ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile
原文地址:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile
摘要
We introduce an extremely computation-efficient CNN architecture named ShuffleNet, which is designed specially for mobile devices with very limited computing power (e.g., 10-150 MFLOPs). The new architecture utilizes two new operations, pointwise group convolution and channel shuffle, to greatly reduce computation cost while maintaining accuracy. Experiments on ImageNet classification and MS COCO object detection demonstrate the superior performance of ShuffleNet over other structures, e.g. lower top-1 error (absolute 7.8%) than recent MobileNet [12] on ImageNet classification task, under the computation budget of 40 MFLOPs. On an ARM-based mobile device, ShuffleNet achieves ∼13× actual speedup over AlexNet while maintaining comparable accuracy
我们引入了一种计算效率极高的CNN架构,名为ShuffleNet,它是专门为计算能力非常有限的移动设备(例如10-150 MFLOPs)设计的。这个新的体系结构利用了两种新的操作,逐点组卷积和通道重排,在保持精度的同时大大降低了计算成本。在ImageNet分类和MS COCO目标检测上的实验表明ShuffleNet优于其他结构。例如在ImageNet分类任务上,与最近的MobileNet [12]相比,在40 MFLOPs的计算预算下具有更低的top-1误差率(7.8%)。在基于ARM的移动设备上,ShuffleNet比AlexNet实现了约13倍的实际加速,同时保持了相应的精度
章节内容
论文提出了另一种卷积分解方法,通过逐点分组卷积(pointwise group convolution)操作,避免了channel shuffle)操作,来帮助信息流实现跨通道的交互
分组卷积与通道重排
分组卷积
最开始出现在AlexNet,为的是在双GPU上运行,如下图所示
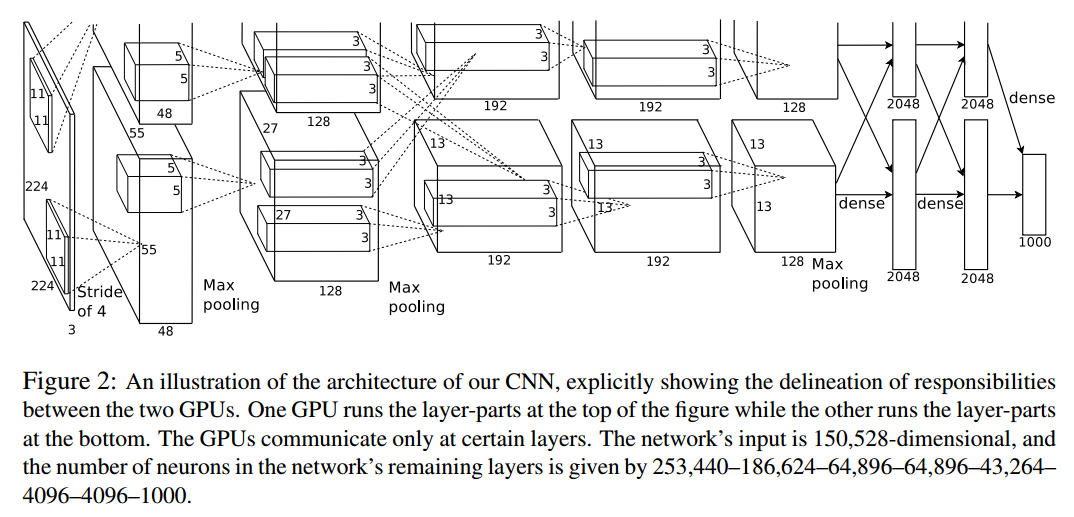
基于特征图的通道维度进行分组,使用不同的卷积核进行计算。假定输入特征图大小为
计算成本为
假定分为
计算成本为
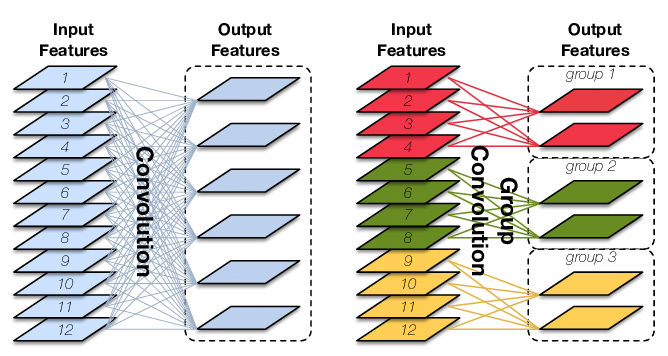
换句话说,分组数越大,压缩效率越高
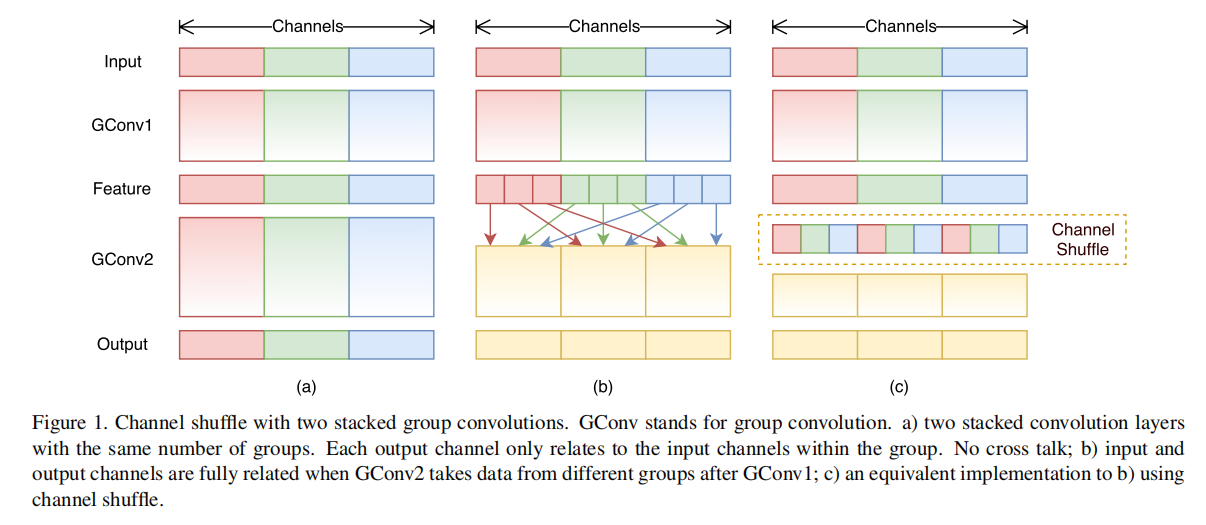
通道重排
堆叠分组卷积构建块,存在一个缺点,就是某个通道的输出仅来自一小部分输入通道。论文提出通道重排操作来解决这个问题
ShuffleNet Unit
