Learning Efficient Convolutional Networks through Network Slimming
原文地址:Learning Efficient Convolutional Networks through Network Slimming
官方实现:Eric-mingjie/network-slimming
复现地址:ZJCV/NetworkSlimming
摘要
The deployment of deep convolutional neural networks (CNNs) in many real world applications is largely hindered by their high computational cost. In this paper, we propose a novel learning scheme for CNNs to simultaneously 1) reduce the model size; 2) decrease the run-time memory footprint; and 3) lower the number of computing operations, without compromising accuracy. This is achieved by enforcing channel-level sparsity in the network in a simple but effective way. Different from many existing approaches, the proposed method directly applies to modern CNN architectures, introduces minimum overhead to the training process, and requires no special software/hardware accelerators for the resulting models. We call our approach network slimming, which takes wide and large networks as input models, but during training insignificant channels are automatically identified and pruned afterwards, yielding thin and compact models with comparable accuracy. We empirically demonstrate the effectiveness of our approach with several state-of-the-art CNN models, including VGGNet, ResNet and DenseNet, on various image classification datasets. For VGGNet, a multi-pass version of network slimming gives a 20x reduction in model size and a 5x reduction in computing operations.
深度卷积神经网络(CNNs)的高计算量在很大程度上阻碍了其在实际应用中的使用。在本文中,我们提出了一种新的CNN学习方案,它能够同时:(1)减小模型尺寸;2) 减少运行时内存占用;3)在不影响精度的前提下,减少计算操作次数。这是通过在网络中以一种简单而有效的方式加强通道稀疏性来实现的。与现有的许多方法不同,该方法直接适用于现代CNN结构,训练过程开销最小,所得到的模型不需要特殊的软硬件加速器。我们称我们的方法为网络瘦身,它以宽而大的网络作为输入模型,在训练过程中,不重要的通道会被自动识别并在训练后剪枝,从而得到具有相当精度的精简模型。我们用几种最新的CNN模型(包括VGGNet、ResNet和DenseNet)对不同的图像分类数据集进行了实验验证。对于VGGNet,网络瘦身的多通道版本使模型大小减少了20倍,计算操作减少了5倍。
简介
在模型精度足够的前提下,如何将模型部署到嵌入式设备上,需要考虑如下3个方面:
- 模型大小。嵌入式设备的磁盘空间是否支持保存模型;
- 运行时内存。嵌入式设备的内存空间是否支持模型推理过程中额外产生的内存空间;
- 计算能力。嵌入式设备是否有足够的计算能力能够保证较短时间内完成模型推理。
论文提出的Network Slimming是一个通道剪枝方法。在训练过程中,通过L1正则化将BN层的缩放因子进行稀疏训练,使我们能够识别不重要的通道(或神经元,也就是缩放因子大小趋近于0)。因为每个缩放因子都对应于一个特定的通道(或者全连接层中的神经元),所以就可以进行通道剪枝操作
网络压缩
网络压缩大体可分为以下4个方面:
低秩分解
通过低秩矩阵(low-rank matrix)来模拟神经网络中的权重矩阵,比如奇异值分解(singular value decomposition, SVG)
- 优点:对全连接层压缩大约
3倍 - 缺点:对模型计算时间没有明显加速,因为
CNN的主要计算操作位于CNN层
权重量化
HashNet提出了权重量化(weight quantization),在运行前,将网络权重哈希到不同的组,每组共享权重值
- 优点:仅需保存共享权重和相应的下标,能够极大的降低存储空间;
- 缺点:对于运行时内存和速度并没有进行优化,因为推理过程中产生的额外权重需要单独存放,无法共享
同时还有其他论文提出了二元/三元量化(binary/ternary weights),也就是将权重值量化为{-1, 1}或者{-1, 0, 1}
