Fine-tuning CNN Image Retrieval with No Human Annotation
原文地址:Fine-tuning CNN Image Retrieval with No Human Annotation
官方实现:filipradenovic/cnnimageretrieval-pytorch
摘要
Image descriptors based on activations of Convolutional Neural Networks (CNNs) have become dominant in image retrieval due to their discriminative power, compactness of representation, and search efficiency. Training of CNNs, either from scratch or fine-tuning, requires a large amount of annotated data, where a high quality of annotation is often crucial. In this work, we propose to fine-tune CNNs for image retrieval on a large collection of unordered images in a fully automated manner. Reconstructed 3D models obtained by the state-of-the-art retrieval and structure-from-motion methods guide the selection of the training data. We show that both hard-positive and hard-negative examples, selected by exploiting the geometry and the camera positions available from the 3D models, enhance the performance of particular-object retrieval. CNN descriptor whitening discriminatively learned from the same training data outperforms commonly used PCA whitening. We propose a novel trainable Generalized-Mean (GeM) pooling layer that generalizes max and average pooling and show that it boosts retrieval performance. Applying the proposed method to the VGG network achieves state-of-the-art performance on the standard benchmarks: Oxford Buildings, Paris, and Holidays datasets.
由于其高效的判别能力、表示紧凑性和搜索效率,基于卷积神经网络激活的图像描述符已经在图像检索任务中占据主导地位。无论是从头开始还是微调训练CNN都需要大量的标注数据,高质量的标注数据往往至关重要。在本文中我们提出以完全自动化的方式对大量无序图像进行图像检索任务微调训练。通过最先进的检索和运动结构方法获得的重建3D模型指导了训练数据的选择,通过实验证明了通过3D模型获取的几何信息和摄像机坐标来选择的困难正样本和困难负样本可以有效提升特定目标检索的性能。另外,从相同训练数据中学习得到的CNN描述符白化优于常用的PCA白化。我们还提出了一种新的可训练的广义均值(GeM)池化层,它泛化了最大池化和平均池化操作,能够提高检索性能。将所提出的方法应用于VGG网络,在基准数据集(Oxford5k、Paris6k和Holidays)上实现了最先进的性能。
引言
论文仍旧着重于无监督的图像检索微调训练,主要有如下内容:
- 构建
structure-from-motion(SfM)流程,生成苦难正样本和困难负样本,通过训练证明这两类数据均有利于检索任务训练; - 在同样的训练数据上学习白化有助于提升性能,并且证明将白化作为单独的后处理步骤比端到端的学习模式更有效;
- 提出一个可学习的池化层,在不改变描述符维度同时能够有效提升检索性能;
- 提出\(\alpha\)加权的查询扩展算法,更适用于紧凑的特征描述符。
通过
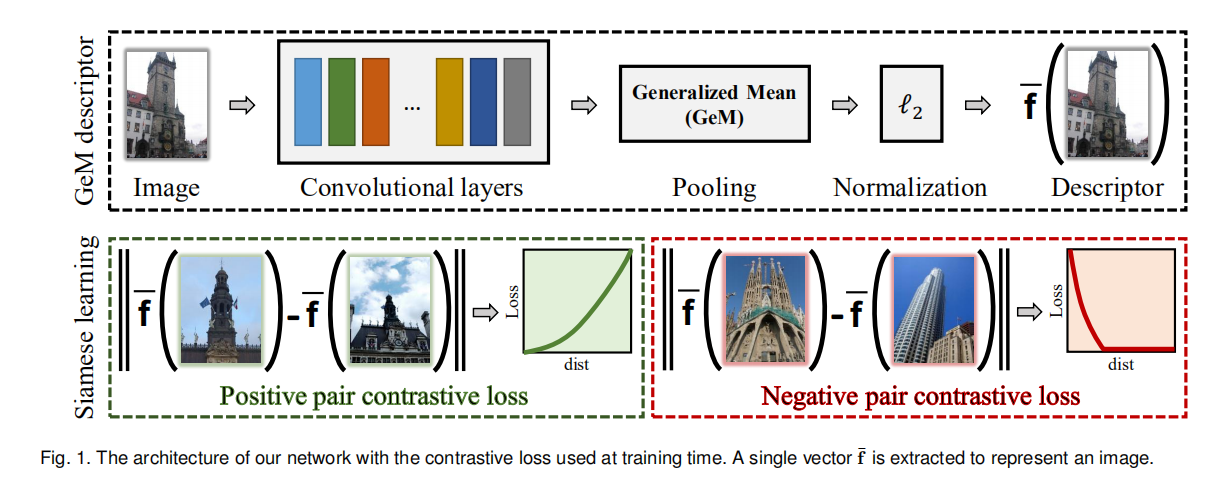
