MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
原文地址:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
摘要
We present a class of efficient models called MobileNets for mobile and embedded vision applications. MobileNets are based on a streamlined architecture that uses depthwise separable convolutions to build light weight deep neural networks. We introduce two simple global hyperparameters that efficiently trade off between latency and accuracy. These hyper-parameters allow the model builder to choose the right sized model for their application based on the constraints of the problem. We present extensive experiments on resource and accuracy tradeoffs and show strong performance compared to other popular models on ImageNet classification. We then demonstrate the effectiveness of MobileNets across a wide range of applications and use cases including object detection, finegrain classification, face attributes and large scale geo-localization.
我们提出了一类有效的移动和嵌入式视觉应用模型MobileNets。MobileNets基于一个流线型的架构,它使用可分离的反卷积来构建轻量级的深层神经网络。我们引入了两个简单的全局超参数,有效地权衡了延迟和准确性。这些超参数允许模型生成器根据问题的约束为其应用选择合适大小的模型。我们在资源和准确度的权衡方面进行了大量的实验,并且在ImageNet分类方面与其他流行的模型相比表现出了很强的性能。然后,我们展示了MobileNets在广泛的应用和用例中的有效性,包括目标检测、细粒度分类、人脸属性和大规模地理定位
章节内容
论文首先介绍了逐通道可分离卷积(或者称为深度可分离卷积,depthwise separable convolution)的实现;然后介绍了整体的网络架构以及训练流程,同时介绍了两个超参数(宽度乘法器(width multiplier)和分辨率乘法器(resolution multiplier))以进一步缩小模型大小;最后通过大量实验证明MobileNet的有效性及其可扩展性
逐通道可分离卷积
逐通道可分离卷积是MobileNet实现的核心,通过因子分解大幅的压缩卷积参数
标准卷积
假定输入特征图大小为
解释:每次卷积核计算
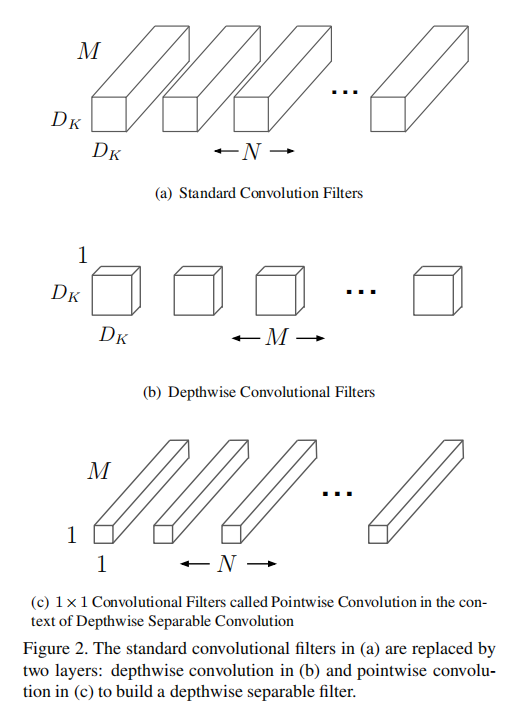
标准卷积组合了两步操作:首先对输入数据和卷积核进行逐点乘积,然后求和所有点的计算结果。深度可分离卷积将滤波和组合操作分离为两步执行,分别是深度卷积(或者称为逐通道卷积,depthwise convolution)和逐点卷积(pointwise convolution)
逐通道卷积
逐通道卷积对输入特征图的每个通道执行一个单独的滤波器操作,所以其滤波器大小为
解释:每次卷积核计算
逐点卷积
经过深度卷积操作后,得到了
解释:每次卷积核计算
小结
将标准卷积分解成逐通道可分离卷积,其参数数目得到了极大的压缩。计算如下:
MobileNet使用8~9倍的参数压缩

另外,对逐通道卷积层和逐点卷积层都应用了激活函数和批量归一化,增加了非线性特征
架构和训练
MobileNet架构
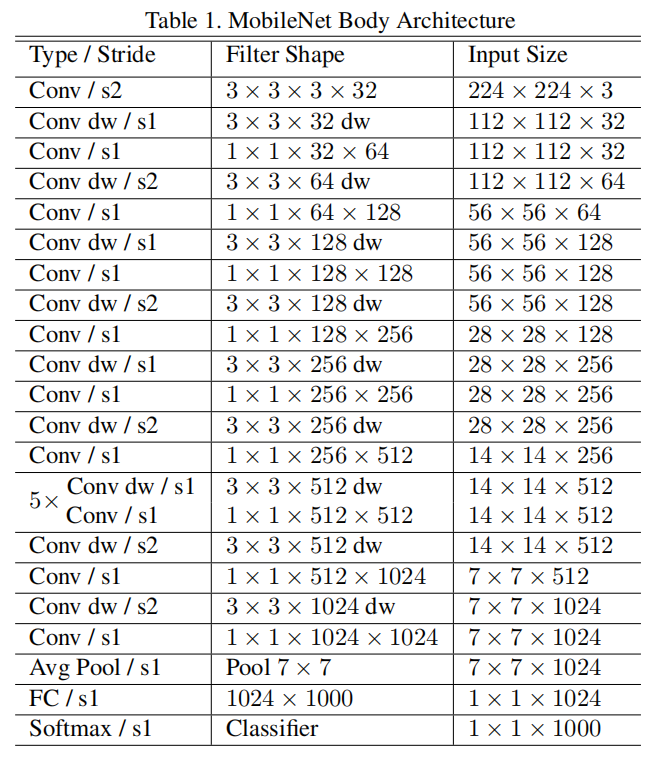
除了第一层使用标准卷积外,其余卷积层都使用了深度可分离卷积操作。将深度卷积和逐点卷积分开统计,整个MobileNet共有28层
训练技巧
- 不需要过多的正则化和数据扩充,因为小网络不容易过拟合
- 对逐通道卷积执行很少或没有权重衰减(
L2正则化)很重要,因为它们的参数很少,不容易过拟合
压缩因子
论文提出了两个超参数:宽度乘法器和分辨率乘法器,用来构造更小和计算成本更低的模型,不仅仅适用于MobileNet,理论上可以作用于任意一个模型
宽度乘法器
超参数
MobileNet,当
分辨率乘法器
超参数
小结
同时使用宽度乘法器和分辨率乘法器,其计算成本为
当输入/输出数据的空间分辨率
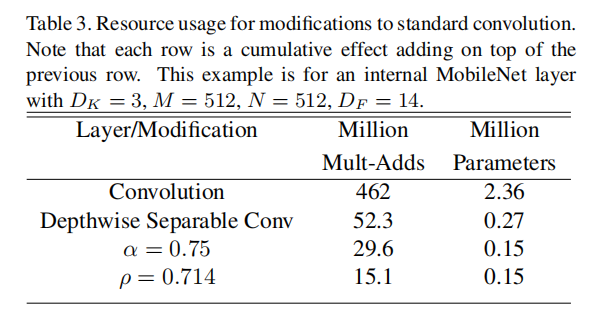
原始卷积层拥有2.36M个参数,MAC计算量为462。使用逐通道可分离卷积层,同时设置0.15M个参数,MAC计算量为15.1。参数其压缩了15.7倍,MAC计算量压缩了30.6倍
小结
论文不仅提出了一个新的轻量级模型架构MobileNet,还提出了两种压缩方法 - 宽度乘法器和分辨率乘法器。在具体使用过程中,先使用原始MobileNet进行训练,然后逐步测试不同
MobileNet大量使用了
未找到相关的 Issues 进行评论
请联系 @zjykzj 初始化创建