- 优点:能够生成很小的模型,并且在推理上有极大加速;
- 缺点:会产生较大的精度损失
权重剪枝/稀疏
分为两部分:
- 针对单个权重(
individual weights)进行剪枝,称为非结构化剪枝- 优点:能够减少模型大小和推理内存;
- 缺点:需要使用专用稀疏矩阵运算库和/或硬件实现加速。
- 针对网络结构(神经元或者通道)进行剪枝操作,称为结构化剪枝/稀疏(
structured pruning / sparsifying)- 优点:不想要特定的库就能实现模型加速,同时还能减少模型大小和推理内存
本文提出的Network Slimming利用L1正则化对BN层缩放因子进行稀疏训练,完成训练后再进行通道级别剪枝操作(去除缩放因子大小趋近于0所对应的通道或者神经元),属于结构化剪枝方式
神经架构搜索
给定搜索空间(多少种算子、模块和架构)和计算资源(限定存储空间或硬件计算量),通过强化学习等方式进行模块级别或者网络级别的优化
网络剪枝和神经架构搜索(Neural Architecture Learning)类似,都是进行新模型的搜索,不同之处是网络剪枝需要更少的训练资源和训练时间
Network Slimming
公式推理
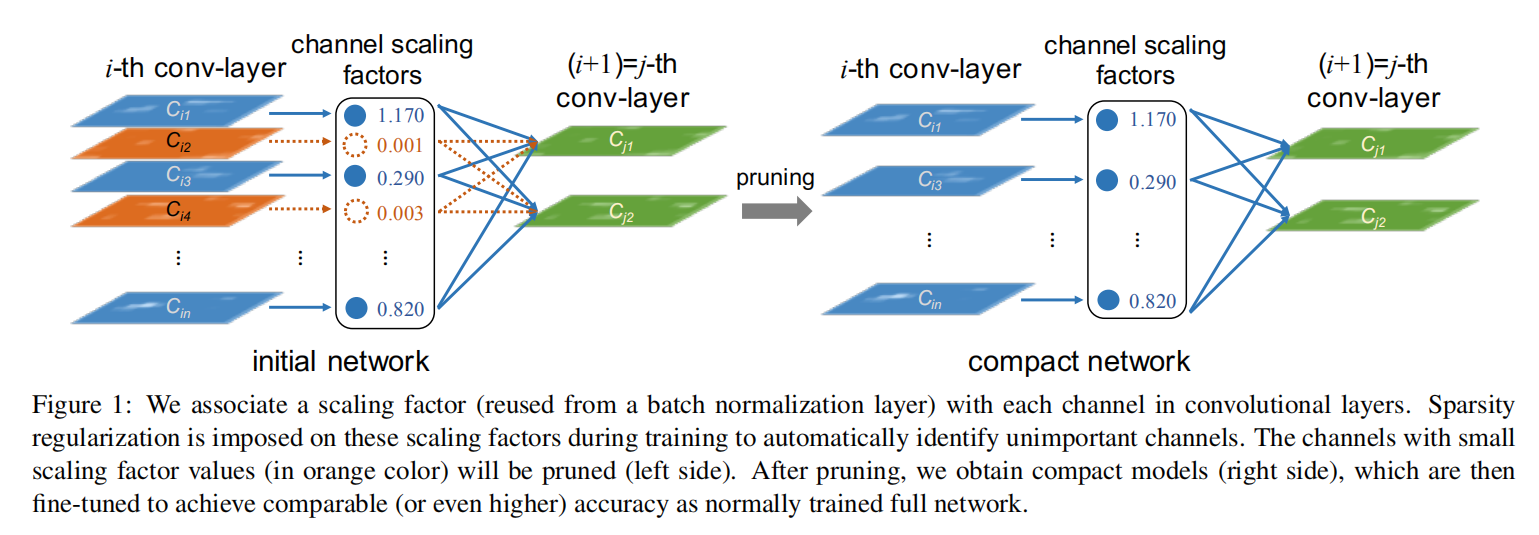
理想情况下,对每个通道设置一个缩放因子,应用于该通道的输出向量。在训练过程中,级联训练网络和这些缩放因子;完成训练后,去除小缩放因子对应的通道,即可实现通道剪枝操作。其训练阶段的目标函数实现如下:
论文使用
由于它们与网络权值联合优化,网络可以自动识别不重要的通道,在不影响泛化性能的前提下,可以安全地去除这些通道。
BN层
BN层实现如下:
BN层的输入/输出;
BN拥有缩放/偏移因子,能够对输入激活进行内部协方差校正。论文直接使用
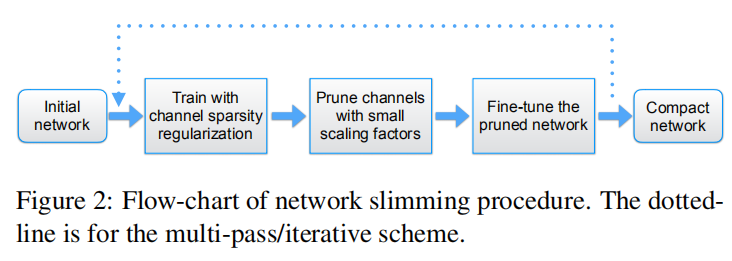
实现流程
- 稀疏训练中,对目标函数添加针对
BN层缩放因子的L1正则化进行级联训练; - 完成训练后,统计所有
BN层缩放因子大小,计算全局过滤阈值; - 完成剪枝后,对剪枝模型进行微调训练,增强模型性能。
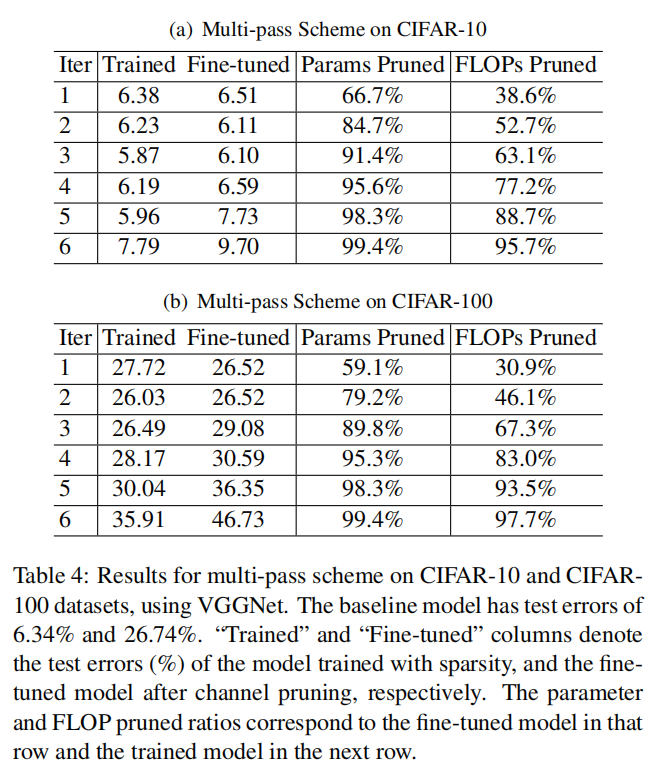
有时单次剪枝比例过大有可能会导致模型性能下降,可以通过多次剪枝操作进行优化,也就是说,每次剪枝小比例通道,重新进行稀疏训练后,再次进行剪枝。如下图所示
处理跨层连接以及前激活结构
BN层有可能会出现在卷积层之前(pre-activation structure),以及残差连接结构中上一层的输出是后续多个层的输入(cross layer connection),这些具体实现也会对实际通道剪枝产生困难。
在这些结构中,需要对每层的输入通道进行剪枝。论文提出新建一个channel selection层来加快具体实现
查看源码并没法发现channel selection有更好的作用???
