gigabytes of storage.
- Object detection is slow. At test-time, features are extracted from each object proposal in each test image. Detection with VGG16 takes 47s / image (on a GPU).
- 训练是一个多阶段的过程。R-CNN首先使用log loss对卷积网络进行微调,然后通过卷积特征训练SVM。SVM作为目标检测器取代了通过微调学习的softmax分类器。在第三个训练阶段,学习边界框回归
- 训练在空间和时间上都很昂贵。对于支持向量机(SVM)和边界框回归器(bounding box regressor)训练,从每个图像中的每个目标建议中提取特征并写入磁盘。对于极深网络,例如VGG16,这个过程需要2.5 GPU/天来处理VOC07来学习5k大小的trainval图像。这些功能需要数百GB的存储空间
- 目标检测速度慢。在测试时,从每个测试图像中的每个目标建议中提取特征。用VGG16检测需要47s/图像(在GPU上)
R-CNN is slow because it performs a ConvNet forward pass for each object proposal, without sharing computation. Spatial pyramid pooling networks (SPPnets) [11] were proposed to speed up R-CNN by sharing computation. The SPPnet method computes a convolutional feature map for the entire input image and then classifies each object proposal using a feature vector extracted from the shared feature map. Features are extracted for a proposal by maxpooling the portion of the feature map inside the proposal into a fixed-size output (e.g., 6 × 6). Multiple output sizes are pooled and then concatenated as in spatial pyramid pooling [15]. SPPnet accelerates R-CNN by 10 to 100× at test time. Training time is also reduced by 3× due to faster proposal feature extraction.
R-CNN的速度很慢,因为它对每个目标建议执行前向计算,但没有共享计算。空间金字塔池化网络(SPPnet)[11]通过共享计算来加速R-CNN。SPPnet方法计算整个输入图像的卷积特征图,然后使用从共享特征图中提取的特征向量对每个目标建议进行分类。对共享特征图中提取属于候选建议的特征,并进行max池化操作,得到固定长度的特征向量(例如6×6)。多个输出大小被池化后连接起来[15]。SPPnet使R-CNN在测试时加速10~100倍。由于更快的建议特征提取,训练时间也减少了3倍
SPPnet also has notable drawbacks. Like R-CNN, training is a multi-stage pipeline that involves extracting features, fine-tuning a network with log loss, training SVMs, and finally fitting bounding-box regressors. Features are also written to disk. But unlike R-CNN, the fine-tuning algorithm proposed in [11] cannot update the convolutional layers that precede the spatial pyramid pooling. Unsurprisingly, this limitation (fixed convolutional layers) limits the accuracy of very deep networks.
SPPnet同样存在显著的缺陷。和R-CNN一样,训练过程是一个多阶段流水线,包含了特征提取,使用log loss微调网络,训练SVM以及最后的边界框回归器学习。提取的特征也要写入磁盘。但与R-CNN不同的是,[11]提出的微调算法不能更新空间金字塔池之前的卷积层。毫不奇怪,这种限制(固定卷积层)限制了极深网络的精度
Contributions
We propose a new training algorithm that fixes the disadvantages of R-CNN and SPPnet, while improving on their speed and accuracy. We call this method Fast R-CNN because it's comparatively fast to train and test. The Fast R-CNN method has several advantages: 1. Higher detection quality (mAP) than R-CNN, SPPnet 2. Training is single-stage, using a multi-task loss 3. Training can update all network layers 4. No disk storage is required for feature caching
我们提出了一个新的训练算法,修复了R-CNN和SPPnet的缺点,同时提高了它们的速度和准确度。我们称它为Fast R-CNN(因为足够快)。Fast R-CNN方法有以下几个优点:
- 比R-CNN,SPPnet更高的检测精度(mAP)
- 训练只需一个阶段(使用一个多任务loss)
- 训练可以更新所有的网络层
- 不需要缓存特征
Fast R-CNN is written in Python and C++ (Caffe [13]) and is available under the open-source MIT License at https://github.com/rbgirshick/fast-rcnn.
Fast R-CNN已使用Python和C++(Caffe [13])实现,基于MIT协议开源:https://github.com/rbgirshick/fast-rcnn
Fast R-CNN architecture and training
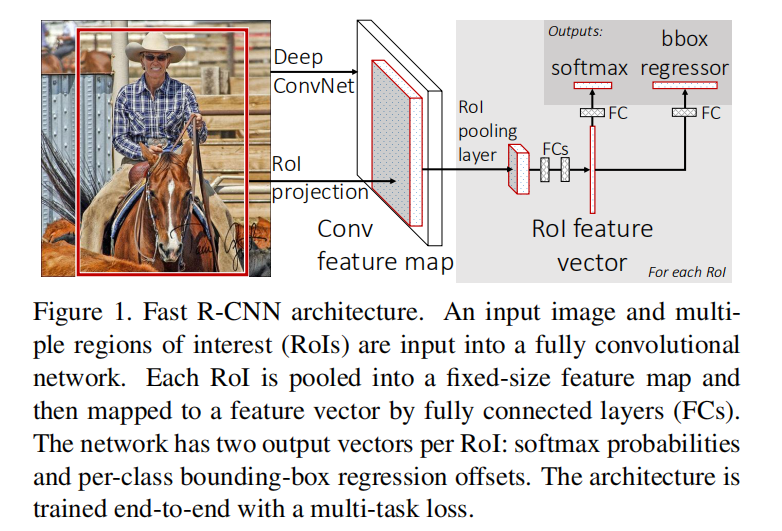
Figure 1. Fast R-CNN architecture. An input image and multiple regions of interest (RoIs) are input into a fully convolutional network. Each RoI is pooled into a fixed-size feature map and then mapped to a feature vector by fully connected layers (FCs). The network has two output vectors per RoI: softmax probabilities and per-class bounding-box regression offsets. The architecture is trained end-to-end with a multi-task loss.
图1。Fast R-CNN架构。将输入图像和多个感兴趣区域(ROIs)输入到卷积网络中。每个感兴趣区域被池化成一个固定大小的特征图,然后通过全连接层(FCs)映射到一个特征向量。每个RoI有两个输出向量:softmax概率和类边界框回归偏移。该体系结构是端到端训练的,使用多任务loss
Fig. 1 illustrates the Fast R-CNN architecture. A Fast R-CNN network takes as input an entire image and a set of object proposals. The network first processes the whole image with several convolutional (conv) and max pooling layers to produce a conv feature map. Then, for each object proposal a region of interest (RoI) pooling layer extracts a fixed-length feature vector from the feature map. Each feature vector is fed into a sequence of fully connected (fc) layers that finally branch into two sibling output layers: one that produces softmax probability estimates over K object classes plus a catch-all “background” class and another layer that outputs four real-valued numbers for each of the K object classes. Each set of 4 values encodes refined bounding-box positions for one of the K classes.
