最新版本的PyTorch 1.3内置支持了Tensorboard ,实现模型、数据以及训练可视化
安装 除了安装PyTorch以外,还需要额外安装Tensorboard
1 conda install tensorboard
启动 启动tensorboard,指定文件路径,IP地址以及端口号
logdir:指定Tensorflow event files文件路径,通常设置为runs,会递归搜索runs文件夹内命名为*tfevents.*文件host:制定监听的主机名,默认为localhostport:监听端口,默认为60061 2 3 4 5 $ tensorboard TensorFlow installation not found - running with reduced feature set . W1211 15 :14 :25.693824 140379677206272 plugin_event_accumulator.py:294 ] Found more than one graph event per run, or there was a metagraph containing a graph_def, as well as one or more graph events. Overwriting the graph with the newest event. W1211 15 :14 :25.694132 140379677206272 plugin_event_accumulator.py:322 ] Found more than one "run metadata" event with tag step1. Overwriting it with the newest event. TensorBoard 2.0 .0 at http ://192.168 .0 .112 :7878 / (Press CTRL+C to quit)
常见问题 pytorch ImportError: TensorBoard logging requires TensorBoard with Python summary writer installed 参考:pytorch ImportError: TensorBoard logging requires TensorBoard with Python summary writer installed
安装tensorboard即可
tensorboard shows a SyntaxError: can't assign to operator 在JupyterLab上启动Tensorboard,发现如上问题,参考tensorboard shows a SyntaxError: can't assign to operator 。解决方案:在命令前添加!即可
1 !tensorboard --logdir =runs
can't assign to operator 在PyCharm启动tensorboard时出现上述错误,参考运行tensorboard --logdir=log遇到的错误之can't assign to operator ,新开一个命令行窗口启动即可
入口函数 SummaryWriter 类提供了一个高级API,用于在给定目录中创建事件文件并向其中添加摘要和事件。该对象异步更新文件内容,这样允许训练程序直接在训练过程中调用方法循环向文件中添加数据,而不会减慢训练速度
所有的PyTorch数据写入操作均通过SummaryWriter实现,声明如下:
1 2 3 4 from torch.utils.tensorboard import SummaryWriter# default `log_dir` is "runs" - we'll be more specific here writer = SummaryWriter(' runs/fashion_mnist_experiment_1')
需要指定文件保存路径,通常设置为runs
注意:后续的写入操作完成后调用close函数结束
add_image 增加图像数据到Tensorboard,使用函数add_image
注意:需要额外安装pillow
1 def add_image(self , tag , img_tensor , global_step =None, walltime =None, dataformats ='CHW') :