实验
训练
- 数据
- 批量大小
64(作用于CIFAR和SVNH)256(作用于ImageNet和MNIST)
- 批量大小
- 训练
- 次数
160轮(作用于CIFAR)20轮(作用于SVHN)60轮(作用于ImageNet)30轮(作用于MNIST)
- 优化器:
SGD - 学习率:初始设置为
0.1- 作用于
CIFAR/SVHN:在整个训练轮数的50%和75%时除以10 - 作用于
ImageNet/MNIST:在整个训练轮数的1/3和2/3时除以10
- 作用于
- 权重衰减:
1e-4 Nesterov动量:0.9
- 次数
- 初始化
- 所有
BN层缩放因子初始化为0.5
- 所有
CIFAR10验证集上进行了网格搜索:
- 对于
VGGNet模型,使用 - 对于
ResNet和DenseNet模型以及在ImageNet上训练的VGG-A,使用
微调
完成剪枝后,论文使用和训练同样的设置对模型进行微调优化
结果
Table-1/Table-2证明了Network Slimming的有效性
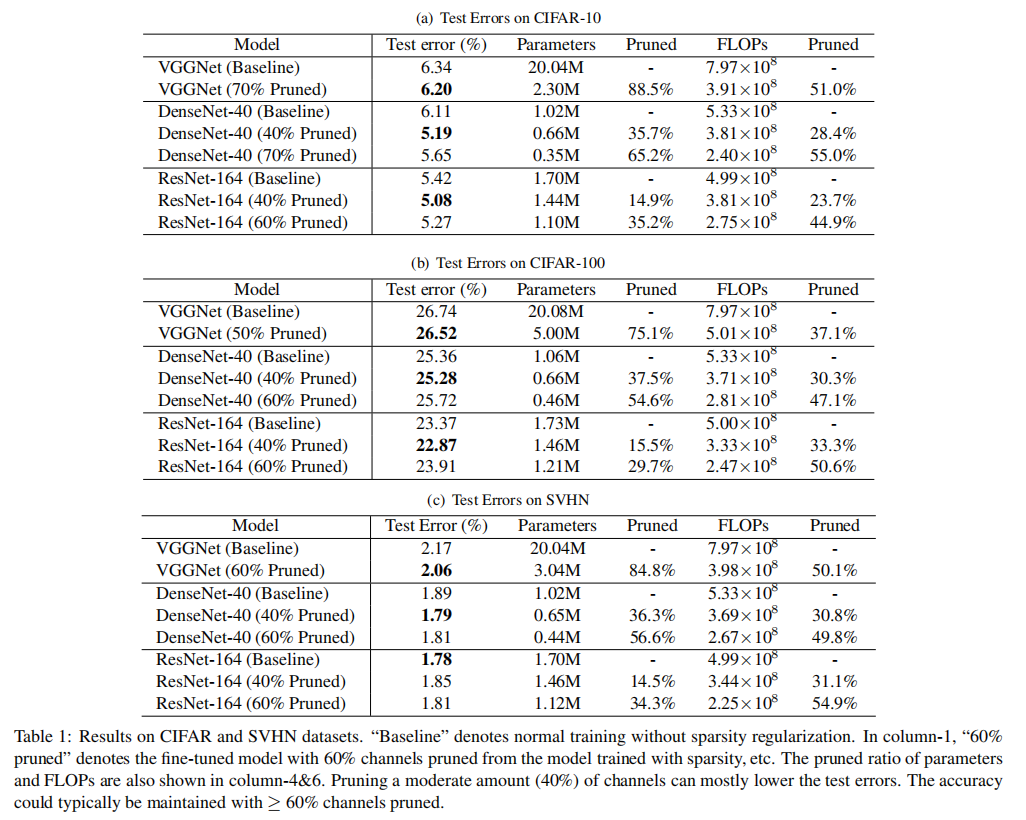
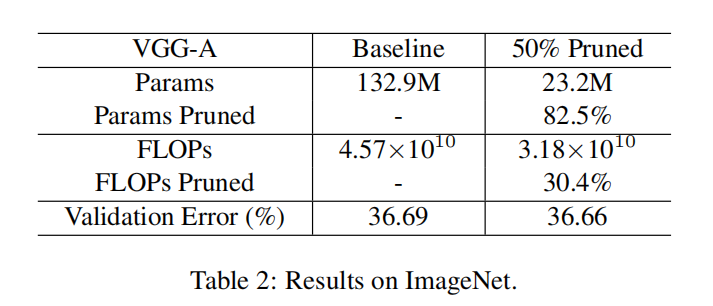
Table-4证明了多轮剪枝的有效性
分析
论文分析了训练超参数
关于剪枝率
DenseNet-40在CIFAR-10上以
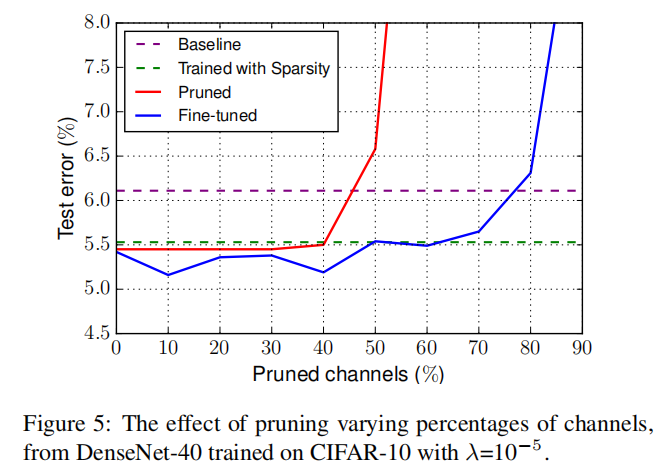
