Searching for MobileNetV3
原文地址:Searching for MobileNetV3
摘要
We present the next generation of MobileNets based on a combination of complementary search techniques as well as a novel architecture design. MobileNetV3 is tuned to mobile phone CPUs through a combination of hardware-aware network architecture search (NAS) complemented by the NetAdapt algorithm and then subsequently improved through novel architecture advances. This paper starts the exploration of how automated search algorithms and network design can work together to harness complementary approaches improving the overall state of the art. Through this process we create two new MobileNet models for release: MobileNetV3-Large and MobileNetV3-Small which are targeted for high and low resource use cases. These models are then adapted and applied to the tasks of object detection and semantic segmentation. For the task of semantic segmentation (or any dense pixel prediction), we propose a new efficient segmentation decoder Lite Reduced Atrous Spatial Pyramid Pooling (LR-ASPP). We achieve new state of the art results for mobile classification, detection and segmentation. MobileNetV3-Large is 3.2% more accurate on ImageNet classification while reducing latency by 20% compared to MobileNetV2. MobileNetV3-Small is 6.6% more accurate compared to a MobileNetV2 model with comparable latency. MobileNetV3-Large detection is over 25% faster at roughly the same accuracy as MobileNetV2 on COCO detection. MobileNetV3-Large LR-ASPP is 34% faster than MobileNetV2 R-ASPP at similar accuracy for Cityscapes segmentation.