这篇论文扩展了CNN Image Retrieval Learns from BoW: Unsupervised Fine-Tuning with Hard Examples的工作,新增加了池化层GeM(generalized-mean)、基于多尺度的图像描述符构造以及一种新的查询扩展算法。
论文在引言中还特别提到Gordo的工作:Deep Image Retrieval: Learning global representations for image search和End-to-end Learning of Deep Visual Representations for Image Retrieval,表明两者最大的差别在于前者论文的重心在于端到端的学习以及RPN的使用(其中也有无监督训练数据的挖掘),而后者的重心在于困难训练数据的挖掘以及新的池化层GeM的使用(从这个角度来说,两位的工作是可以互补的)。
GeM
给定查询图像,卷积层输出是一个3D张量\(X\),其大小为\(W\times H\times K\),其中\(K\)表示最后卷积层的滤波器个数(输出特征图的数目)。\(X_{k}\)表示第\(k\in \{1,...,K\}\)特征图,大小为\(W\times H\)。论文假定最后卷积层输出后还经过了ReLU的过滤,所以所有激活值都是非负的。
池化层的作用是将3D激活\(X\)转换成为一维向量\(f\)。对于全局最大池化层(MAC向量)而言,其计算如下:
\[ f^{(m)}=[f^{(m)}_{1}, ..., f^{(m)}_{k}, ..., f^{(m)}_{K}]^{T}, \ f^{(m)}_{k}=\max_{x\in X_{k}}x \]
对于全局最大池化层(SPoC向量)而言,其计算如下:
\[ f^{(a)}=[f^{(a)}_{1}, ..., f^{(a)}_{k}, ..., f^{(a)}_{K}]^{T}, \ f^{(a)}_{k}=\frac{1}{\left|X_{k} \right|}\sum_{x\in X_{k}}x \]
论文参考了广义平均算法的实现,并提出了一个新的池化层 - 广义平均池化层(generalized-mean (GeM) pooling)。其实现如下:
\[ f^{(g)}=[f^{(g)}_{1}, ..., f^{(g)}_{k}, ..., f^{(g)}_{K}]^{T}, \ f^{(g)}_{k}=(\frac{1}{\left|X_{k} \right|}\sum_{x\in X_{k}}x^{p_{k}})^{\frac{1}{p_{k}}} \]
全局平均池化和全局最大池化都是广义平均池化层的特例,当\(p_{k}\to \infty\)就是最大池化操作;当\(p_{k}=1\)的时候就是平均池化操作。GeM输出的特征向量长度等同于\(K\),即每个特征图生成一个值。池化参数\(p_{k}\)可以手动设置,也可以通过学习获取,相应的求导计算如下:
\[ \frac{\partial f_{k}}{\partial x_{i}}=\frac{1}{\left|X_{k}\right|} f_{k}^{1-p_{k}}x_{i}^{p_{k}-1} \]
\[ \frac{\partial f_{k}}{\partial p_{k}}=\frac{f_{k}}{p_{k}^{2}}(log \frac{\left|X_{k} \right|}{\sum_{x\in X_{k}}x^{p_{k}}}+p_{k}\frac{\sum_{x\in X_{k}}x^{p_{k}}\log x}{\sum_{x\in X_{k}}x^{p_{k}}}) \]
可以为每个特征图设置可学习参数\(p_{k}\),也可以共享同一个值。论文使用后者,设置\(p_{k}=k, \forall k\in [1, K]\)。
对于MAC向量而言,每个2D特征图生成一个激活值,其等同于一块图像区域。一对MAC向量的计算可以看成是两组图像区域之间的比较,如下图2所示,论文对比了微调前后MAC向量中贡献了最大相似度的区域对,可以发现微调后对于感兴趣目标具有更大的判别力。

论文还展示了不同\(p\)值导致图像区域对于最终相似度的贡献,如下图4所示,\(p\)值越大,越聚焦于特定的图像区域(类似于MAC向量);\(p\)值越小,越多的图像区域能够提供重要属性(类似于SPoC向量)。

最后论文还显示了基于GeM进行微调训练后的特征向量匹配效果,如下图3所示(其实没看懂它的解释,反正就是好呗):

注意:网络最后包含了L2归一化操作,在后续描述中GeM描述符等同于L2归一化后的特征向量\(\tilde{f}\)
暹罗学习
论文构造了一个对比损失进行训练,假定图像对\((i,j)\)和对应标签\(Y(i,j)\in \{0,1\}\)(标签\(0\)表示负样本对,标签\(1\)表示正样本对),损失函数定义如下:
\[ L(i,j)=\begin{cases} \frac{1}{2}\left\| \tilde{f}_{i} - \tilde{f}_{j} \right\|^{2} & \text{ if } Y(i,j)=1 \\ \frac{1}{2}(max\{0, \tau-\left\| \tilde{f}_{i} - \tilde{f}_{j} \right\|\})^{2} & \text{ if } Y(i,j)=0 \end{cases} \]
其中\(\tilde{f}(i)\)表示图像\(i\)经过L2归一化后的GeM向量;\(\tau\)表示边界值(在后续实验中设置为\(\tau=0.1\)),当负样本对拥有足够的距离时,不参与训练。
后处理
论文主要提到了3个后处理步骤:白化、多尺度描述符以及查询扩展。
白化
论文还提到了后处理步骤白化操作,通过相同的训练数据进行学习。具体的实现没看懂,需要进一步查看代码。在后续实验章节论文还比较了端到端可学习的白化性能。
多尺度
类似于End-to-end Learning of Deep Visual Representations for Image Retrieval,论文也尝试了多尺度描述符,输入不同大小图像,生成GeM描述符之后进行求和,最后执行L2归一化得到最终描述符。通过实验证明了这种方式同样有效并且优于平均池化操作。
QE
论文还增强了查询扩展算法,在之前的实现中通过求和平均查询图像以及Top-n个排序图像的特征向量,执行L2归一化之后再次排序,论文称之为AQE(average query expansion)。这种实现方式中很难通过调整n的数量来适应不同的数据集。对此论文提出一种泛化模式,为每个初始查询得到的特征向量给予一个权重\((\tilde{f}(q)^{T}\tilde{f}(i))^{\alpha}\),称之为\(\alpha\)加权查询扩展(α-weighted query expansion (αQE))。当\(\alpha=0\)时,αQE等同于AQE。
数据集


介绍了无监督构建训练数据的流程,有兴趣的童鞋可以查看论文实现。
实验
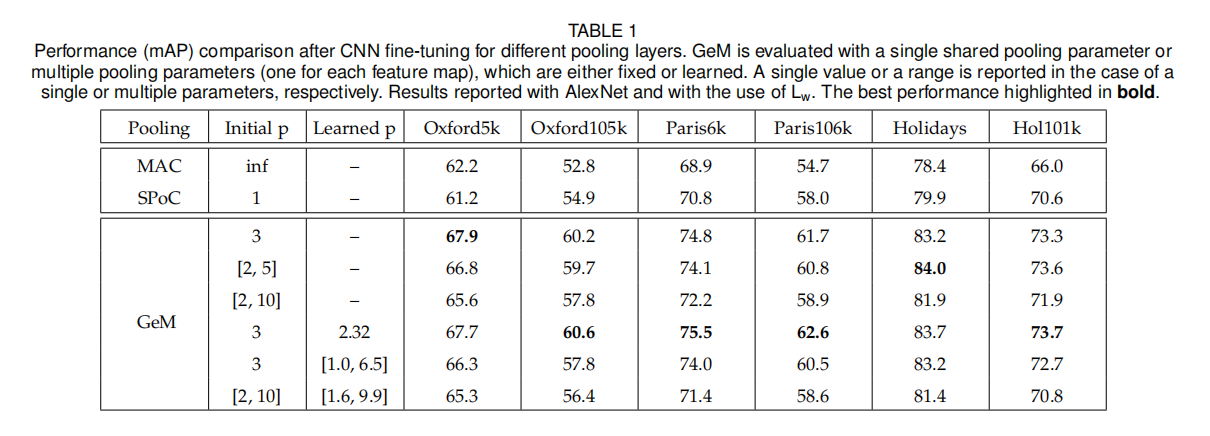
池化
下表一展示了经过微调训练后,不同池化层(全局平均池化、全局最大池化以及广义平均池化)的性能。论文设计了不同设置的超参数\(p\):