从图中可知,当剪枝比率超过某一阈值的时候,剪枝才会得到更差的效果
关于稀疏训练超参数
在目标函数中加入缩放因子的L1正则化的目的是希望更多的缩放因子趋近于0,超参数
基于VGGNet在CIFAR10上的训练,论文统计了不同
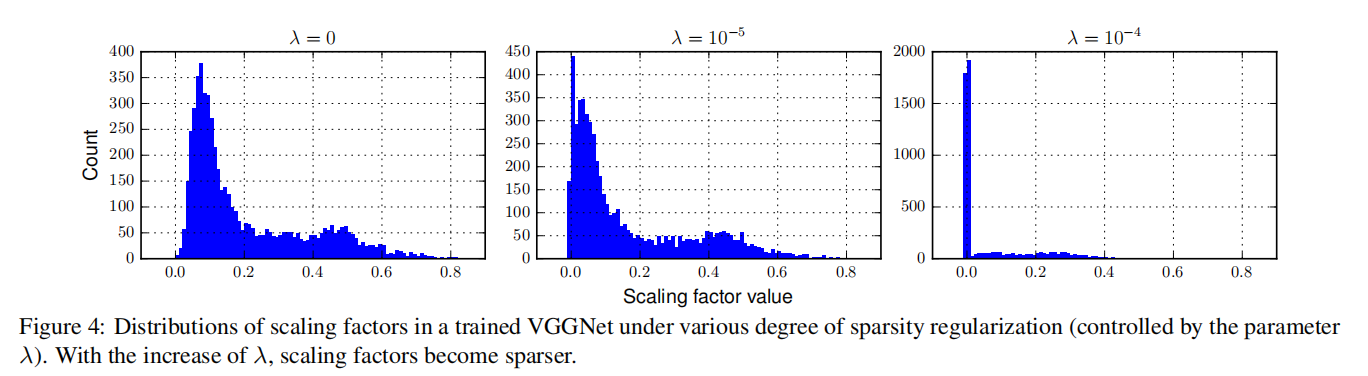
从实验结果来看,更大的0的缩放因子
小结
Network Slimming思路简单清晰,针对BN层缩放因子进行稀疏化训练,再进行剪枝-微调操作,从实验结果看确实能够实现模型大小、推理计算量以及内存的下降。其稀疏化训练关键的超参数0,那么表示剪枝通道中拥有大量的有效参数,可以减少剪枝率,进行多次剪枝来实现更好的结果;或者提高0
Network Slimming是基于Flops进行计算量的衡量,实际操作过程中会发现并不能够简单的将Flops等同于推理速度,还需要额外考虑内存访问以及模型并行计算的时间损耗,需要实际计算后才能够判断是否推理时间能够有效降低
论文中的Network Slimming使用了VGGNet、ResNet以及DenseNet进行了测试,在后续发展中又出现了更多的模型和算子,比如MobileNet(深度卷积)/ShuffleNet(分组卷积)系列。在实现过程中,也发现网络剪枝后还需要自定义模型,这也是很大的一部分工作
在实际实验过程中,也会发现结构化剪枝算法在特定数据集上对于某些架构的剪枝效果非常好,但是对于某些架构就很一般,这也是一个值得思考的问题?
Gitalk 加载中 ...