图1说明了Fast R-CNN架构。Fast R-CNN将一个完整图像和一组目标建议作为输入。网络首先处理整个图像,经过几个卷积层和最大池化层,生成一个卷积特征图。然后,对于每个目标提议,感兴趣区域(RoI)池化层从特征图中提取固定长度的特征向量。每个特征向量被输入到一系列完全连接层中(fc),这些层最终分支到两个同级输出层:一个在K个目标类加上一个"背景"类上生成softmax概率估计,另一层为每个目标类输出四个实值,进行精确的边界框位置编码
The RoI pooling layer
The RoI pooling layer uses max pooling to convert the features inside any valid region of interest into a small feature map with a fixed spatial extent of H × W (e.g., 7 × 7), where H and W are layer hyper-parameters that are independent of any particular RoI. In this paper, an RoI is a rectangular window into a conv feature map. Each RoI is defined by a four-tuple (r, c, h, w) that specifies its top-left corner (r, c) and its height and width (h, w).
RoI池化层使用max池化将任何有效感兴趣区域内的特征转换为固定空间范围为H×W(如7×7)的小特征图,其中H和W是独立于任何特定RoI的层超参数。在本文中,RoI是一个从卷积特征图中得到的矩形窗口。每个RoI由一个四元组(r,c,h,w)定义,该元组指定其左上角(r,c)及其高度和宽度(h,w)
RoI max pooling works by dividing the h × w RoI window into an H × W grid of sub-windows of approximate size h/H × w/W and then max-pooling the values in each sub-window into the corresponding output grid cell. Pooling is applied independently to each feature map channel, as in standard max pooling. The RoI layer is simply the special-case of the spatial pyramid pooling layer used in SPPnets [11] in which there is only one pyramid level. We use the pooling sub-window calculation given in [11].
RoI最大池化操作通过将h×w大小RoI窗口划分为H×W个网格,每个网格的近似大小为h/H×w/W,然后对每个子窗口进行最大池化操作,最后汇集到相应的输出网格单元中(所以最后得到的输出大小为HxW)。池化独立应用于每个特征图通道,如标准最大池化。RoI层只是SPPnets[11]中使用的空间金字塔池化层的特例,其中只有一个金字塔层。我们使用[11]中给出的池化子窗口进行计算
Initializing from pre-trained networks
We experiment with three pre-trained ImageNet [4] networks, each with five max pooling layers and between five and thirteen conv layers (see Section 4.1 for network details). When a pre-trained network initializes a Fast R-CNN network, it undergoes three transformations.
我们使用三个预训练的ImageNet[4]网络进行实验,每个网络都有五个最大池化层,并且在五到十三个conv层之间(网络详细信息见第4.1节)。当一个预训练的网络初始化Fast R-CNN网络时,它会经历三个转变
First, the last max pooling layer is replaced by a RoI pooling layer that is configured by setting H and W to be compatible with the net's first fully connected layer (e.g., H = W = 7 for VGG16).
首先,将最后一个最大池化层替换为RoI池化层,RoI池化层通过将H和W设置为与网络的第一个完全连接层兼容而配置(例如,对于VGG16,H=W=7)
Second, the network’s last fully connected layer and softmax (which were trained for 1000-way ImageNet classification) are replaced with the two sibling layers described earlier (a fully connected layer and softmax over K + 1 categories and category-specific bounding-box regressors).
其次,网络的最后一个完全连接层和softmax(ImageNet1000类)被替换为前面描述的两个兄弟层(作用于K+1类的完全连接层和softmax以及特定类别的边界框回归器)
Third, the network is modified to take two data inputs: a list of images and a list of RoIs in those images.
最后,网络被修改为接受两个数据输入:一个图像列表和这些图像中的roi列表
Fine-tuning for detection
Training all network weights with back-propagation is an important capability of Fast R-CNN. First, let’s elucidate why SPPnet is unable to update weights below the spatial pyramid pooling layer.
利用反向传播训练所有网络权值是Fast R-CNN的一项重要性能。首先,让我们解释一下SPPnet为什么不能更新空间金字塔池化层下面的权重
The root cause is that back-propagation through the SPP layer is highly inefficient when each training sample (i.e. RoI) comes from a different image, which is exactly how R-CNN and SPPnet networks are trained. The inefficiency stems from the fact that each RoI may have a very large receptive field, often spanning the entire input image. Since the forward pass must process the entire receptive field, the training inputs are large (often the entire image).
根本原因是,当每个训练样本(即RoI)来自不同的图像时,通过SPP层的反向传播效率很低,这正是R-CNN和SPPnet网络的训练方式。效率低下的原因是每个RoI可能有一个非常大的感受野,通常横跨整个输入图像。因为前向操作必须处理整个感受野,所以训练输入很大(通常是整个图像)
We propose a more efficient training method that takes advantage of feature sharing during training. In Fast RCNN training, stochastic gradient descent (SGD) mini-batches are sampled hierarchically, first by sampling N images and then by sampling R/N RoIs from each image. Critically, RoIs from the same image share computation and memory in the forward and backward passes. Making N small decreases mini-batch computation. For example, when using N = 2 and R = 128, the proposed training scheme is roughly 64× faster than sampling one RoI from 128 different images (i.e., the R-CNN and SPPnet strategy).
我们提出了一种更有效的训练方法,利用训练过程中的特征共享。在Fast RCNN训练中进行小批量随机梯度下降(SGD)分层采样,首先采样N幅图像,然后对每幅图像的R/N个RoI进行采样。关键是来自同一图像的RoI在前向和反向计算的过程中共享计算和内存。降低参数N会减少小批量计算。例如,当使用N=2和R=128时,所提出的训练方案大约比从128个不同图像(即R-CNN和SPPnet策略)中采样一个RoI快64倍
One concern over this strategy is it may cause slow training convergence because RoIs from the same image are correlated. This concern does not appear to be a practical issue and we achieve good results with N = 2 and R = 128 using fewer SGD iterations than R-CNN.
该策略的一个问题是,由于来自同一图像的RoI是相关的,因此可能导致训练收敛缓慢。这种担心似乎不是一个实际的问题,我们在N=2和R=128下使用比R-CNN更少的SGD迭代获得了良好的结果
In addition to hierarchical sampling, Fast R-CNN uses a streamlined training process with one fine-tuning stage that jointly optimizes a softmax classifier and bounding-box regressors, rather than training a softmax classifier, SVMs, and regressors in three separate stages [9, 11]. The components of this procedure (the loss, mini-batch sampling strategy, back-propagation through RoI pooling layers and SGD hyper-parameters) are described below.
