Aggregated Residual Transformations for Deep Neural Networks
原文地址:Aggregated Residual Transformations for Deep Neural Networks
摘要
We present a simple, highly modularized network architecture for image classification. Our network is constructed by repeating a building block that aggregates a set of transformations with the same topology. Our simple design results in a homogeneous, multi-branch architecture that has only a few hyper-parameters to set. This strategy exposes a new dimension, which we call “cardinality” (the size of the set of transformations), as an essential factor in addition to the dimensions of depth and width. On the ImageNet-1K dataset, we empirically show that even under the restricted condition of maintaining complexity, increasing cardinality is able to improve classification accuracy. Moreover, increasing cardinality is more effective than going deeper or wider when we increase the capacity. Our models, named ResNeXt, are the foundations of our entry to the ILSVRC 2016 classification task in which we secured 2nd place. We further investigate ResNeXt on an ImageNet-5K set and the COCO detection set, also showing better results than its ResNet counterpart. The code and models are publicly available online
.
我们提出了一种简单的、高度模块化的图像分类网络架构。通过重复一个构建块来构建整个网络,该构建块聚合了一组具有相同拓扑结构的转换。我们的简单设计实现了一个同质的,多分支的架构,只有几个超参数设置。这个策略展示了一个新的维度,我们称之为“基数”(转换集的大小),作为深度和宽度维度之外的一个重要因素。在ImageNet-1K数据集上,我们的实验表明,即使在保持复杂度的限制条件下,增加基数也能提高分类精度。此外,当网络增加容量时,增加基数比提高深度或提高宽度更有效。我们的模型名为ResNeXt,是我们参与ILSVRC 2016分类任务的基础,在该任务中我们获得了第二名。我们进一步研究了ImageNet-5K集和COCO检测集上的ResNeXt,也显示了比ResNet更好的结果。这些代码和模型在网上是公开的
https://github.com/facebookresearch/ResNeXt
模板
对于VGGNet/ResNet等网络而言,其设计了一个独特的模板块,然后重复堆叠它形成了整个网络。ResNetXt遵循了这一思想,并且遵守两个规则:
- 对于保持相同(空间尺寸和维度)特征图输出的块,使用一样的滤波器个数/大小
- 每次特征图下采样(空间尺寸除以
2)后,输出特征图的宽度(通道数)乘以2
splitting, transforming, and aggregating
论文通过神经元的计算解析了分离、转换、聚合思想。神经元执行点积(加权求和)操作,计算公式如下:
其中
- 分离:将向量
- 转换:对低维嵌入进行转换,对于神经元而言,就是加权缩放:
- 聚合:聚合所有的转换结果:
将单个神经元操作泛化到模块操作,计算公式如下:
cardinality
构建块
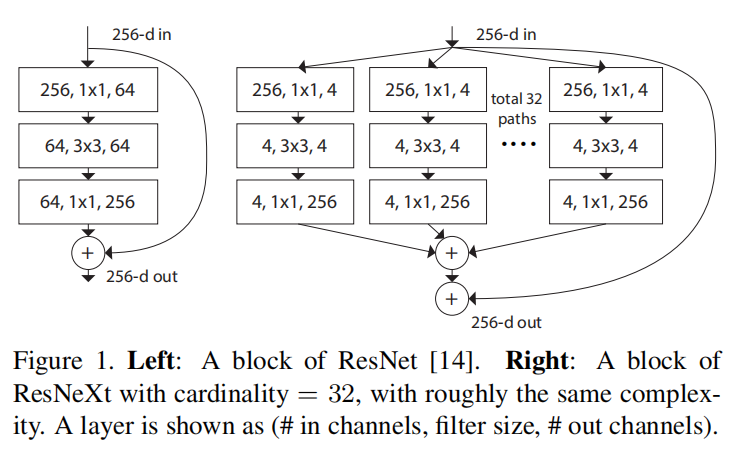