tag:数据标识符img_tensor:torch.Tensor格式图像使用如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import cv2import torchfrom torch.utils.tensorboard import SummaryWriter# default `log_dir` is "runs" - we'll be more specific here writer = SummaryWriter(' runs/test') lena = cv2.imread(' lena.jpg') lena = cv2.cvtColor(lena, cv2.COLOR_BGR2RGB) lena_tensor = torch.from_numpy(lena.transpose((2, 0, 1))) print(lena_tensor.size()) # 写入 writer.add_image(' lena', lena_tensor) writer.close()
完成上述操作后,在tensorboard页面菜单栏选择IMAGES标签,会出现写入的lena图像
可以在同一个标签上添加多个图像,在页面上拖动滑动条显示不同的图像
add_graph 调用函数add_graph 实现模型可视化
1 def add_graph(self , model , input_to_model =None, verbose =False) :
model:torch.nn.Module(待绘制的模型)input_to_model:模型输入数据,可输入单张图像(torch.Tensor)或者图像列表(list of torch.Tensor)verbose:是否在控制台详细打印图结构使用如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 import torch.nn as nnimport torch.nn.functional as Fimport torchvisionimport torchvision.transforms as transforms# 定义模型 class Net (nn .Module ): def __init__(self ): super(Net , self ).