FaceNet: A Unified Embedding for Face Recognition and Clustering
原文地址:FaceNet: A Unified Embedding for Face Recognition and Clustering
复现地址:ZJCV/facenet
摘要
Despite significant recent advances in the field of face recognition, implementing face verification and recognition efficiently at scale presents serious challenges to current approaches. In this paper we present a system, called FaceNet, that directly learns a mapping from face images to a compact Euclidean space where distances directly correspond to a measure of face similarity. Once this space has been produced, tasks such as face recognition, verification and clustering can be easily implemented using standard techniques with FaceNet embeddings as feature vectors. Our method uses a deep convolutional network trained to directly optimize the embedding itself, rather than an intermediate bottleneck layer as in previous deep learning approaches. To train, we use triplets of roughly aligned matching / non-matching face patches generated using a novel online triplet mining method. The benefit of our approach is much greater representational efficiency: we achieve state-of-the-art face recognition performance using only 128-bytes per face. On the widely used Labeled Faces in the Wild (LFW) dataset, our system achieves a new record accuracy of 99.63%. On YouTube Faces DB it achieves 95.12%. Our system cuts the error rate in comparison to the best published result by 30% on both datasets. We also introduce the concept of harmonic embeddings, and a harmonic triplet loss, which describe different versions of face embeddings (produced by different networks) that are compatible to each other and allow for direct comparison between each other.
尽管最近在人脸识别领域取得了重大进展,但是对当前的方法而言有效地实现大规模人脸验证和识别仍旧是巨大的挑战。在本文中,我们介绍了一个名为FaceNet的系统,该系统直接学习从人脸图像到紧凑的欧氏空间的映射,其距离直接对应于人脸相似性的度量。一旦创建了这个空间,人脸识别、验证和聚类等任务就可以很容易地使用标准技术来实现,将FaceNet嵌入作为特征向量。 我们的方法使用深度卷积网络来直接优化嵌入本身,而不是像以前的深度学习方法那样使用中间瓶颈层。为了进行训练,我们使用一种新型在线三元组挖掘方法生成的粗略对齐的匹配/不匹配人脸三元组。我们方法的好处是拥有更高的表示效率:仅使用每张脸128字节即可实现最先进的人脸识别性能。 在LFW数据集上我们的系统达到了99.63%的最高准确率。在YouTube人脸数据库上,它达到了95.12%。相比于之前在两个数据集上发布的最好效果,FaceNet将错误率降低了30%。 我们还引入了谐波嵌入和谐波三重损失的概念,它们描述了不同版本的人脸嵌入(由不同的网络产生),这些人脸嵌入相互兼容并允许相互之间直接比较。
引言
之前进行人脸识别的方法大多先使用深度网络进行目标分类训练,然后提取中间隐藏层作为特征向量进行人脸识别,存在如下缺陷:
- 不直接:深度网络是作为分类任务进行训练的,而不是直接作为人脸识别进行训练,这可能导致中间隐藏层对于未训练的人脸不具有泛化性;
- 低效率:中间隐藏层往往具有很高维度,比如超过
1000维向量,这会导致计算耗时。
FaceNet直接将深度网络作用于人脸识别训练,其输出一个128维向量,表示人脸嵌入表示;同时,创建了一个3元组损失函数,除了待训练人脸外,还拥有一个正样本(相同类别的人脸)和一个负样本(不同类别的人脸),其目的在于保证相同类别的人脸向量之间的距离足够小,不同类别的人脸向量之间的距离足够大。
通过将人脸图像嵌入到128维向量空间,计算两个特征向量之间的L2距离作为人脸相似度,一旦完成训练,即可在多个任务中进行操作:
- 人脸验证(是否属于同一个人):计算两个特征向量的相似度,然后通过阈值进行判断;
- 人脸识别(属于其中哪个人):通过
KNN分类器计算特征向量所属类别; - 人脸聚类(发现具有相同特性的一群人):使用
k-means等常用的聚类算法即可实现。

整体架构
FaceNet是一个完整的训练框架,能够实现端到端的学习,其结构如下图所示:
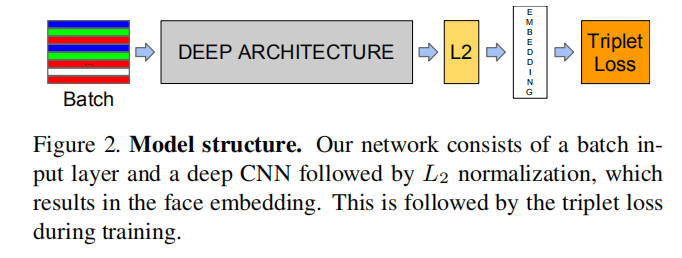
整体训练流程如下:
- 将图像批量输入到模型;
- 通过深度网络计算每张图片的特征向量;
- 计算每对图像之间的