除了分层采样,Fast R-CNN使用了一个简化的训练过程,其中有一个微调阶段,可以联合优化softmax分类器和边界框回归器,而不是在三个单独的阶段训练softmax分类器、SVM和回归器[9,11]。此过程的组件(loss、小批量采样策略、通过RoI池化层的反向传播和SGD超参数)描述如下
Multi-task loss.
A Fast R-CNN network has two sibling output layers. The first outputs a discrete probability distribution (per RoI),
, over categories. As usual, is computed by a softmax over the outputs of a fully connected layer. The second sibling layer outputs bounding-box regression offsets, , for each of the object classes, indexed by . We use the parameterization for given in [9], in which specifies a scale-invariant translation and log-space height/width shift relative to an object proposal.
Fast R-CNN网络有两个输出层。第一个输出层对每个ROI输出一个离散概率分布,共
Each training RoI is labeled with a ground-truth class
and a ground-truth bounding-box regression target . We use a multi-task loss on each labeled RoI to jointly train for classification and bounding-box regression:
每个训练ROI通过标注类别
in which
is log loss for true class .
其中
The second task loss,
, is defined over a tuple of true bounding-box regression targets for class , and a predicted tuple again for class . The Iverson bracket indicator function evaluates to when and otherwise. By convention the catch-all background class is labeled . For background RoIs there is no notion of a ground-truth bounding box and hence is ignored. For bounding-box regression, we use the loss
第二个损失函数
in which
其中
is a robust L1 loss that is less sensitive to outliers than the L2 loss used in R-CNN and SPPnet. When the regression targets are unbounded, training with L2 loss can require careful tuning of learning rates in order to prevent exploding gradients. Eq. 3 eliminates this sensitivity.
这是一个稳健的L1损失函数,它对异常值的敏感度低于R-CNN和SPPnet使用的L2损失。当回归目标没有限制时,L2损失的训练可能需要仔细调整学习速率,以防止梯度爆炸。上式消除了这种敏感性
The hyper-parameter λ in Eq. 1 controls the balance between the two task losses. We normalize the ground-truth regression targets
to have zero mean and unit variance. All experiments use λ = 1.
第一个公式中的超参数λ控制了两个损失函数之间的平衡。我们将真值回归目标
We note that [6] uses a related loss to train a classagnostic object proposal network. Different from our approach, [6] advocates for a two-network system that separates localization and classification. OverFeat [19], R-CNN[9], and SPPnet [11] also train classifiers and bounding-box localizers, however these methods use stage-wise training, which we show is suboptimal for Fast R-CNN (Section 5.1).
我们注意到[6]使用了一个相关的损失来训练一个类不可知的目标建议网络。与我们的方法不同,[6]提倡一种将定位和分类分开的双网络系统。OverFeat[19],R-CNN[9],和SPPnet[11]也分别训练了分类器和边界框定位器,然而这些方法使用多阶段训练,通过比较可知Fast R-CNN是更好的选择(第5.1节)
Mini-batch sampling
小批量采样
During fine-tuning, each SGD mini-batch is constructed from N = 2 images, chosen uniformly at random (as is common practice, we actually iterate over permutations of the dataset). We use mini-batches of size R = 128, sampling 64 RoIs from each image. As in [9], we take 25% of the RoIs from object proposals that have intersection over union (IoU) overlap with a groundtruth bounding box of at least 0.5. These RoIs comprise the examples labeled with a foreground object class, i.e. u ≥ 1. The remaining RoIs are sampled from object proposals that have a maximum IoU with ground truth in the interval [0.1, 0.5), following [11]. These are the background examples and are labeled with u = 0. The lower threshold of 0.1 appears to act as a heuristic for hard example mining [8]. During training, images are horizontally flipped with probability 0.5. No other data augmentation is used.
在微调过程中,每个SGD小批量由N = 2个图像构成,随机均匀选择(通常的做法是,我们实际上迭代数据集的排列)。我们使用R = 128的小批量,从每个图像中取样64个区域。如在9中,正样本占25%,其与真值边界框的IoU至少为0.5,正样本同时包括标注的边界框,设置为0.1。在训练过程中,图像有50%的几率进行水平翻转。没有使用其他的数据扩充方法
Back-propagation through RoI pooling layers.
对于RoI池化层的反向传播
Backpropagation routes derivatives through the RoI pooling layer. For clarity, we assume only one image per mini-batch (N = 1), though the extension to N > 1 is straightforward because the forward pass treats all images independently.
反向传播通过RoI池化层传递导数。首先,我们假设每个小批量(
SGD hyper-parameters.
随机梯度下降的超参数
The fully connected layers used for softmax classification and bounding-box regression are initialized from zero-mean Gaussian distributions with standard deviations 0.01 and 0.001, respectively. Biases are initialized to 0. All layers use a per-layer learning rate of 1 for weights and 2 for biases and a global learning rate of 0.001. When training on VOC07 or VOC12 trainval we run SGD for 30k mini-batch iterations, and then lower the learning rate to 0.0001 and train for another 10k iterations. When we train on larger datasets, we run SGD for more iterations, as described later. A momentum of 0.9 and parameter decay of 0.0005 (on weights and biases) are used.
用于softmax分类和边界框回归的全连接层分别使用标准差为0.01和0.001的零均值高斯分布以及偏差为0的方式进行初始化。所有层的权重和偏差的逐层学习率分别为1和2,全局学习率为0.001。当在VOC07或VOC12训练值上训练时,我们运行SGD进行3万次的小批量迭代,然后将学习率降低到0.0001,再进行1万次的迭代训练。当我们在更大的数据集上训练时,我们运行SGD进行更多的迭代,如后面所述。使用0.9的动量和0.0005的参数衰减(在权重和偏差上)
Scale invariance
We explore two ways of achieving scale invariant object detection: (1) via “brute force” learning and (2) by using image pyramids. These strategies follow the two approaches in [11]. In the brute-force approach, each image is processed at a pre-defined pixel size during both training and testing. The network must directly learn scale-invariant object detection from the training data.
我们探索了两种实现尺度不变目标检测的方法:(1)通过“暴力”学习和(2)使用图像金字塔。这些策略遵循[11]的两种方法。在蛮力方法中,在训练和测试期间,每个图像都以预定的像素大小进行处理。网络必须从训练数据中直接学习尺度不变目标检测
The multi-scale approach, in contrast, provides approximate scale-invariance to the network through an image pyramid. At test-time, the image pyramid is used to approximately scale-normalize each object proposal. During multi-scale training, we randomly sample a pyramid scale each time an image is sampled, following [11], as a form of data augmentation. We experiment with multi-scale training for smaller networks only, due to GPU memory limits.
