Squeeze-and-Excitation Networks
原文地址:Squeeze-and-Excitation Networks
摘要
The central building block of convolutional neural networks (CNNs) is the convolution operator, which enables networks to construct informative features by fusing both spatial and channel-wise information within local receptive fields at each layer. A broad range of prior research has investigated the spatial component of this relationship, seeking to strengthen the representational power of a CNN by enhancing the quality of spatial encodings throughout its feature hierarchy. In this work, we focus instead on the channel relationship and propose a novel architectural unit, which we term the “Squeeze-and-Excitation” (SE) block, that adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels. We show that these blocks can be stacked together to form SENet architectures that generalise extremely effectively across different datasets. We further demonstrate that SE blocks bring significant improvements in performance for existing state-of-the-art CNNs at slight additional computational cost. Squeeze-and-Excitation Networks formed the foundation of our ILSVRC 2017 classification submission which won first place and reduced the top-5 error to 2.251%, surpassing the winning entry of 2016 by a relative improvement of ∼25%. Models and code are available at https://github.com/hujie-frank/SENet.
卷积神经网络的核心构件是卷积算子,它使网络能够通过在每层的局部感受野内融合空间和通道信息来构造信息特征。大量的前期研究已经调查了这种关系的空间成分,试图通过提高整个特征层次的空间编码质量来增强CNN的表达能力。在这项工作中,我们将重点放在通道关系上,并提出了一个新的架构单元,我们称之为“挤压和激励”(SE)模块,它通过显式建模通道之间的相互依赖性,自适应地重校准逐通道的特征响应。我们表明,这些块堆叠在一起得到的SENet架构能够非常有效的泛化到不同数据集。我们进一步证明,在增加少量额外计算成本的情况下,SE模块能够给最先进CNN网络带来了显著的性能改进。挤压和激励网络构成了我们的ILSVRC 2017分类提交的基础,它赢得了第一名,将top-5误差率降低到2.251%,超过了2016年的获胜者(相对提高了25%)。模型和代码公布在 https://github.com/hujie-frank/SENet
章节内容
- 首先介绍挤压激励单元的实现及数学推导
- 其次比较了嵌入
SE模块的模型和原始模型之间的大小和计算复杂度 - 接着通过实验证明了
SE模块在不同任务(目标识别、检测等)、不同架构(Inception/ResNet等)、不同深度、不同数据集中的泛化能力 - 通过烧蚀研究分析了