论文提出了两个Shuffle Unit,分别作用于stride=1和stride=2的情况
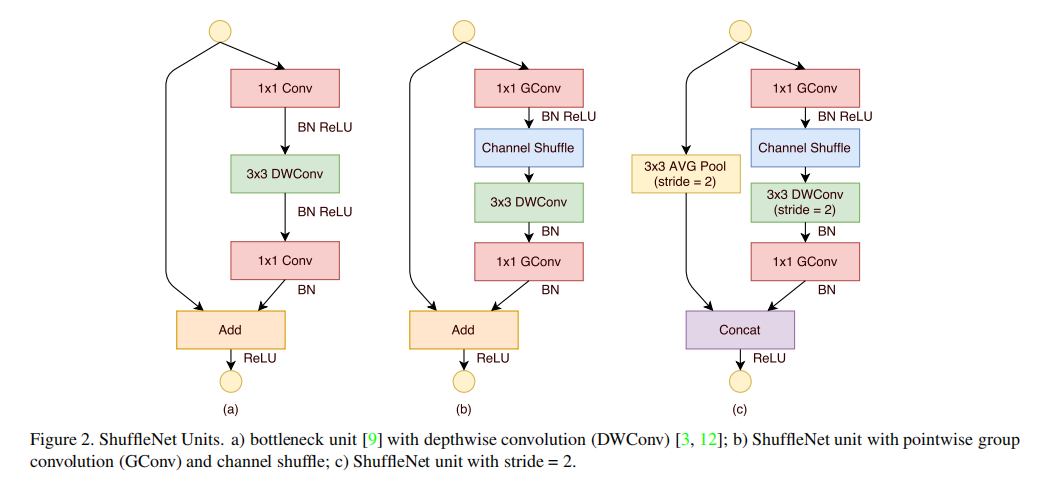
图a是一个原始版本的残差块,Shuffle Unit在此基础上进行了修改
Conv表示标准卷积DWConv表示逐通道可分离卷积GConv表示分组卷积
架构
每两个Unit堆叠成一个阶段,ShuffleNet共使用了3个阶段。其中,在每个阶段的第一个Unit使用stride=2
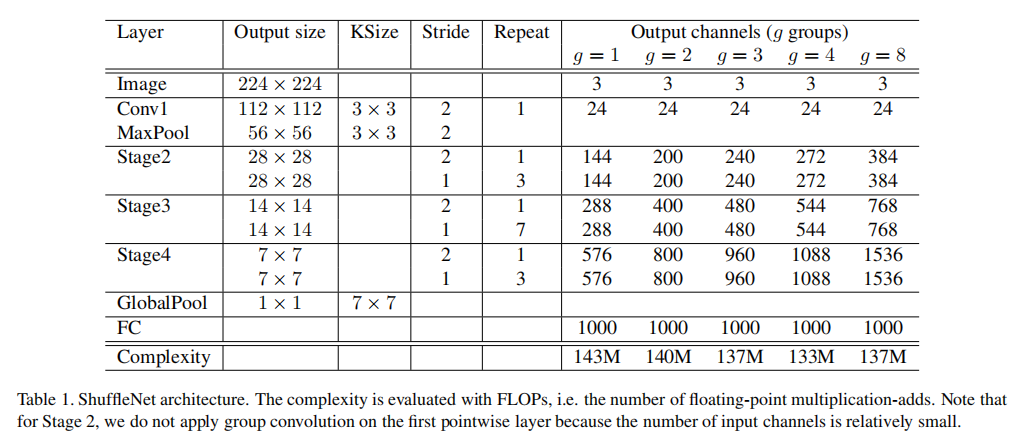
- 超参数
g控制分组卷积的连接稀疏性 - 每个阶段的
Unit保持参数一致(除了stride),下一个阶段的输出通道数翻倍 - 论文为了比较不同分组的性能,将计算成本控制在
140 MFlops左右,调整了不同g配置下各个阶段的通道数
实验
在ImageNet 2012分类数据集上评估ShuffleNet性能。使用ShuffleNet架构(上一节所示),使用s是一个超参数,表示缩放因子)表示缩放滤波器个数的倍数
训练原则
- 对于小网络,使用更少的正则化操作
比较不同数目滤波器
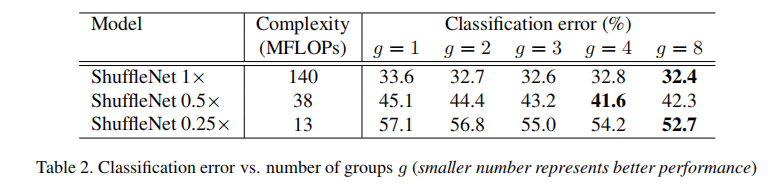
- 滤波器个数的减少减少了计算量,同时降低了模型性能
- 分组数的增多提高了模型性能
比较分组个数/通道重排
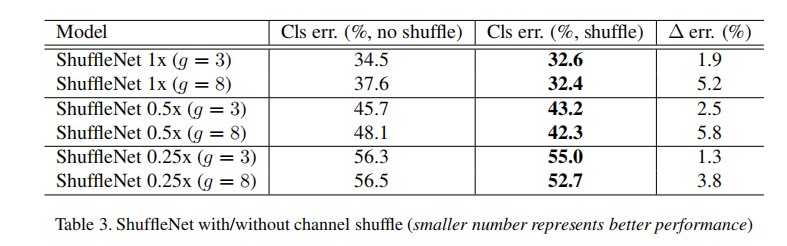
- 通道重排能够有效实现信息跨通道交互
- 分组数的增多提高了模型性能
小结
在给定计算约束的情况下,较大的组数会导致更多的输出通道(从而产生更多的卷积滤波器),这有助于编码更多的信息,尽管由于相应的输入通道有限,它也可能导致单个卷积滤波器的性能下降
未找到相关的 Issues 进行评论
请联系 @zjykzj 初始化创建