相比之下,多尺度方法通过图像金字塔为网络提供了近似的尺度不变性。在测试时,图像金字塔被用来近似地对每个目标建议进行尺度归一化。在多尺度训练中,我们在[11]之后,每次对图像进行采样时,随机采样一个金字塔尺度,作为一种数据增强的形式。由于图形处理器内存的限制,我们只对较小的网络进行多尺度训练
Fast R-CNN detection
Fast R-CNN检测
Once a Fast R-CNN network is fine-tuned, detection amounts to little more than running a forward pass (assuming object proposals are pre-computed). The network takes as input an image (or an image pyramid, encoded as a list of images) and a list of R object proposals to score. At test-time, R is typically around 2000, although we will consider cases in which it is larger (≈ 45k). When using an image pyramid, each RoI is assigned to the scale such that the scaled RoI is closest to
pixels in area [11].
一旦Fast R-CNN微调完成后,检测只不过是前向计算(假设目标建议是预先计算好的)。该网络将图像(或图像金字塔,编码为图像列表)和要评分的R个目标建议列表作为输入。在测试时,R通常在2000左右,尽管我们会考虑它更大(约为45k)的情况。当使用图像金字塔时,每个感兴趣区域设置为指定尺度,使得缩放后的RoI最接近[11]区域中的
For each test RoI r, the forward pass outputs a class posterior probability distribution p and a set of predicted bounding-box offsets relative to r (each of the K classes gets its own refined bounding-box prediction). We assign a detection confidence to r for each object class k using the estimated probability
. We then perform non-maximum suppression independently for each class using the algorithm and settings from R-CNN [9].
对于每个测试RoI r,前向操作输出一个类后验概率分布p和一组相对于r的预测边界框偏移(K个类中的每一个都有自己的精确边界框预测)。我们使用估计的概率为每个目标类别k分配检测置信度r。然后使用R-CNN[9]的算法和设置,对每个类别独立地执行非最大值抑制
Truncated SVD for faster detection
截断的奇异值分解以实现更快的检测
For whole-image classification, the time spent computing the fully connected layers is small compared to the conv layers. On the contrary, for detection the number of RoIs to process is large and nearly half of the forward pass time is spent computing the fully connected layers (see Fig. 2). Large fully connected layers are easily accelerated by compressing them with truncated SVD [5, 23].
在整个图像分类中,全连接层所花费的计算时间与卷积层相比更少。相反,对于检测来说,要处理的RoI的数量很大,并且将近一半的前向计算时间用于全连接层(见图2)。用截断奇异值分解[5,23]压缩大型全连接层,可以很容易地加速它们
In this technique, a layer parameterized by the u × v weight matrix W is approximately factorized as
在该技术中,由u × v权重矩阵W参数化的层近似分解为
。。。 。。。
Main Results
主要成果
Three main results support this paper’s contributions: 1. State-of-the-art mAP on VOC07, 2010, and 2012 2. Fast training and testing compared to R-CNN, SPPnet 3. Fine-tuning conv layers in VGG16 improves mAP
本文主要有3个贡献:
- 在VOC07、2010和2012上实现最好的mAP
- 比R-CNN和SPPnet更快的训练和检测
- 在VGG16上微调卷积层,提高了mAP
Experimental setup
实验设置
Our experiments use three pre-trained ImageNet models that are available
. The first is the CaffeNet (essentially AlexNet [14]) from R-CNN [9]. We alternatively refer to this CaffeNet as model S, for “small.” The second network is VGG CNN M 1024 from [3], which has the same depth as S, but is wider. We call this network model M, for “medium.” The final network is the very deep VGG16 model from [20]. Since this model is the largest, we call it model L. In this section, all experiments use single-scale training and testing (s = 600; see Section 5.2 for details).
2:https://github.com/BVLC/caffe/wiki/Model-Z
本实验采用3个预训练模型。第一个模型是AlexNet[14]。称为之模型S,也就是“Small”。第二个是VGG CNN M 1024[3],其和模型S具有相同深度,但是更宽。称之为模型M,也就是“Medium”。最后一个网络是非常深的VGG16[20]。因为该模型最大,所以称之为模型L。在本节中,所有的实验使用单尺度训练和测试(s=600,参考5.2小节)
VOC 2010 and 2012 results
VOC 2010和2012结果
On these datasets, we compare Fast R-CNN (FRCN, for short) against the top methods on the comp4 (outside data) track from the public leaderboard
. For the NUS_NIN_c2000 and BabyLearning methods, there are no associated publications at this time and we could not find exact information on the ConvNet architectures used; they are variants of the Network-in-Network design [17]. All other methods are initialized from the same pre-trained VGG16 network.
在这些数据集上,我们比较了Fast R-CNN(简称FRCN)和公共排行榜
Fast R-CNN achieves the top result on VOC12 with a mAP of 65.7% (and 68.4% with extra data). It is also two orders of magnitude faster than the other methods, which are all based on the “slow” R-CNN pipeline. On VOC10, SegDeepM [25] achieves a higher mAP than Fast R-CNN (67.2% vs. 66.1%). SegDeepM is trained on VOC12 trainval plus segmentation annotations; it is designed to boost R-CNN accuracy by using a Markov random field to reason over R-CNN detections and segmentations from the
[1] semantic-segmentation method. Fast R-CNN can be swapped into SegDeepM in place of R-CNN, which may lead to better results. When using the enlarged 07++12 training set (see Table 2 caption), Fast R-CNN’s mAP increases to 68.8%, surpassing SegDeepM.
Fast R-CNN以65.7%的mAP(在额外数据情况下得到68.4%)在VOC 12上取得了最高的成绩。它也比其他方法快两个数量级,其他方法都是基于“慢”的R-CNN流程。在VOC 10方面,SegDeepM[25]实现了比R-CNN更高的mAP(67.2%对66.1%)。SegDeepM是在VOC12 trainval和分割标注上训练的;它被设计成通过使用马尔可夫随机场来推理从
VOC 2007 results
VOC 2007结果
On VOC07, we compare Fast R-CNN to R-CNN and SPPnet. All methods start from the same pre-trained VGG16 network and use bounding-box regression. The VGG16 SPPnet results were computed by the authors of [11]. SPPnet uses five scales during both training and testing. The improvement of Fast R-CNN over SPPnet illustrates that even though Fast R-CNN uses single-scale training and testing, fine-tuning the conv layers provides a large improvement in mAP (from 63.1% to 66.9%). R-CNN achieves a mAP of 66.0%. As a minor point, SPPnet was trained without examples marked as “difficult” in PASCAL. Removing these examples improves Fast R-CNN mAP to 68.1%. All other experiments use “difficult” examples.