我们提出了基于互补搜索技术和新的架构设计实现的下一代MobileNet。MobileNetV3为手机CPU设计,采用了NetAdapt算法实现的硬件感知网络架构搜索(NAS)组合,然后通过新的架构进行改进。本文开始探索自动搜索算法和网络设计如何协同工作,利用互补方法来提高整体水平。通过这一过程,我们发布了两个新的MobileNet模型:MobileNetV3-Large和MobileNetV3-Small,分别针对高和低资源用例。这些模型随后被修改并应用于目标检测和语义分割任务。对于语义分割(或任何密集像素预测)任务,我们提出了一种新的高效分割解码器 - Lite Reduced Atrous Spatial Pyramid Pooling (LR-ASPP)。我们在移动分类、检测和分割方面取得了最好的结果。MobileNetV3-Large与MobileNetV2相比,在ImageNet分类数据集的准确性提高了3.2%,同时延迟降低了20%。与具有可比延迟的MobileNetV2模型相比,MobileNetV3-Small的精确度提高了6.6%。在COCO检测任务上,与MobileNetV2存在相近精度的情况下,MobileNetV3-Large的检测速度提高了25%以上。与MobileNetV2 R-ASPP在城市景观分割任务中得到相近精度的情况下,MobileNetV3-Large LR-ASPP快34%
章节内容
- 回顾了MobileNet系列的进步,包括MobileNetV1、MobileNetV2、MnasNet
- 介绍了MobileNetV3使用的自动神经架构搜索技术,结合Platform-Aware NAS以及NetAdapt算法
- 介绍了MobileNetV3人工改进的部分,包括重新设计耗时层、选择新的激活函数以及SE模块的嵌入
- 介绍了MobileNetV3-Large以及MobileNetV3-Small两个模型
- 通过实验和烧蚀研究证明MobileNetV3以及新增加模块的提升
下面学习论文中人工改进部分
MobileNetV3-Large/Small
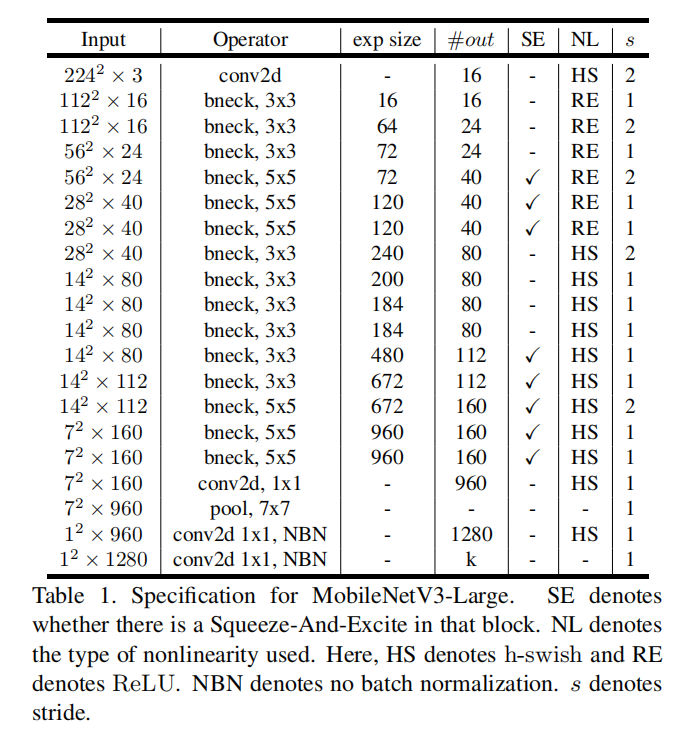
论文设计了MobileNetV3-Large和MobileNetV3-Small两个模型架构,分别针对高资源和低资源用例
对于MobileNetV3-Large,直接以MnasNet为基底,然后利用NetAdapt算法以及其它优化技术
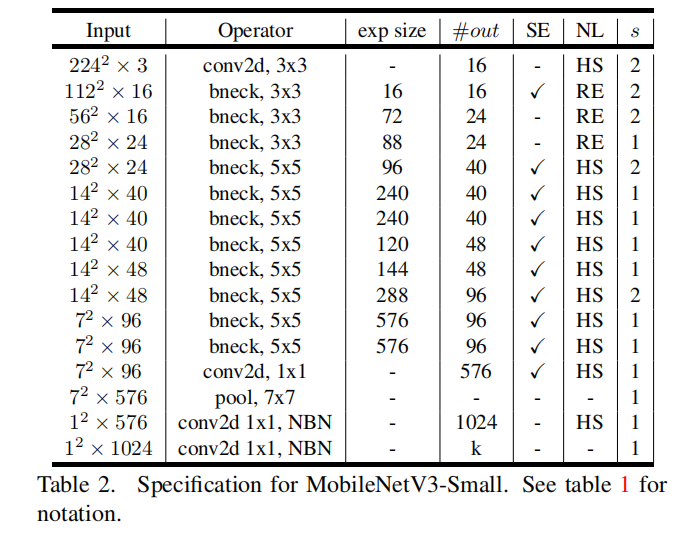
对于MobileNetV3-Small,重新设计了Platform-Aware NAS的reward函数,从头开始检索,再利用NetAdapt算法以及其他优化技术
Squeeze-and-Excitation单元hard swishReLU
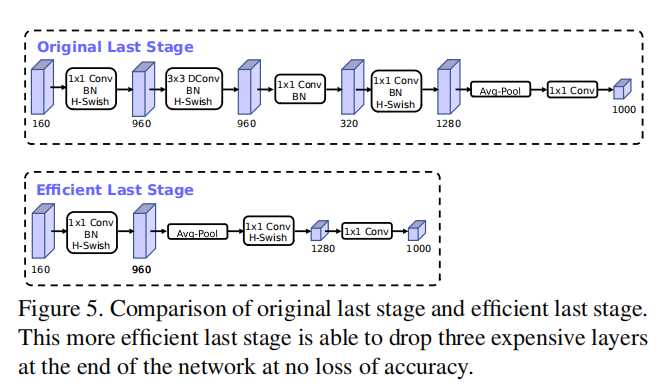
重新设计耗时层
论文对最开始的
- 对于最开始的
hard swish非线性能够减少滤波器的使用,从32 -> 16 - 对于最后的反向瓶颈结构,修改如下:
非线性
论文对swish非线性函数进行了改进
- 改进一:
Sigmoid函数在移动设备上的计算耗时,所以使用了替代版本,称改进后的swish函数为hard swish
- 改进二:论文发现
swish函数在更多的网络层中能够发挥更好的优势(具体没说),所以在MobileNetV3中,结合使用了h-swish和ReLU
Gitalk 加载中 ...