ResNetXt的残差构建块参考了Inception模块,在残差连接的基础上增加了多分支操作
- 对于
Basic Block
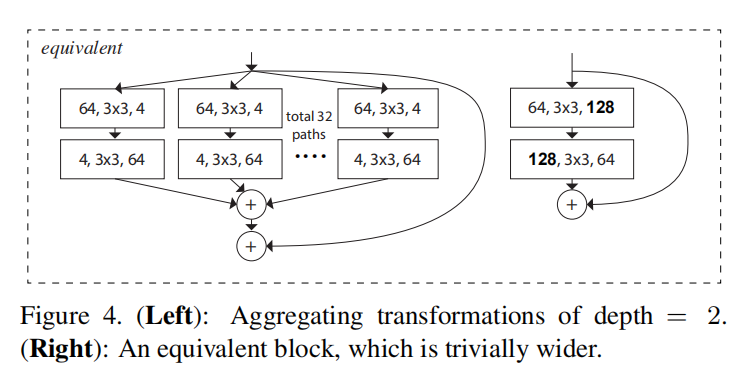
- 对于
Bottleneck Block
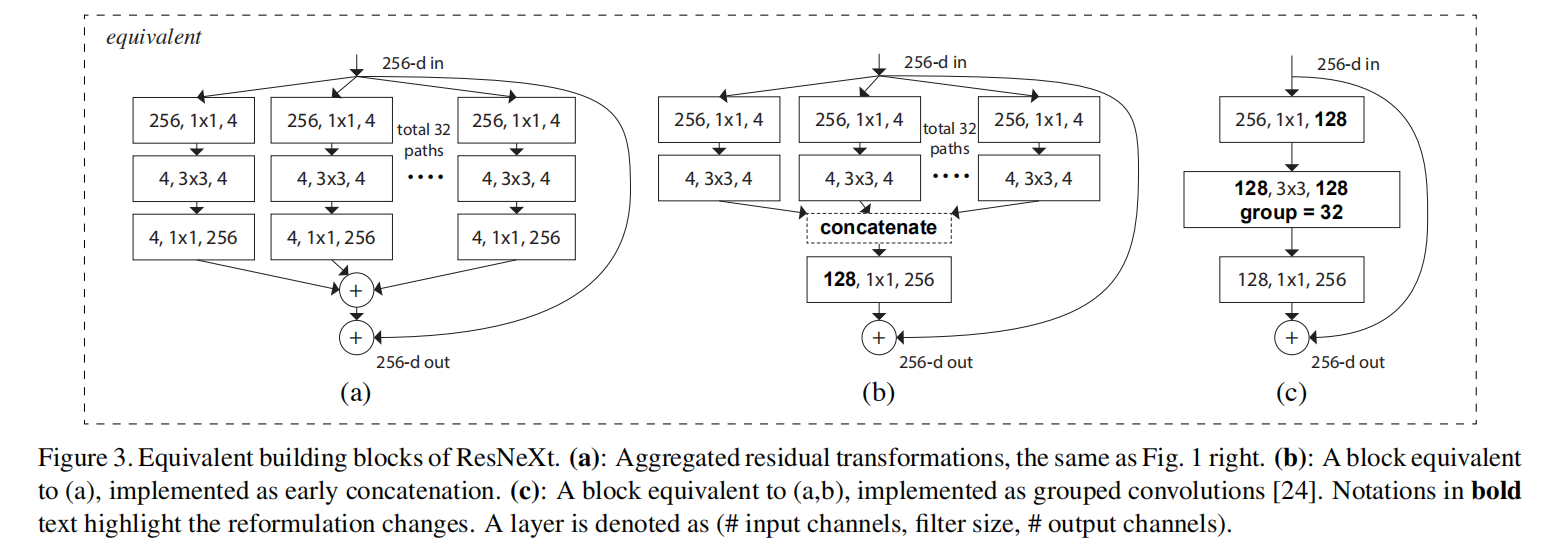
论文设计了多种构建块的解析方式(如下图所示),发现采用分组卷积(图3(c))能够实现更快的计算
架构
基数(cardinality)和宽度(滤波器个数)相互作用,共同影响了模块复杂度。论文计算相近复杂度的情况下,基数、宽度以及具体实现时的分组数的选择

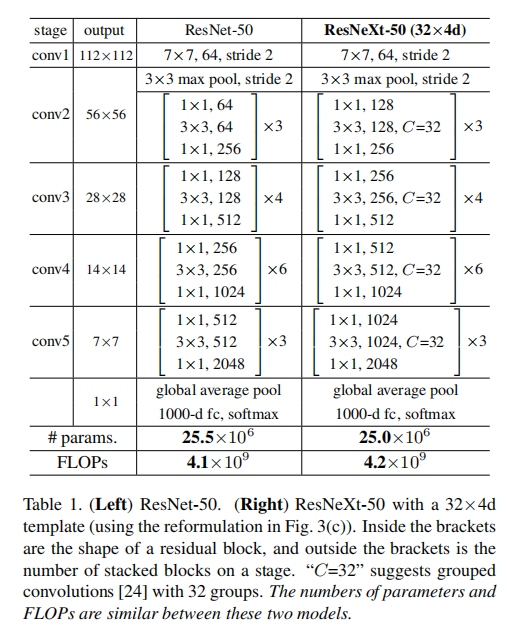
论文给出了ResNetXt-50(32x4d)的参数,和ResNet-50拥有相近的复杂度
实验
Cardinality vs. Width
论文比较了相同复杂度的前提下,如何搭配基数和模块宽度
- 下图显示了训练曲线
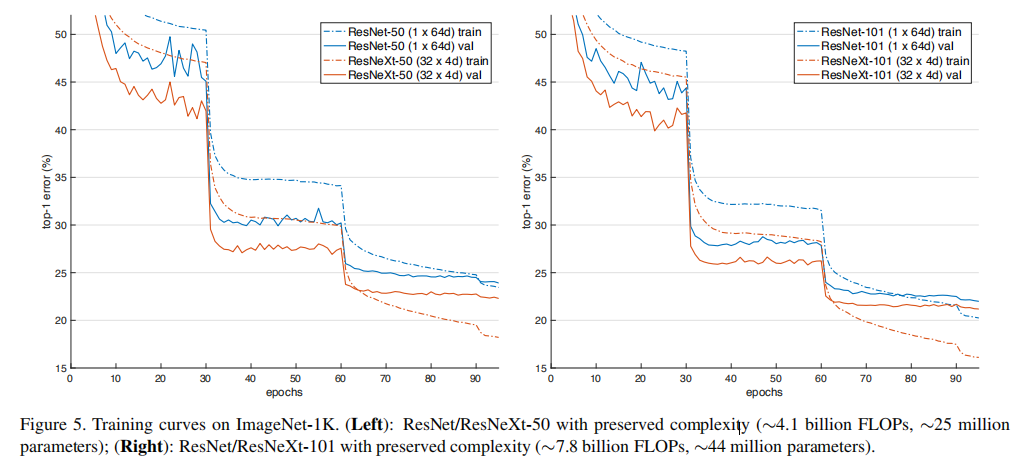
- 下表显示了训练结果
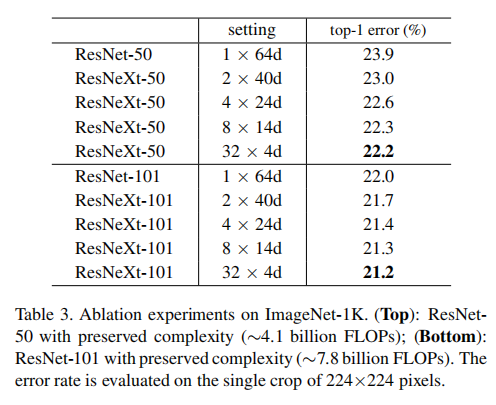
从结果看,使用32x4d的组合效果最优
Increasing Cardinality vs. Deeper/Wider.
论文比较了基数维度和模型深度维度以及模块宽度维度,如下表所示
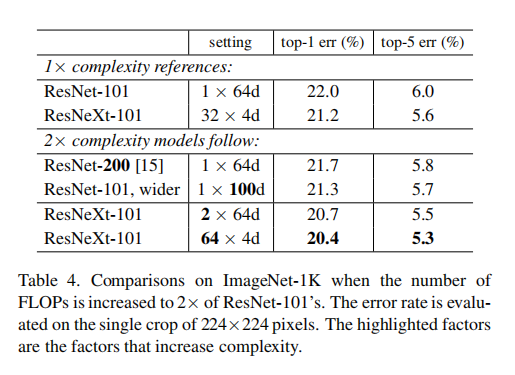
从测试结果可知,增加基数
Residual connections.
论文同时测试了残差连接的作用,如下表所示

实验结果证明了残差连接确实能够提高模型表达能力
小结
ResNetXt在ResNet的基础上,结合了Inception模块的多分支(split-transform-merge)思想以及VGGNet的模板模块(stacking building blocks of the same shape)思想,在残差块内部执行多分支计算,并通过实验证明了在给定复杂度的条件下,增加基数(cardinality,就是分支个数)比增加网络层数(go deeper)或者提高模块宽度(Wide ResNet,提高每层维数)更有效
未找到相关的 Issues 进行评论
请联系 @zjykzj 初始化创建