在VOC07上,我们比较了Fast R-CNN与R-CNN和SPPnet。所有方法都是从同一个预先训练好的VGG16网络开始,并使用边界框回归。VGG16 SPPnet结果由[11]的作者计算得出。SPPnet在训练和测试中使用了五种尺度。Fast R-CNN相对于R-CNN的改进表明,尽管Fast R-CNN使用单一尺度的训练和测试,微调conv层提供了mAP的巨大改进(从63.1%到66.9%)。R-CNN的平均mAP达到66.0%。另外,SPPnet在PASCAL中没有使用被标记为“困难”的样本。删除这些样本后,Fast R-CNN的mAP提高到68.1%。所有其他实验都使用“困难”的示例

Table 1. VOC 2007 test detection average precision (%). All methods use VGG16. Training set key: 07: VOC07 trainval, 07 diff: 07 without “difficult” examples, 07+12: union of 07 and VOC12 trainval. †SPPnet results were prepared by the authors of [11].

Table 2. VOC 2010 test detection average precision (%). BabyLearning uses a network based on [17]. All other methods use VGG16. Training set key: 12: VOC12 trainval, Prop.: proprietary dataset, 12+seg: 12 with segmentation annotations, 07++12: union of VOC07 trainval, VOC07 test, and VOC12 trainval.

Table 3. VOC 2012 test detection average precision (%). BabyLearning and NUS NIN c2000 use networks based on [17]. All other methods use VGG16. Training set key: see Table 2, Unk.: unknown.
Training and testing time
训练和测试时间
Fast training and testing times are our second main result. Table 4 compares training time (hours), testing rate (seconds per image), and mAP on VOC07 between Fast R-CNN, R-CNN, and SPPnet. For VGG16, Fast R-CNN processes images 146× faster than R-CNN without truncated SVD and 213× faster with it. Training time is reduced by 9×, from 84 hours to 9.5. Compared to SPPnet, Fast R-CNN trains VGG16 2.7× faster (in 9.5 vs. 25.5 hours) and tests 7× faster without truncated SVD or 10× faster with it. Fast R-CNN also eliminates hundreds of gigabytes of disk storage, because it does not cache features.
快速的训练和测试时间是我们的第二个主要结果。表4比较了训练时间(小时)、测试速度(每幅图像的秒数)以及Fast R-CNN、R-CNN和SPPnet之间的VOC 07 mAP。对于VGG16来说,在没有使用截断奇异值分解的情况下,Fast R-CNN处理图像的速度比R-CNN快146倍,使用截断SVD的情况下快213倍。训练时间减少了9倍,从84小时减少到9.5小时。与SPPnet相比,在没有使用截断SVD的情况下,Fast R-CNN训练VGG16的速度提高了2.7倍(9.5小时对25.5小时),测试速度提高了7倍,而使用截断SVD的情况下提高了10倍。Fast R-CNN还减少了几千兆字节的磁盘存储,因为它不缓存特征
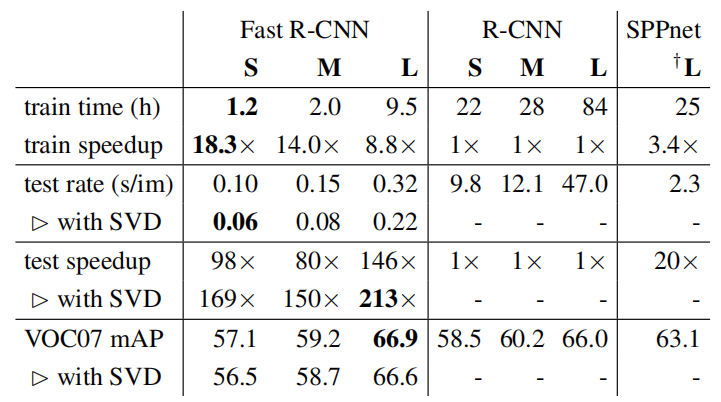
Table 4. Runtime comparison between the same models in Fast R-CNN, R-CNN, and SPPnet. Fast R-CNN uses single-scale mode. SPPnet uses the five scales specified in [11]. †Timing provided by the authors of [11]. Times were measured on an Nvidia K40 GPU.
Truncated SVD.
截断SVD
Truncated SVD can reduce detection time by more than 30% with only a small (0.3 percentage point) drop in mAP and without needing to perform additional fine-tuning after model compression. Fig. 2 illustrates how using the top 1024 singular values from the 25088 × 4096 matrix in VGG16’s fc6 layer and the top 256 singular values from the 4096×4096 fc7 layer reduces runtime with little loss in mAP. Further speed-ups are possible with smaller drops in mAP if one fine-tunes again after compression.
截断SVD可以将检测时间减少30%以上,mAP仅下降0.3个百分点,并且无需在模型压缩后执行额外的微调。图2说明了在VGG16的fc6层中使用来自25088 × 4096矩阵的前1024个奇异值和来自4096×4096 fc7层的前256个奇异值如何在mAP中以很小的损失减少运行时间。如果一个人在压缩后再次微调,那么就有可能实现进一步加速,而且mAP下降更小
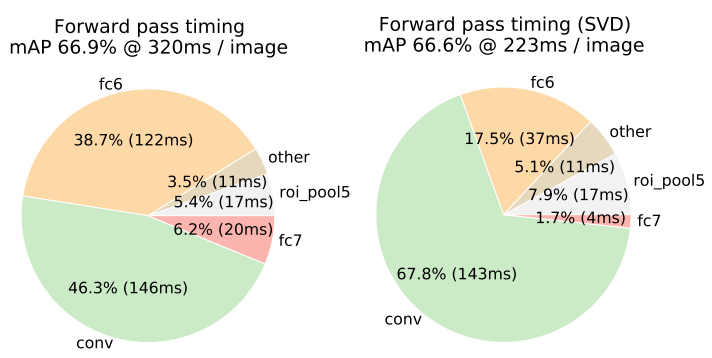
Figure 2. Timing for VGG16 before and after truncated SVD. Before SVD, fully connected layers fc6 and fc7 take 45% of the time.
Which layers to fine-tune?
微调哪个层?
For the less deep networks considered in the SPPnet paper [11], fine-tuning only the fully connected layers appeared to be sufficient for good accuracy. We hypothesized that this result would not hold for very deep networks. To validate that fine-tuning the conv layers is important for VGG16, we use Fast R-CNN to fine-tune, but freeze the thirteen conv layers so that only the fully connected layers learn. This ablation emulates single-scale SPPnet training and decreases mAP from 66.9% to 61.4% (Table 5). This experiment verifies our hypothesis: training through the RoI pooling layer is important for very deep nets.
