Distilling the Knowledge in a Neural Network
原文地址:Distilling the Knowledge in a Neural Network
原文地址
A very simple way to improve the performance of almost any machine learning algorithm is to train many different models on the same data and then to average their predictions. Unfortunately, making predictions using a whole ensemble of models is cumbersome and may be too computationally expensive to allow deployment to a large number of users, especially if the individual models are large neural nets. Caruana and his collaborators have shown that it is possible to compress the knowledge in an ensemble into a single model which is much easier to deploy and we develop this approach further using a different compression technique. We achieve some surprising results on MNIST and we show that we can significantly improve the acoustic model of a heavily used commercial system by distilling the knowledge in an ensemble of models into a single model. We also introduce a new type of ensemble composed of one or more full models and many specialist models which learn to distinguish fine-grained classes that the full models confuse. Unlike a mixture of experts, these specialist models can be trained rapidly and in parallel.
几乎所有机器学习算法都能够实现的一个简单的提取性能的方法是在同一数据上训练许多不同的模型,然后对它们的预测进行平均。不幸的是,使用一整套模型进行预测是很麻烦的,而且可能计算成本太高,无法部署到大量用户,特别是如果单个模型是大型神经网络。Caruana和他的合作者已经证明,可以将集成模型中的知识压缩到一个更易于部署的单一模型中,我们使用不同的压缩技术进一步提高了这种方法。我们在MNIST上取得了一些令人惊讶的结果,并且我们证明了通过将模型集合中的知识提取到单个模型中,可以显著改进大量使用的商业系统的声学模型。我们还介绍了一种新的集成方式,它由一个或多个完整模型以及许多专家模型(学习区分完整模型混淆的细粒度类别)组成。与集合专家模型不同,这些特定的识别模型可以快速并行地进行训练。
引言
论文首先介绍了本文的灵感来源:
- 昆虫在幼年期和成年期拥有完全不同的形态,能够适应不同的需求,即幼年期更倾向于获取能量和营养;成年期更倾向于迁移和生产
- 对于模型而言,在训练和推理阶段也拥有不同的需求,即训练阶段需要从大数据中提取特征;推理阶段更关注于延迟和计算资源
提出猜想:是不是可以在训练阶段使用一个或者多个大模型进行训练提取特征,然后在这些知识转移到一个小模型用于推理。
论文提出了多个在之后知识蒸馏领域常用的术语:
soft targets:使用大模型输出的类概率进行训练,称为软目标。如果有多个大模型,那么使用它们输出的类概率的算术平均或者几何平均;hard targets:标准的训练方式是使用类标签生成的类概率进行训练(one-hot向量,正确标签设为1,其余设为0),称为硬目标。logits:模型的输出结果,即softmax层的输入向量
蒸馏
logits;Softmax层计算的类概率;1,设置更高的softer的概率分布。
蒸馏实现流程:
- 训练大模型,使用高的蒸馏温度;
- 训练小模型,使用两个目标函数
- 使用大模型的输出概率作为
soft targets,使用大模型训练时同样的蒸馏温度进行交叉熵计算; - 使用正确标签作为
hard targets进行正常训练,其蒸馏温度设置为1; - 完成两个目标函数的计算后进行加权平均;
- 使用大模型的输出概率作为
注意1:论文在实验中发现对hard targets使用相对较低的权重能够得到更好的小模型
注意2:如果设置了高的蒸馏温度,其梯度被缩放了
验证
本论文基于之前的一篇论文Model compression进一步泛化,其使用logits而不是分类概率进行蒸馏实现,通过最小化大模型logits和小模型logits之间的平方差进行训练。论文通过数学公式验证了这种蒸馏方式是本论文提出的知识蒸馏的一种特例
使用soft targets进行梯度计算,实现公式如下:
logits;logits;soft targets;
当蒸馏温度相对于logits高多个数量级时,
假定每个logits都是零均值分布,那么
也就是在高的蒸馏温度情况下,蒸馏分类概率等同于最小化
MNIST
论文首先在MNIST数据集上进行了实验
- 大模型:拥有两个隐藏层的神经网络,每个隐藏层拥有
1200个神经元,其测试集误差为67; - 小模型一:每层拥有
800个神经元,共两个隐藏层的神经网络,其测试集误差为146- 当使用大模型的输出概率作为
soft targets,蒸馏温度为20进行正则化训练后,其测试集误差个数为74
- 当使用大模型的输出概率作为
- 对于两个隐藏层的神经网络而言
- 如果隐藏层神经元个数大于
300,那么蒸馏温度>=8即可得到相似的结果; - 如果隐藏层神经元个数为
30个,那么蒸馏温度在2.5到4之间能够得到最好结果。
- 如果隐藏层神经元个数大于
论文另外实验了以下场景:
- 在蒸馏小模型过程中,忽略所有数字为
3的训练样本- 经过蒸馏训练后,小模型在测试集上的测试误差为
206,其中103个为数字为3的样本,而测试集中数字为3的样本共有1010个; - 通过研究发现,大部分错误识别的情况是因为第
3个维度的偏置太小了,增加3.5之后,小模型的测试误差达到109,其中仅有14个错误样本是数字3;
- 经过蒸馏训练后,小模型在测试集上的测试误差为
- 在蒸馏小模型过程中,仅使用数字为
7和8的样本进行训练- 小模型的测试误差率为
47.3%; - 当对第7和第8个维度的偏置减小
7.6之后,测试误差率下降到13.2%。
- 小模型的测试误差率为
JFT
对于巨多数据和类别标签的数据集,论文实验了使用一个通用模型+多个特定类别模型作为大模型集合,对小模型进行蒸馏训练。
论文使用的是JFT,Google内部的一个数据库,拥有1亿张图片和15000个类别。
论文对实验过程进行了详细说明,不过看完好感觉实现方式过于复杂,加上这篇文章属于知识蒸馏的初期作品,所以就不再深入学习了
正则化
论文通过实验证明了使用soft targets方式进行蒸馏训练能够帮助小模型避免过拟合。
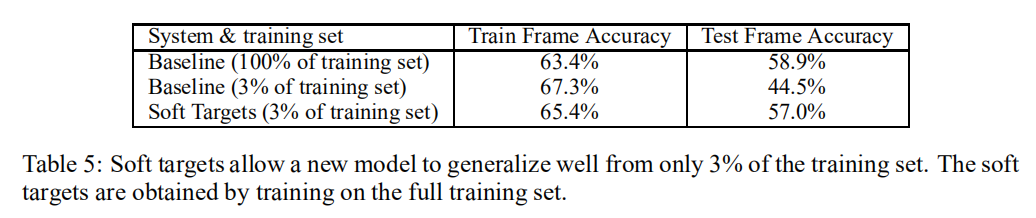
使用一个仅有85M的声音模型
- 不额外添加
soft targets进行训练,仅需3%的训练集数据就导致了模型过拟合,最终模型精度在44.5%; - 通过添加
soft targets进行蒸馏训练,可以使用全部的训练集数据,最终模型精度在57%。
小结
本文可以说是第一篇将知识蒸馏应用于深度学习的论文,通过大模型的蒸馏训练,可以帮助小模型学习到更多的特征。
Gitalk 加载中 ...