__init__() self.conv1 = nn.Conv2d (1, 6, 5) self.pool = nn.MaxPool2d (2, 2) self.conv2 = nn.Conv2d (6, 16, 5) self.fc1 = nn.Linear (16 * 4 * 4, 120) self.fc2 = nn.Linear (120, 84) self.fc3 = nn.Linear (84, 10) def forward(self , x ): x = self.pool(F .relu (self .conv1 (x ))) x = self.pool(F .relu (self .conv2 (x ))) x = x.view(-1, 16 * 4 * 4) x = F .relu(self .fc1 (x )) x = F .relu(self .fc2 (x )) x = self.fc3(x ) return x net = Net () print(net ) # 获取数据 # transforms transform = transforms.Compose ( [transforms .ToTensor (), transforms.Normalize ((0.5,), (0.5,))]) # datasets trainset = torchvision.datasets.FashionMNIST ('./data' , download =True , train =True , transform =transform ) testset = torchvision.datasets.FashionMNIST ('./data' , download =True , train =False , transform =transform ) # dataloaders trainloader = torch.utils.data.DataLoader (trainset , batch_size =4, shuffle =True , num_workers =2) testloader = torch.utils.data.DataLoader (testset , batch_size =4, shuffle =False , num_workers =2) # constant for classes classes = ('T -shirt /top' , 'Trouser ', 'Pullover ', 'Dress ', 'Coat ', 'Sandal ', 'Shirt ', 'Sneaker ', 'Bag ', 'Ankle Boot ') # get some random training images dataiter = iter(trainloader ) images, labels = dataiter.next() print(images .size ()) ## 写入模型 writer.add_graph(net , input_to_model =images ,verbose =True ) writer.close()
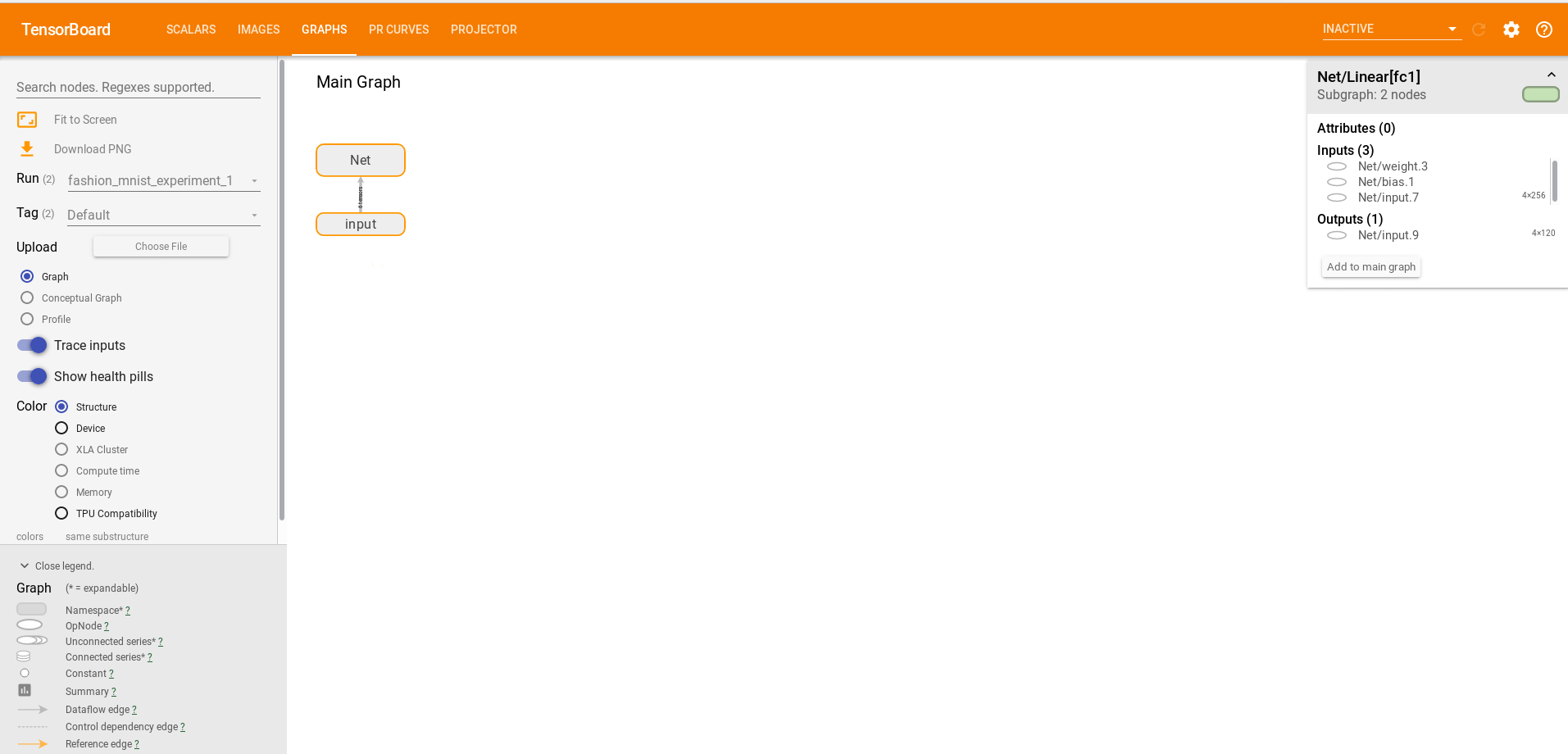
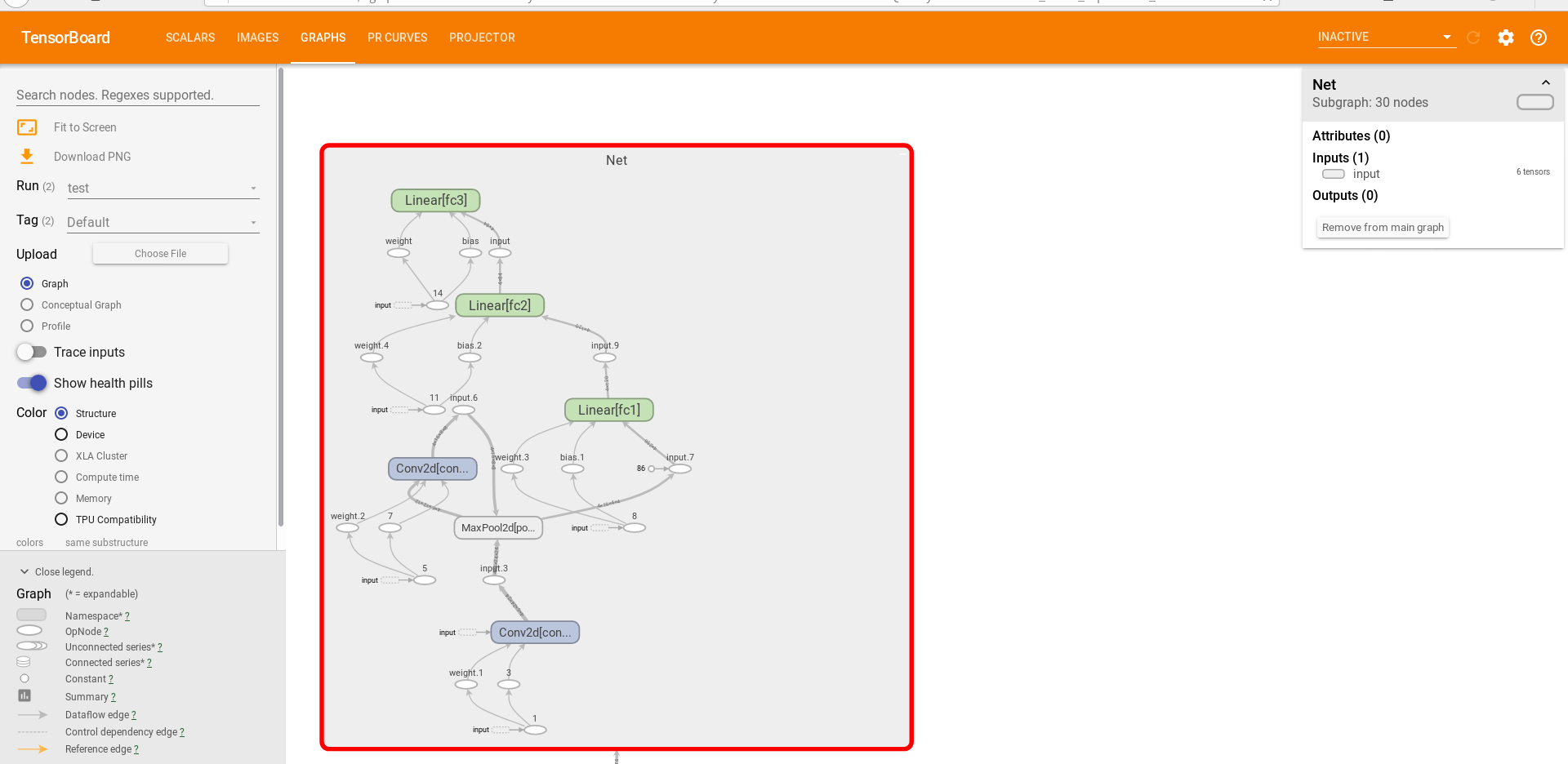
完成上述操作后,在tensorboard页面菜单栏选择GRAPHS标签,会可视化模型,双击即可扩展模型细节
add_embedding 调用函数add_embedding 实现高维数据可视化
1 def add_embedding(self, mat, metadata =None, label_img =None, global_step =None, tag ='default' , metadata_header =None):
mat:矩阵,每行表示一个数据点的特征向量,其大小为metadata:字符串列表,表示标签label_imgs:相对于每个数据点的图像列表,其大小为测试如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import keyword import torch meta = []while len(meta )<100 : meta = meta +keyword.kwlist # get some strings meta = meta [:100 ]for i, v in enumerate(meta ): meta [i] = v+str(i) label_img = torch.rand (100 , 3 , 10 , 32 ) for i in range(100 ): label_img[i]*=i/100.0 writer.add_embedding(torch.randn(100 , 5 ), metadata=meta , label_img=label_img) writer.close()
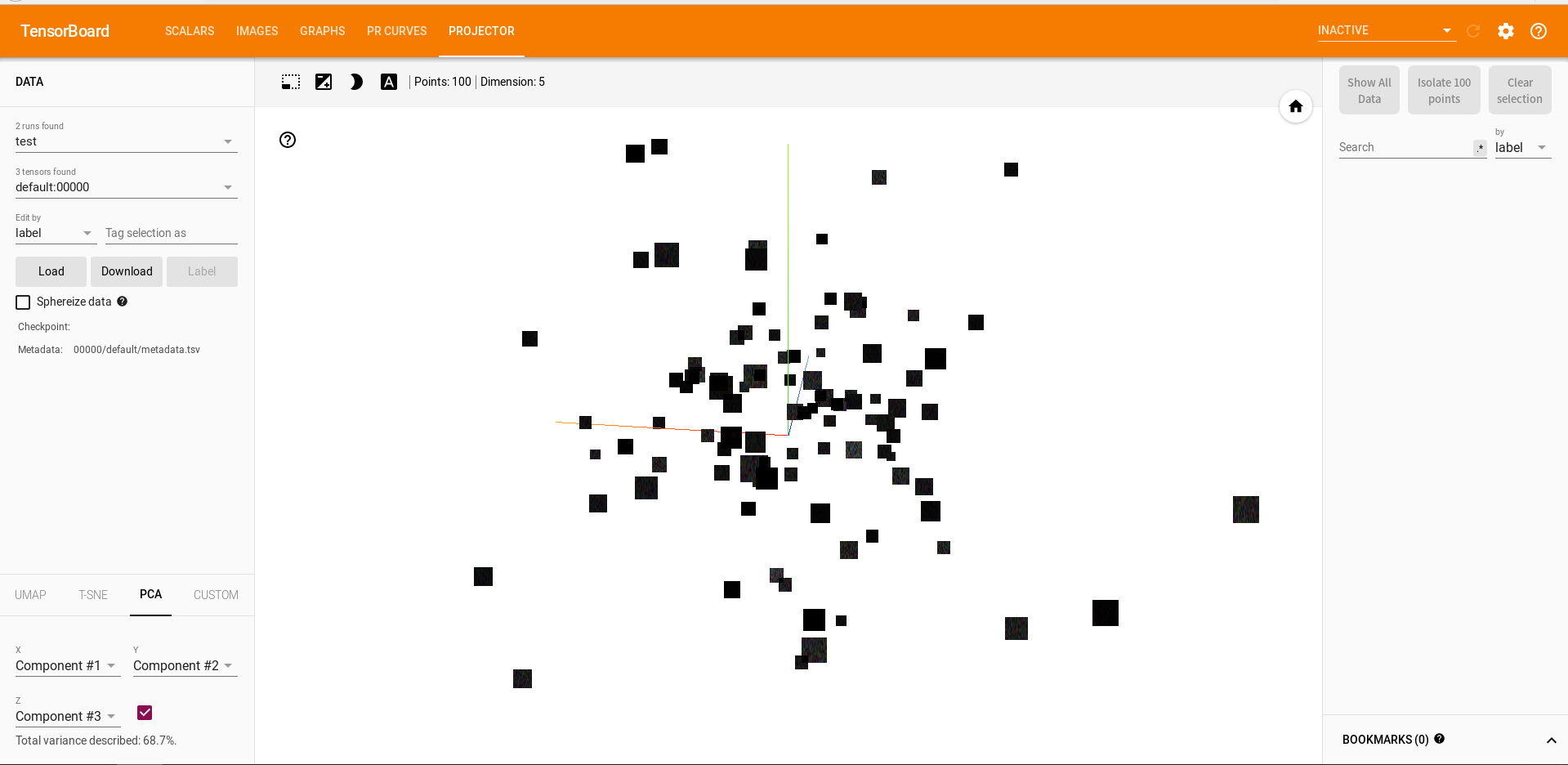
完成上述操作后,在tensorboard页面菜单栏选择PROJECTOR标签,将高维数据投影到3维空间中
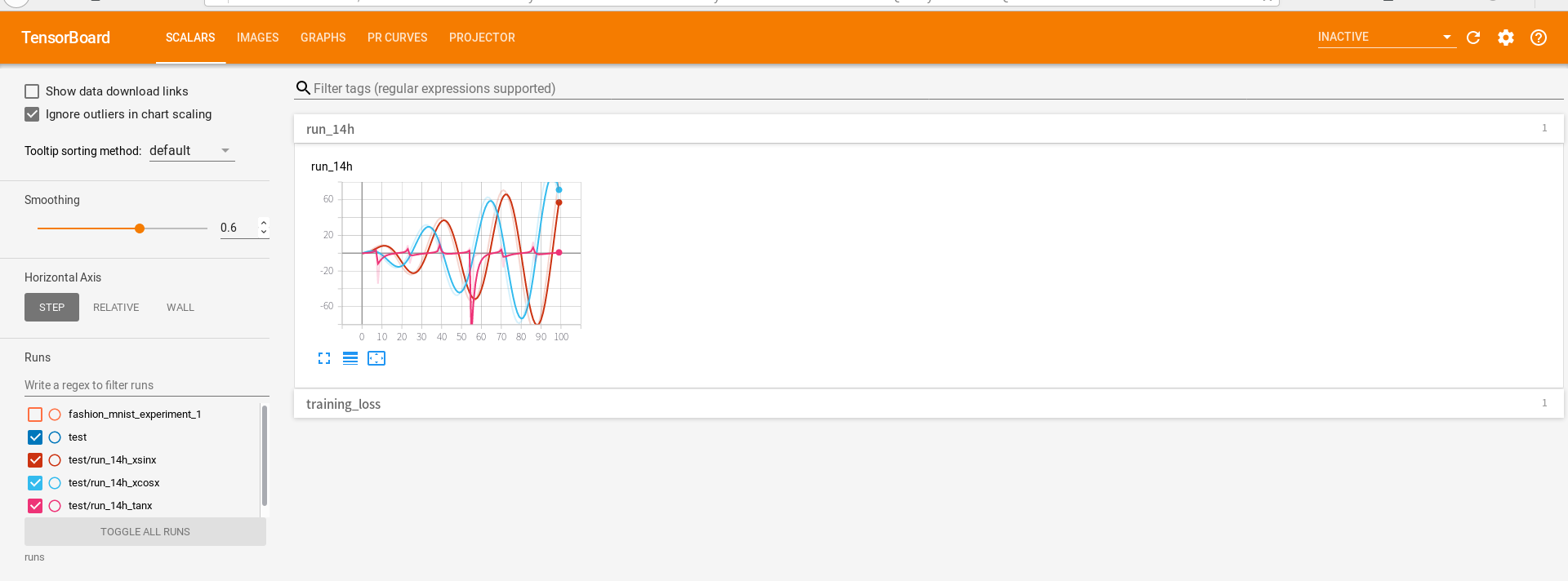
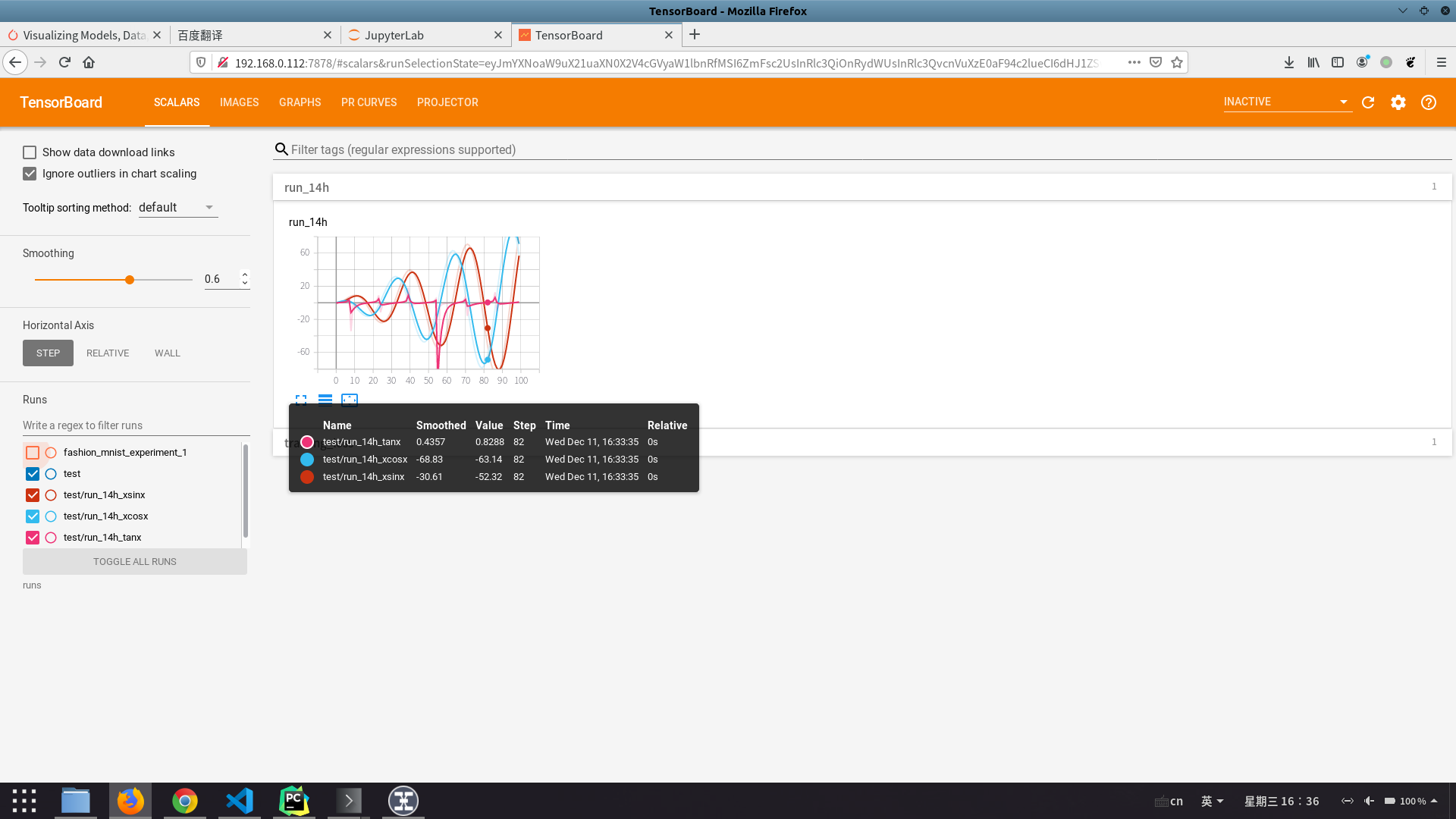
add_scalar 调用函数add_scalar 或者add_scalars 实现训练数据实时写入
1 2 def add_scalar(self , tag , scalar_value , global_step =None, walltime =None) : def add_scalars(self , main_tag , tag_scalar_dict , global_step =None, walltime =None) :
main_tag:标识符scalar_value:浮点值(float)或者字符串(str)tag_scalar_dict:dict,以键值对的方式保存子标签和相应的值global_step:步长实现如下:
1 2 3 4 5 6 7 8 r = 5 for i in range(100 ): writer.add_scalars('run_14h' , {'xsinx' :i*np .sin(i/r), 'xcosx' :i*np .cos(i/r), 'tanx' : np.tan(i/r)}, i) writer.close()
点击菜单栏的SCALARS标签,能够显示实时的训练数据
将鼠标移动到图中,会显示不同阶段相应的训练结果
add_figure 作用与add_image类似,均是显示图像到tensorboard页面,不同的是add_figure指定渲染Matplotlib图像