对于在SPPnet论文[11]中考虑的不太深的网络,仅微调全连接层似乎就足以获得良好的精度。我们假设这个结果不适用于非常深的网络。为了验证微调conv层对VGG16是重要的,我们使用Fast R-CNN来微调,但是冻结13个conv层,以便只有全连接层进行学习。这种消融模拟了单尺度SPPnet训练,并将mAP从66.9%降至61.4%(表5)。这个实验验证了我们的假设:通过RoI池化层的训练对于非常深的网是重要的
Does this mean that all conv layers should be fine-tuned? In short, no. In the smaller networks (S and M) we find that conv1 is generic and task independent (a well-known fact [14]). Allowing conv1 to learn, or not, has no meaningful effect on mAP. For VGG16, we found it only necessary to update layers from conv3_1 and up (9 of the 13 conv layers). This observation is pragmatic: (1) updating from conv2_1 slows training by 1.3× (12.5 vs. 9.5 hours) compared to learning from conv3_1; and (2) updating from conv1_1 over-runs GPU memory. The difference in mAP when learning from conv2 1 up was only +0.3 points (Table 5, last column). All Fast R-CNN results in this paper using VGG16 fine-tune layers conv3 1 and up; all experiments with models S and M fine-tune layers conv2 and up.
这是否意味着所有conv层都应该微调?简而言之,没有。在较小的网络(S和M)中,我们发现conv1是通用的,并且独立于任务(众所周知的事实[14)。允许或不允许conv1学习对mAP没有任何意义。对于VGG16,我们发现只需要更新conv3_1及以上的层(13个conv层中的9个)。这一观察是实用的:(1)从conv2_1更新比从conv3_1学习慢1.3倍(12.5小时对9.5小时);以及(2)从conv1_1开始更新将会溢出GPU存储器。从conv2_1开始学习时,mAP的差异仅为+0.3点(表5,最后一列)。本文中的所有Fast R-CNN结果均使用VGG16微调层conv3_1及以上;所有使用S型和M型微调层的实验都适用于conv2和更高版本

Table 5. Effect of restricting which layers are fine-tuned for VGG16. Fine-tuning ≥ fc6 emulates the SPPnet training algorithm [11], but using a single scale. SPPnet L results were obtained using five scales, at a significant (7×) speed cost.
Design evaluation
设计评估
We conducted experiments to understand how Fast R-CNN compares to R-CNN and SPPnet, as well as to evaluate design decisions. Following best practices, we performed these experiments on the PASCAL VOC07 dataset.
我们进行了一些实验,以了解Fast R-CNN与R-CNN和SPPnet相比速度有多快,并评估设计决策。遵循最佳实践,我们在PASCAL VOC07数据集上进行了这些实验
Does multi-task training help?
多任务训练是否有帮助?(多任务训练:就是同时进行分类和定位)
Multi-task training is convenient because it avoids managing a pipeline of sequentially-trained tasks. But it also has the potential to improve results because the tasks influence each other through a shared representation (the ConvNet) [2]. Does multi-task training improve object detection accuracy in Fast R-CNN?
多任务训练很方便,因为它避免了管理系列连续训练的任务。但是它也有可能改善结果,因为任务通过共享表示(ConvNet)相互影响[2]。多任务训练能提高Fast R-CNN的目标检测精度吗?
To test this question, we train baseline networks that use only the classification loss,
, in Eq. 1 (i.e., setting λ = 0). These baselines are printed for models S, M, and L in the first column of each group in Table 6. Note that these models do not have bounding-box regressors. Next (second column per group), we take networks that were trained with the multi-task loss (Eq. 1, λ = 1), but we disable boundingbox regression at test time. This isolates the networks’ classification accuracy and allows an apples-to-apples comparison with the baseline networks.
为了测试这个问题,我们在训练中只使用分类损失
Across all three networks we observe that multi-task training improves pure classification accuracy relative to training for classification alone. The improvement ranges from +0.8 to +1.1 mAP points, showing a consistent positive effect from multi-task learning.
在所有三个网络中,我们观察到多任务训练相对于单独的分类训练提高了纯分类的准确性。改进范围从+0.8到+1.1 mAP点,显示了多任务学习的积极效果
Finally, we take the baseline models (trained with only the classification loss), tack on the bounding-box regression layer, and train them with
while keeping all other network parameters frozen. The third column in each group shows the results of this stage-wise training scheme: mAP improves over column one, but stage-wise training underperforms multi-task training (forth column per group).
最后,我们采用基准模型(仅使用分类损失进行训练),在边界框回归层上进行定位,并使用

Table 6. Multi-task training (forth column per group) improves mAP over piecewise training (third column per group).
Scale invariance: to brute force or finesse?
尺度不变性:暴力方法还是巧妙技巧?
We compare two strategies for achieving scale-invariant object detection: brute-force learning (single scale) and image pyramids (multi-scale). In either case, we define the scale s of an image to be the length of its shortest side.
我们比较了两种实现尺度不变目标检测的策略:暴力学习(单尺度)和图像金字塔(多尺度)。在任一种情况下,我们将图像的比例定义为其最短边的长度
All single-scale experiments use s = 600 pixels; s may be less than 600 for some images as we cap the longest image side at 1000 pixels and maintain the image’s aspect ratio. These values were selected so that VGG16 fits in GPU memory during fine-tuning. The smaller models are not memory bound and can benefit from larger values of s; however, optimizing s for each model is not our main concern. We note that PASCAL images are 384 × 473 pixels on average and thus the single-scale setting typically upsamples images by a factor of 1.6. The average effective stride at the RoI pooling layer is thus ≈ 10 pixels.
所有单尺度实验都使用s = 600像素;对于一些图像,s可能小于600,因为我们将最长的图像边限制在1000像素,并保持图像的纵横比。选择这些值是为了使VGG16在微调过程中适合图形处理器内存。较小的模型不受内存限制,可以从较大的s值中受益;然而,为每个模型优化s不是我们主要关心的问题。我们注意到PASCAL图像平均为384 × 473像素,因此单尺度设置通常会将图像的采样值提高1.6倍。因此,RoI汇集层的平均有效步幅约为10像素
In the multi-scale setting, we use the same five scales specified in [11] (s ∈ {480, 576, 688, 864, 1200}) to facilitate comparison with SPPnet. However, we cap the longest side at 2000 pixels to avoid exceeding GPU memory.