L2距离,并进行归一化; - 计算符合条件的正负样本之间的
3元组损失; - 进行梯度反向传播训练,重复第一步。
损失函数
Tripet loss
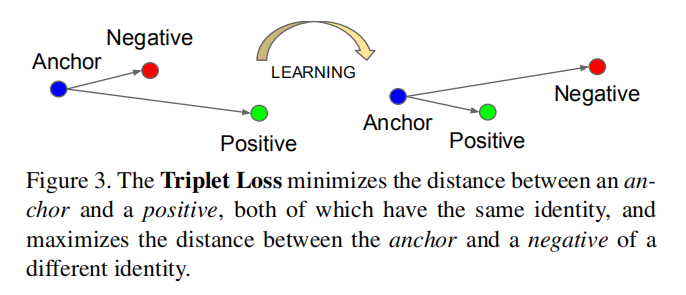
对于图像
3元组损失,想要所有正样本对的相似度小于负样本对的相似度至少3元组;3元组个数。
3元组损失函数定义如下:
Triplet Selection
在所有可能的3元组(锚点、正样本和负样本)选择中,很多情况下会满足锚点和正样本距离远小于负样本的条件。这种情况下,这些3元组会减慢模型训练(其损失值等于0,不对训练有帮助,同时经过平均计算后损失值不高,减慢了训练收敛),所以训练的关键在于选择合适的3元组参与模型训练。
最理想情况下,给定锚点hard positive)的条件是满足hard negative)的条件是满足
论文了提出两种采集方式:
- 线下生成:每运行
- 在线生成:在当前批次中选择符合条件的3元组参与训练。
对于3元组而言,根据损失函数定义,存在3种情况:
easy triplets:损失值为0,因为其符合条件hard triplets:负样本远比正样本接近于锚点(semi-hard triplets:负样本并没有比正样本接近于锚点,但是仍符合训练条件(
上述条件的定义依赖于负样本的位置,所以可定义3种负样本:hard negatives, semi-hard negatives or easy negatives。如下图所示:
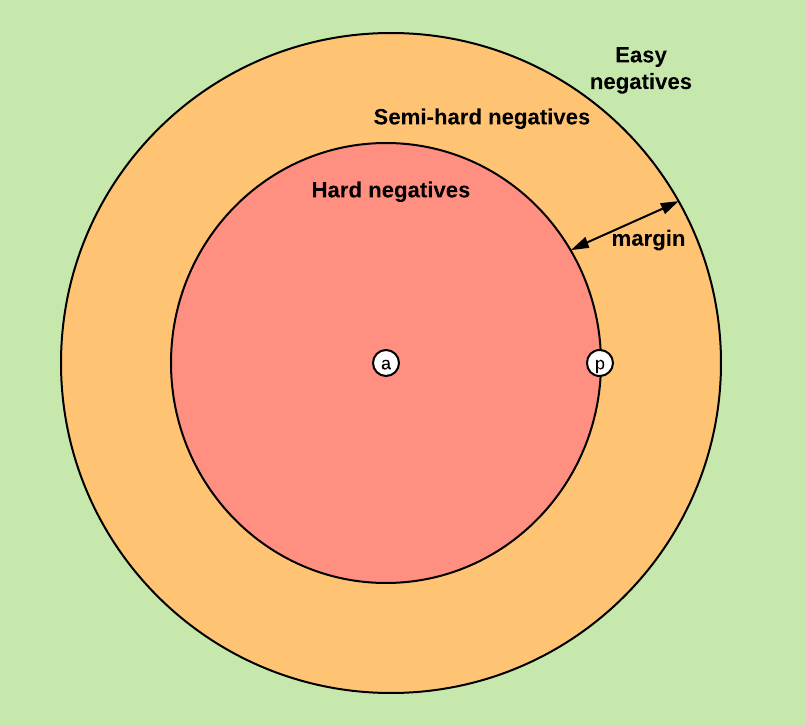
论文最终使用的是在线生成策略,采集semi-hard negatives组成的3元组参与训练,同时通过提高batch-size的方式来保证收敛速度和训练质量。
人脸验证
论文描述了人脸验证任务的评估指标。给定一对人脸图像,计算平方L2距离,然后通过阈值
正阳性样本集(true positives or true accepts)计算如下:
假阳性样本集(false positives or false accepts)计算如下:
给定阈值
实验
论文从8百万个人类中采集了1~2亿训练图像,输入训练大小从
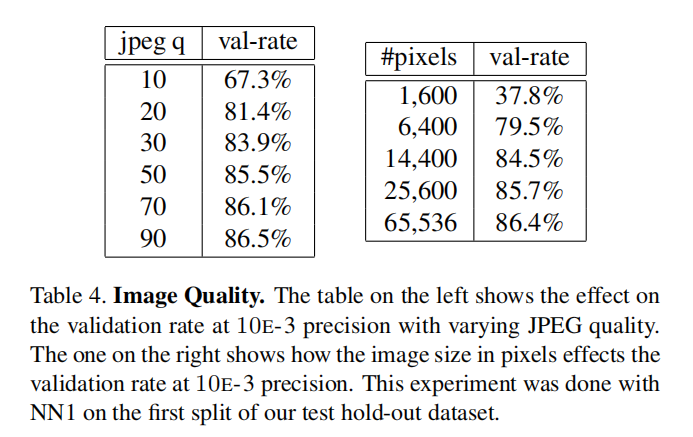
图像质量
论文比较了不同图像压缩率和不同图像大小情况下模型性能,发现FaceNet对于图像质量拥有极高的容忍度
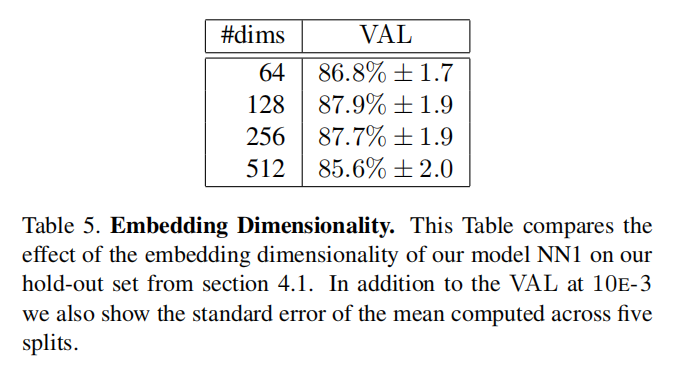
嵌入维度
论文比较了不同的嵌入向量长度对于性能影响,确定最终模型输出128维
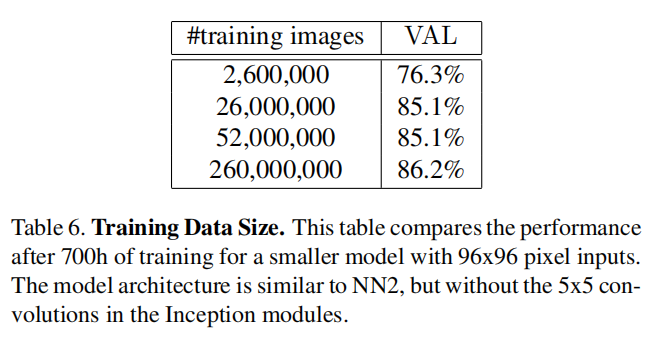
训练集数目
论文实验了不同数目的训练集对于性能影响,发现数据数目与模型性能呈现正相关性。
小结
FaceNet的创新点:
- 直接训练人脸识别任务,将图像嵌入到
128维特征空间,完成训练后模型提取的特征向量可直接作用于人脸验证、识别和聚类任务; - 提出
3元组损失函数,确保所属相同人脸的特征向量的相似度足够小,所属不同人脸的特征向量的相似度足够大。 - 提出一种新颖的在线负样本挖掘策略,确保网络的训练质量。
训练中需要注意的重点:
- 选取有效的
3元组:锚点+所有正样本+semi-hard负样本 - 提高批量大小。
Gitalk 加载中 ...