1 def add_figure(self , tag , figure , global_step =None, close =True, walltime =None) :
tag:标识符figure:matplotlib.pyplot.figure格式图像global_step:步长实现如下:
1 2 3 4 5 6 7 8 9 import matplotlib.pyplot as plt fig = plt.figure () plt.imshow (lena) writer.add_figure ('plt' , fig, 0 ) fig = plt.figure () plt.imshow (gray, cmap="Greys" ) writer.add_figure ('plt' , fig, 1 )
写入后即可在IMAGES页面查询
add_pr_curve 调用函数add_pr_curve 绘制精度召回曲线(precision-recall curve)
1 2 def add_pr_curve(self, tag, labels, predictions, global_step =None, num_thresholds =127, weights =None, walltime =None):
tag:数据标识符labels:真实标签。取值为二值标签predictions:元素被归为正确的概率,取值为0或1global_step:步长num_thresholds:绘制曲线的阈值数量1 2 3 4 5 6 7 labels = np .random .randint(2 , size=100 ) # binary label print (labels )predictions = np .random .rand(100 ) print (predictions)writer.add_pr_curve('pr_curve', labels , predictions, 0 ) writer.close ()
相关阅读 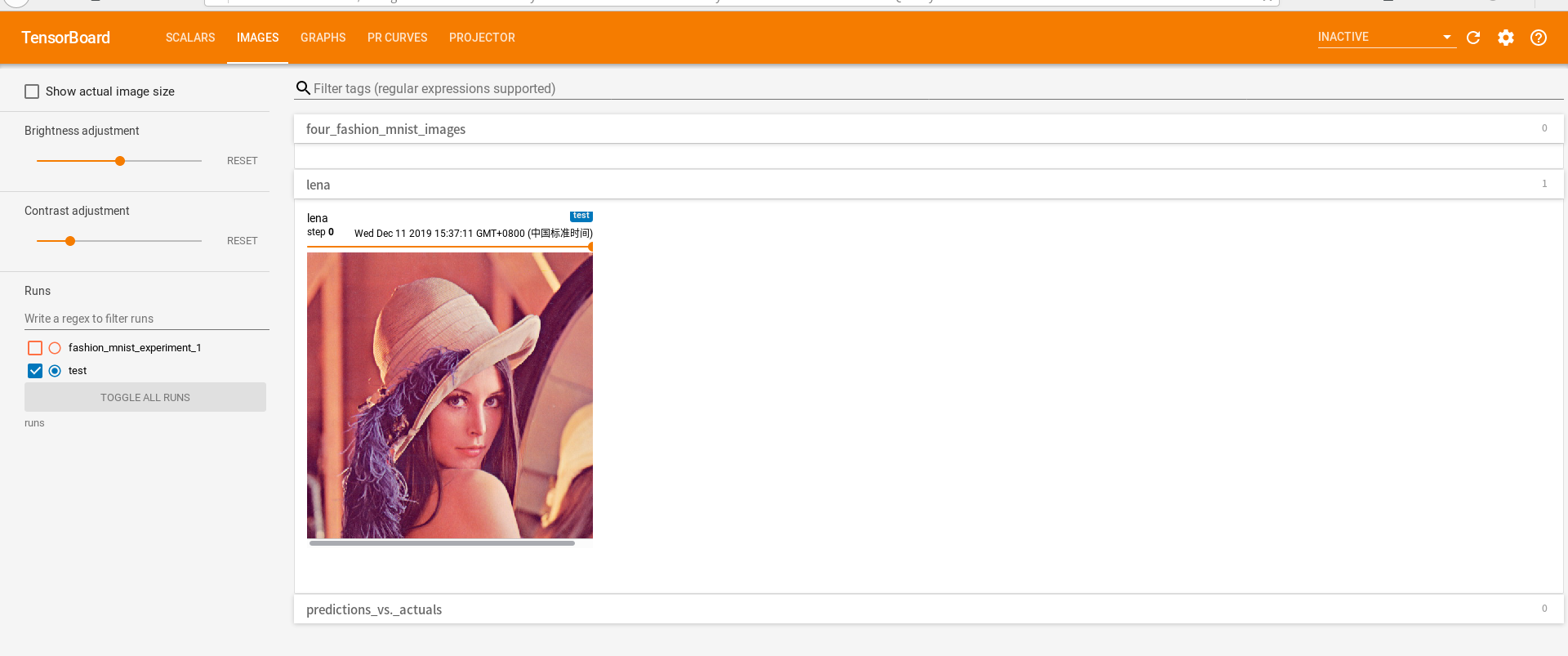
未找到相关的 Issues 进行评论
请联系 @zjykzj 初始化创建