在多尺度设置中,我们使用11中规定的相同五种尺度,以便于与SPPnet进行比较。然而,我们将最长边限制在2000像素,以避免超过GPU内存
Table 7 shows models S and M when trained and tested with either one or five scales. Perhaps the most surprising result in [11] was that single-scale detection performs almost as well as multi-scale detection. Our findings confirm their result: deep ConvNets are adept at directly learning scale invariance. The multi-scale approach offers only a small increase in mAP at a large cost in compute time (Table 7). In the case of VGG16 (model L), we are limited to using a single scale by implementation details. Yet it achieves a mAP of 66.9%, which is slightly higher than the 66.0% reported for R-CNN [10], even though R-CNN uses“infinite” scales in the sense that each proposal is warped to a canonical size.
表7显示了用一个或五个尺寸训练和测试的模型S和M。也许[11]中最令人惊讶的结果是单尺度检测几乎和多尺度检测一样好。我们的发现证实了他们的结果:深层神经网络擅长直接学习尺度不变性。多尺度方法在计算时间上花费很大,但在mAP上只提供了很小的增加(表7)。在VGG16(模型L)的情况下,我们仅使用单一比例情况下实现了66.9%的mAP,比R-CNN[10]报道的66.0%略高,尽管R-CNN使用“无限”尺度,即每一个建议都被扭曲到一个规范的大小
Since single-scale processing offers the best tradeoff between speed and accuracy, especially for very deep models, all experiments outside of this sub-section use single-scale training and testing with s = 600 pixels.
由于单尺度处理提供了速度和精度之间的最佳折衷,特别是对于非常深的模型,所以本小节之外的所有实验都使用s = 600像素的单尺度训练和测试
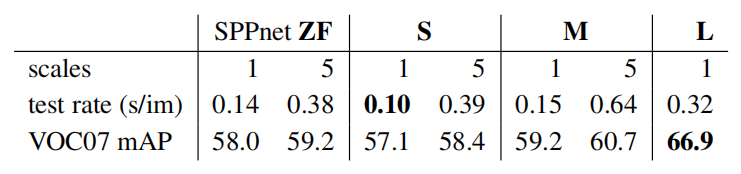
Table 7. Multi-scale vs. single scale. SPPnet ZF (similar to model S) results are from [11]. Larger networks with a single-scale offer the best speed / accuracy tradeoff. (L cannot use multi-scale in our implementation due to GPU memory constraints.)
Do we need more training data?
是否需要更多的训练数据?
A good object detector should improve when supplied with more training data. Zhu et al. [24] found that DPM [8] mAP saturates after only a few hundred to thousand training examples. Here we augment the VOC07 trainval set with the VOC12 trainval set, roughly tripling the number of images to 16.5k, to evaluate Fast R-CNN. Enlarging the training set improves mAP on VOC07 test from 66.9% to 70.0% (Table 1). When training on this dataset we use 60k mini-batch iterations instead of 40k.
当提供更多的训练数据时,一个好的目标检测器应该会有所改进。朱等人[24]发现,DPM[8]的mAP只经过几百到上千个训练例子就饱和了。在这里,我们用VOC12训练集来扩充VOC07训练集,把图像的数量大约增加了两倍,达到16.5千,来评估Fast R-CNN。扩大训练集可将VOC07测试集的mAP从66.9%提高到70.0%(表1)。当在这个数据集上训练时,我们使用60k的小批量迭代,而不是40k
We perform similar experiments for VOC10 and 2012, for which we construct a dataset of 21.5k images from the union of VOC07 trainval, test, and VOC12 trainval. When training on this dataset, we use 100k SGD iterations and lower the learning rate by 0.1× each 40k iterations (instead of each 30k). For VOC10 and 2012, mAP improves from 66.1% to 68.8% and from 65.7% to 68.4%, respectively.
我们对VOC10和12进行了类似的实验,为此我们从VOC07 trainval、test和VOC12 trainval的并集中构建了一个21.5千幅图像的数据集。当在这个数据集上训练时,我们使用100k SGD迭代,并且每40k次迭代(而不是每30k次)将学习率降低0.1倍。对于VOC10和12,mAP分别从66.1%提高到68.8%和从65.7%提高到68.4%
Do SVMs outperform softmax?
Fast R-CNN uses the softmax classifier learnt during fine-tuning instead of training one-vs-rest linear SVMs post-hoc, as was done in R-CNN and SPPnet. To understand the impact of this choice, we implemented post-hoc SVM training with hard negative mining in Fast R-CNN. We use the same training algorithm and hyper-parameters as in R-CNN.
Fast R-CNN使用在微调过程中学习到的softmax分类器,而不是像R-CNN和SPPnet那样事后训练一对多的线性支持向量机。为了理解这一选择的影响,我们在Fast R-CNN中实施了带有hard negative挖掘的SVM训练。我们使用的训练算法和超参数与R-CNN相同
Table 8 shows softmax slightly outperforming SVM for all three networks, by +0.1 to +0.8 mAP points. This effect is small, but it demonstrates that “one-shot” fine-tuning is sufficient compared to previous multi-stage training approaches. We note that softmax, unlike one-vs-rest SVMs, introduces competition between classes when scoring a RoI.
表8显示,在所有三个网络中,softmax的表现略好于SVM,平均绩点为+0.1至+0.8。这种影响很小,但它表明与以前的多阶段训练方法相比,“一次”微调就足够了。我们注意到,softmax不同于一对多SVMs,在计算RoI时引入了类之间的竞争
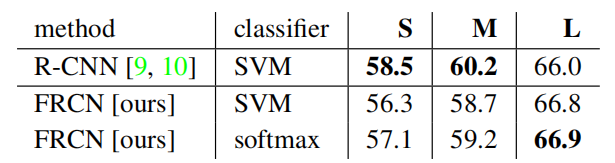
Table 8. Fast R-CNN with softmax vs. SVM (VOC07 mAP).
Are more proposals always better?
更多的候选目标是否更好?
There are (broadly) two types of object detectors: those that use a sparse set of object proposals (e.g., selective search [21]) and those that use a dense set (e.g., DPM [8]). Classifying sparse proposals is a type of cascade [22] in which the proposal mechanism first rejects a vast number of candidates leaving the classifier with a small set to evaluate. This cascade improves detection accuracy when applied to DPM detections [21]. We find evidence that the proposal-classifier cascade also improves Fast R-CNN accuracy.
有(广义地)两种类型的目标检测器:使用稀疏目标建议集的检测器(例如,选择性搜索[21)和使用密集集合的检测器(例如,DPM [8])。对稀疏建议进行分类是级联[22]的一种类型,其中建议机制首先拒绝大量的候选目标,留给分类器一个小集合来评估。当应用于DPM检测时,这种级联提高了检测精度[21]。我们发现证据表明,建议-分类器的级联也提高了Fast R-CNN的准确性
Using selective search’s quality mode, we sweep from 1k to 10k proposals per image, each time re-training and retesting model M. If proposals serve a purely computational role, increasing the number of proposals per image should not harm mAP.