- 共享同一个超参数\(p\);
- 每个特征图拥有各自的\(p_{k}\);
- 固定\(p\)值或者可学习。
实验表明,单个可学习超参数\(p\)能够实现最好的性能,
- 固定\(p\)值和可学习\(p\)设置得到的训练性能类似,相对而言可学习\(p\)更好一些;
- \(p\)的初始值设置会影响最终学习结果。
在后续实验中,论文使用了可学习\(p\)的设置。
PCA白化
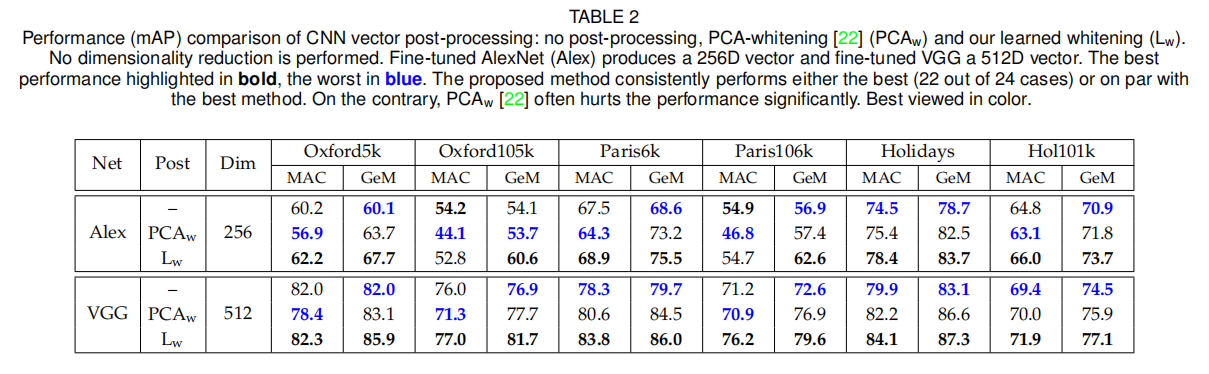
上表中论文比较了传统的PCA白化(称之为\(PCA_{w}\))与论文提出的白化方式(称之为\(L_{w}\))。可以发现,\(PCA_{w}\)在某些数据集上并不稳定,而\(L_{w}\)表现非常稳定,大部分情况下均能提升基准算法性能。
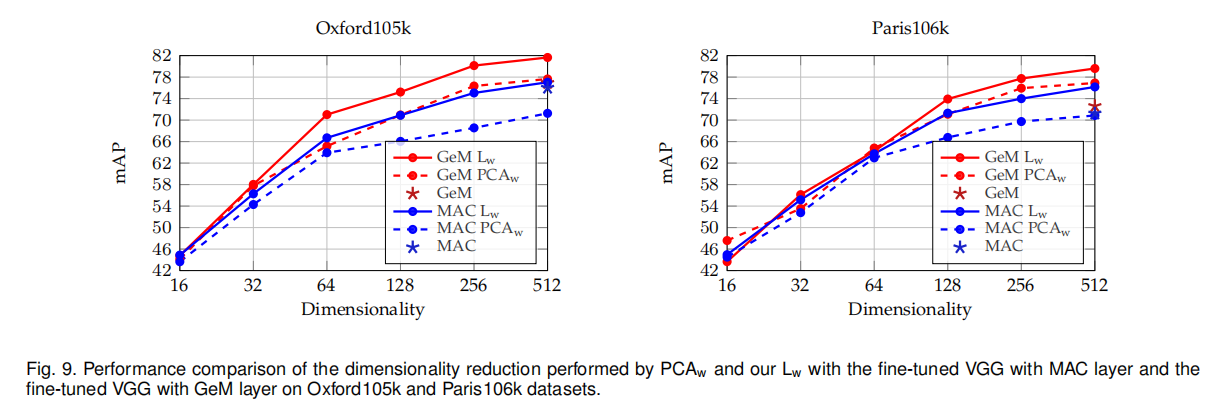
论文还比较了\(PCA_{w}\)和\(L_{w}\)在不同维度衰减下的表现,如下图9所示。
多尺度
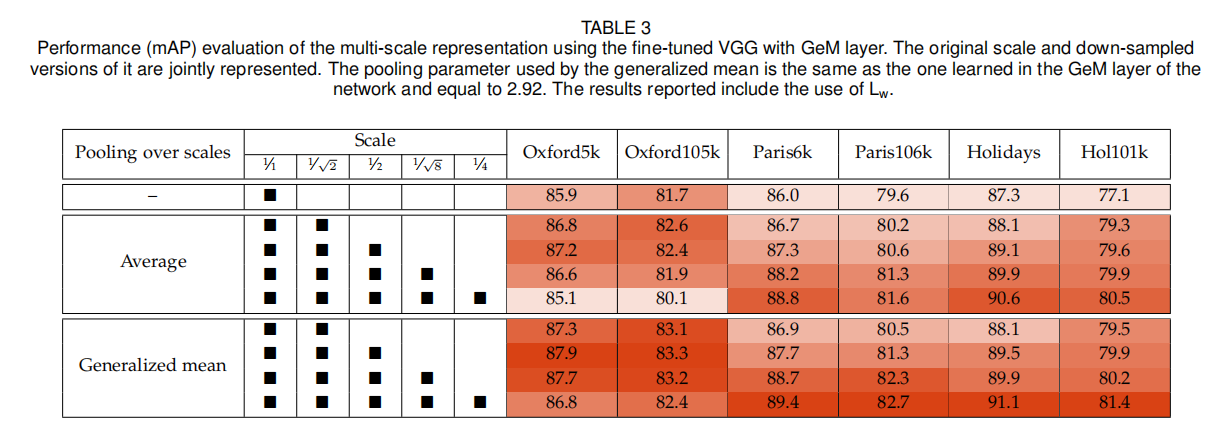
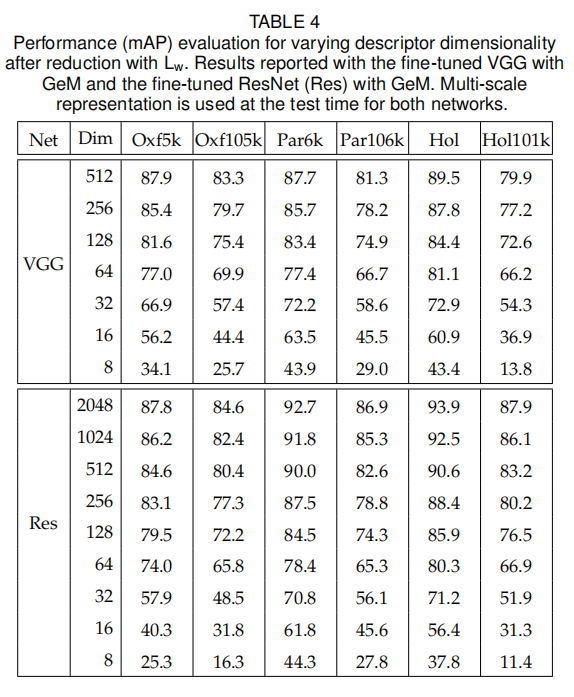
论文在上表三中展示了多尺度描述符的性能,可以观察到多尺度表示能够有效提升检索性能,不论是平均池化还是GeM。论文还在表四展示了不同维度下的多尺度描述符(使用\(1、\frac{1}{\sqrt{2}}、\frac{1}{2}\))性能。
查询扩展
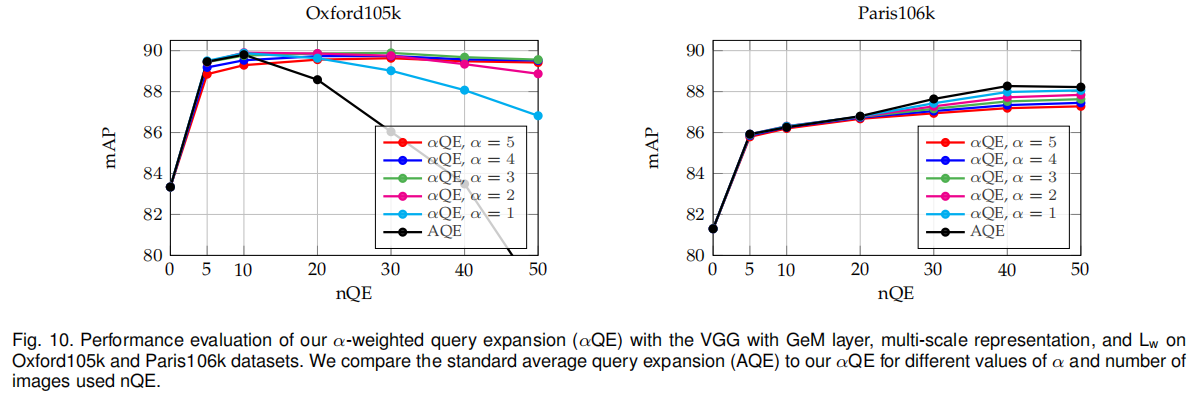
论文测试了不同\(\alpha\)值和\(n\)值下αQE的性能,如下图10所示。最终设置\(\alpha=3\)和\(nQE=50\)
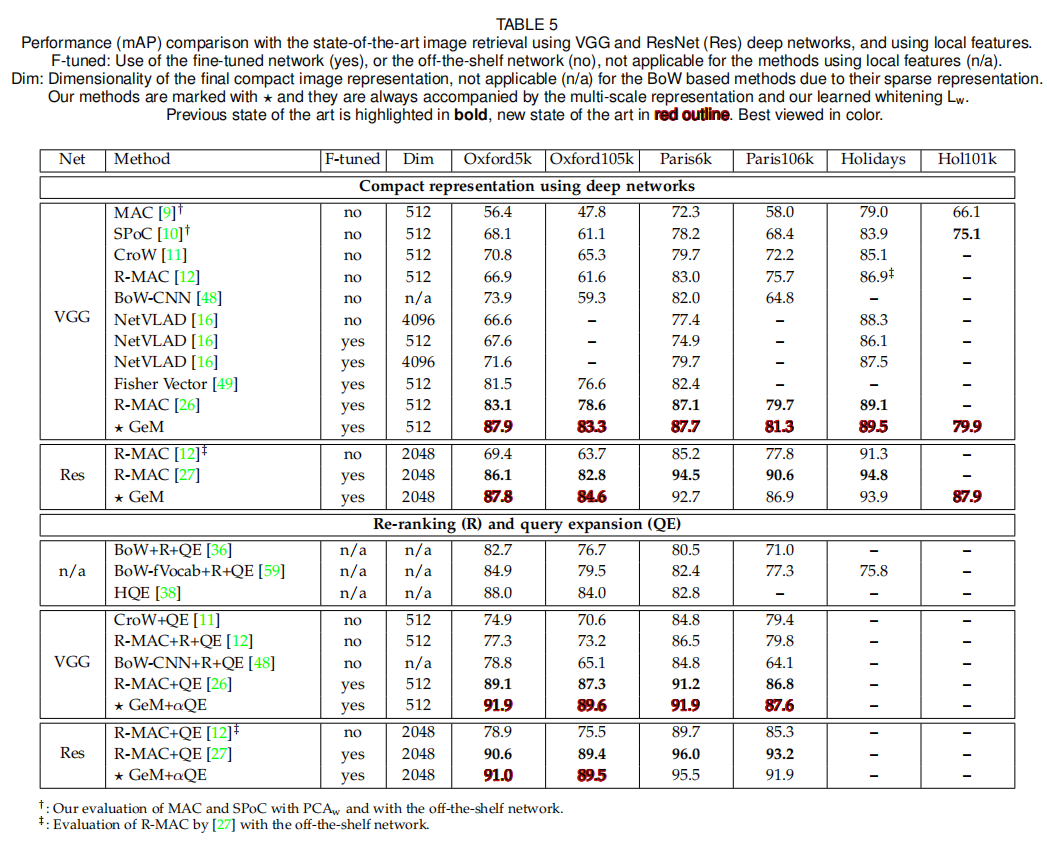
SOTA
小结
论文的创新点:
SfM自动数据清洗流程;- 广义平均池化层
GeM; CNN描述符白化;- α-加权查询扩展算法
αQE。
此外,论文通过详细的实验数据,证明了微调训练、对比损失、可学习白化以及多尺度描述符的有效性。
本文最大的创新点在于GeM的提出,另外也给出了详细的实验数据。结合之前的图像检索相关论文,逐渐形成了一个完整的图像检索算法架构:卷积网络+全局描述符+后处理算法(L2归一化/PCA白化/查询扩展/多尺度)