基于选择性搜索的质量模式,我们每次对模型M进行重新训练和测试时,将每幅图像的建议数量从1k增加到10k。如果建议仅用于计算,那么增加每幅图像的建议数量应该不会损害mAP
We find that mAP rises and then falls slightly as the proposal count increases (Fig. 3, solid blue line). This experiment shows that swamping the deep classifier with more proposals does not help, and even slightly hurts, accuracy.
我们发现,随着建议数量的增加,mAP先上升后略有下降(图3,蓝色实线)。这个实验表明,用更多的建议淹没深度分类器不会有帮助,甚至会稍微损害准确性
This result is difficult to predict without actually running the experiment. The state-of-the-art for measuring object proposal quality is Average Recall (AR) [12]. AR correlates well with mAP for several proposal methods using R-CNN, when using a fixed number of proposals per image. Fig. 3 shows that AR (solid red line) does not correlate well with mAP as the number of proposals per image is varied. AR must be used with care; higher AR due to more proposals does not imply that mAP will increase. Fortunately, training and testing with model M takes less than 2.5 hours. Fast R-CNN thus enables efficient, direct evaluation of object proposal mAP, which is preferable to proxy metrics.
如果不进行实验,这个结果很难预测。衡量目标建议质量的最新技术是平均召回率(AR) [12]。当对每幅图像使用固定数量的建议时,在使用R-CNN的几种建议方法中,AR与mAP有很好的相关性。图3显示,当每幅图像的目标数量变化时,AR(实线)与mAP没有很好的关联。AR必须小心使用;更多建议导致的更高AR,但并不意味着mAP会增加。幸运的是,用模型M进行训练和测试不到2.5个小时。因此,Fast R-CNN能够高效、直接地评估目标建议mAP,这比代理度量更好
We also investigate Fast R-CNN when using densely generated boxes (over scale, position, and aspect ratio), at a rate of about 45k boxes / image. This dense set is rich enough that when each selective search box is replaced by its closest (in IoU) dense box, mAP drops only 1 point (to 57.7%, Fig. 3, blue triangle).
当使用密集生成的边框(不同比例、位置和长宽比)时,我们以约为45k盒子/图像的方式训练Fast R-CNN,。这个密集集合足够丰富,当每个选择性搜索框被其最近的(在IoU中)密集框替换时,mAP仅下降1点(到57.7%,图3,蓝色三角形)
The statistics of the dense boxes differ from those of selective search boxes. Starting with 2k selective search boxes, we test mAP when adding a random sample of 1000 × {2, 4, 6, 8, 10, 32, 45} dense boxes. For each experiment we re-train and re-test model M. When these dense boxes are added, mAP falls more strongly than when adding more selective search boxes, eventually reaching 53.0%.
密集框的统计数据不同于选择性搜索框的统计数据。从2k选择性搜索框开始,测试添加1000 × {2,4,6,8,10,32,45}个密集框的随机样本时的mAP。对于每个实验,我们重新训练和测试模型M。当这些密集边框被添加时,mAP比当添加更多的选择性搜索框时下降得更厉害,最终达到53.0%
We also train and test Fast R-CNN using only dense boxes (45k / image). This setting yields a mAP of 52.9% (blue diamond). Finally, we check if SVMs with hard negative mining are needed to cope with the dense box distribution. SVMs do even worse: 49.3% (blue circle).
我们也只使用密集边框(45k /图像)来训练和测试Fast R-CNN。该设置得到52.9%的mAP(蓝色菱形)。最后,我们检查是否需要具有hard negative挖掘的支持向量机来处理密集边框。SVMs表现更差:49.3%(蓝色圆圈)
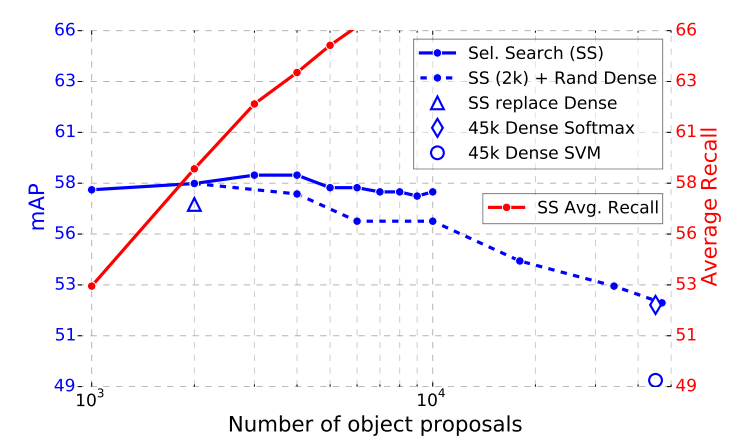
Figure 3. VOC07 test mAP and AR for various proposal schemes.
Preliminary MS COCO results
初步MS COO结果
We applied Fast R-CNN (with VGG16) to the MS COCO dataset [18] to establish a preliminary baseline. We trained on the 80k image training set for 240k iterations and evaluated on the “test-dev” set using the evaluation server. The PASCAL-style mAP is 35.9%; the new COCO-style AP, which also averages over IoU thresholds, is 19.7%.
我们将Fast R-CNN(配有VGG16)应用于[18]MS COCO数据集,以建立初步基准。我们在80k图像训练集上训练了240k次迭代,并使用评估服务器在“测试开发”集上进行评估。PASCAL风格的mAP是35.9%;新的COCO风格的AP也超过了IoU阈值,为19.7%
Conclusion
总结
This paper proposes Fast R-CNN, a clean and fast update to R-CNN and SPPnet. In addition to reporting state-of-the-art detection results, we present detailed experiments that we hope provide new insights. Of particular note, sparse object proposals appear to improve detector quality. This issue was too costly (in time) to probe in the past, but becomes practical with Fast R-CNN. Of course, there may exist yet undiscovered techniques that allow dense boxes to perform as well as sparse proposals. Such methods, if developed, may help further accelerate object detection.
本文提出了Fast R-CNN模型。除了报告最先进的检测结果,我们还提供了详细的实验,希望能提供新的见解。特别值得注意的是,稀疏目标建议似乎提高了检测器的质量。这个问题过去由于(在时间上)太过昂贵,无法探究,但在Fast R-CNN上变得很实用。当然,可能存在尚未被发现的技术,允许密集边框和稀疏建议一样工作。这种方法,如果发展起来,可能有助于进一步加快物体检测
Gitalk 加载中 ...