SE模块的组成以及作用 - 通过实验证明了
Squeeze操作和Excitation操作的不可或缺
SE模块
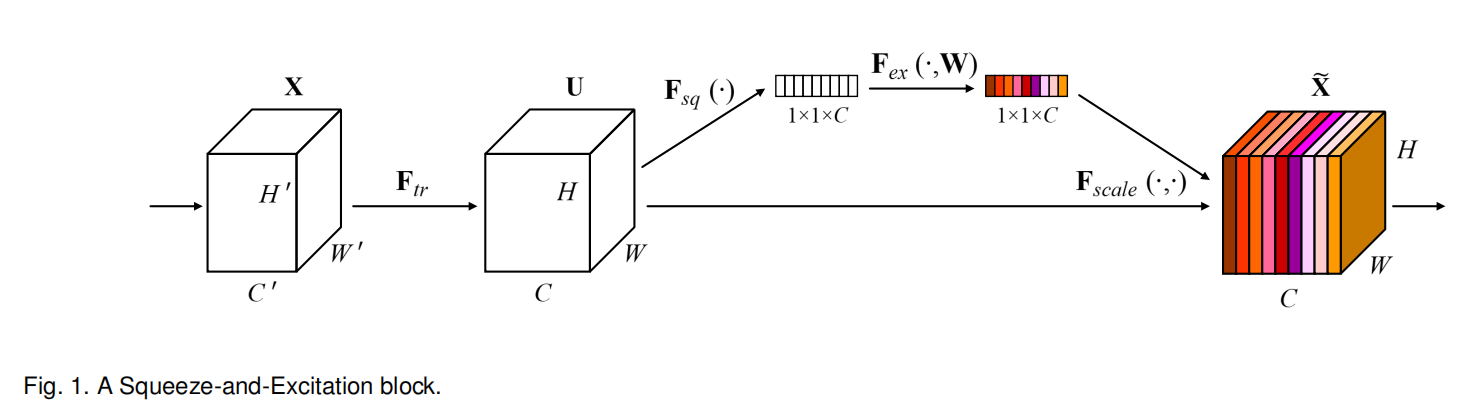
Sequeeze-and-Excitation block的实现如上图所示。
其中,
在完成Sequeeze-and-Excitation操作
Squeeze单元
对输出特征图执行逐通道的全局平均池化,以融合通道信息
Excitation单元
利用全局通道信息对每个通道的特征响应进行自适应重校准(这个词用的挺酷炫的,就是读起来挺拗口的)
在激励操作中,先对输入特征执行维度衰减,所以
Scale
从Excitation单元得到自适应重校准后的全局信息后,对输出特征
小结
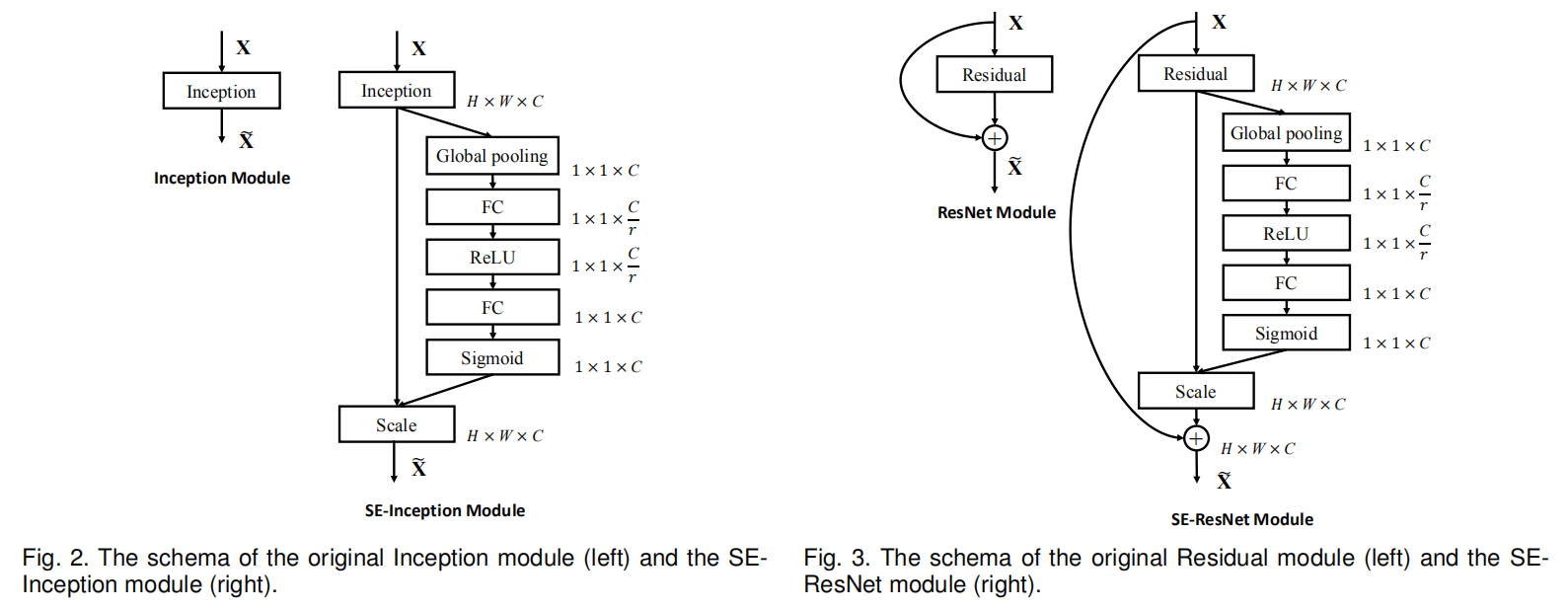
SE模块可以适用于任意的卷积操作之后,论文还给出了SE-Inception和SE-ResNet模块的实现
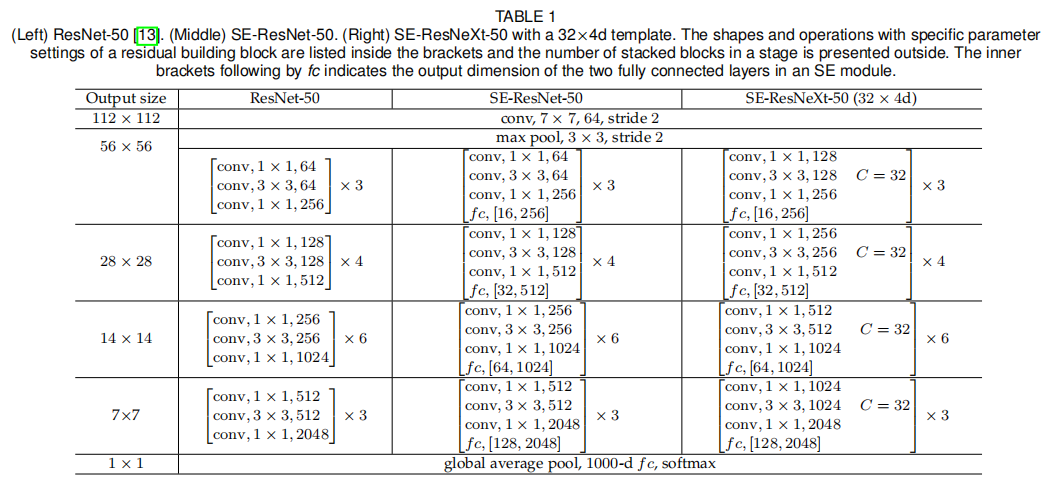
SE-ResNetXt-50
烧蚀研究
衰减率
论文比较了不同衰减率下的模型大小以及准确率,如下图所示
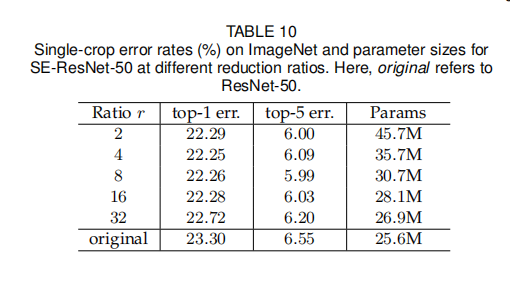
从结果可知,增加的复杂度不会单调地改善性能,而较小的衰减率会显著地增加模型的参数大小,选择
Squeeze算子
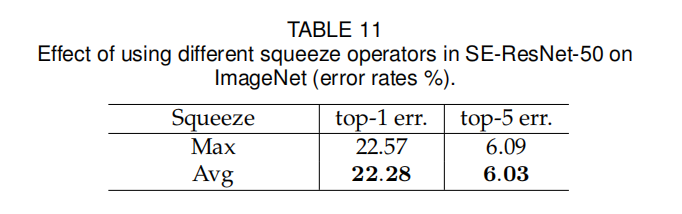
论文比较了在Squeeze部分使用全局平均池化或者全局最大池化操作的性能
Excitation算子
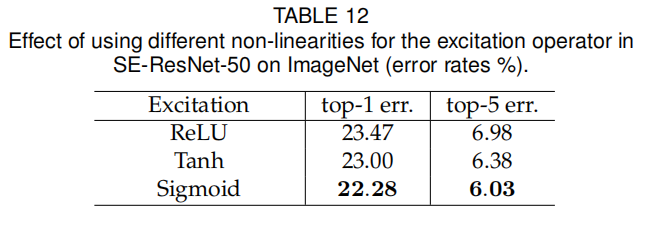
在Excitation实现中,后一个全连接层使用了Sigmoid激活函数,论文还比较了ReLU和tanh
不同的阶段
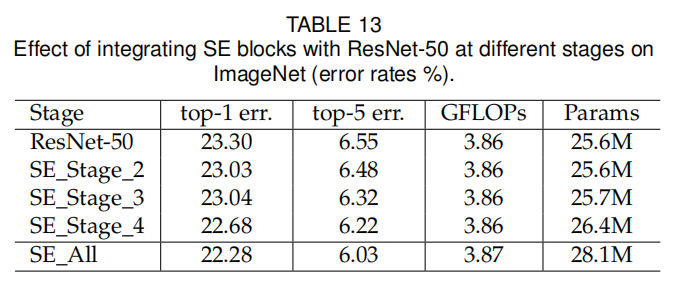
论文探索了在ResNet的不同阶段嵌入SE模块的性能变化,发现每个阶段的嵌入都能提升模型性能,并且组合在一起能够进一步提升
嵌入策略
论文设计了多种嵌入SE模块的方法。如下图所示:
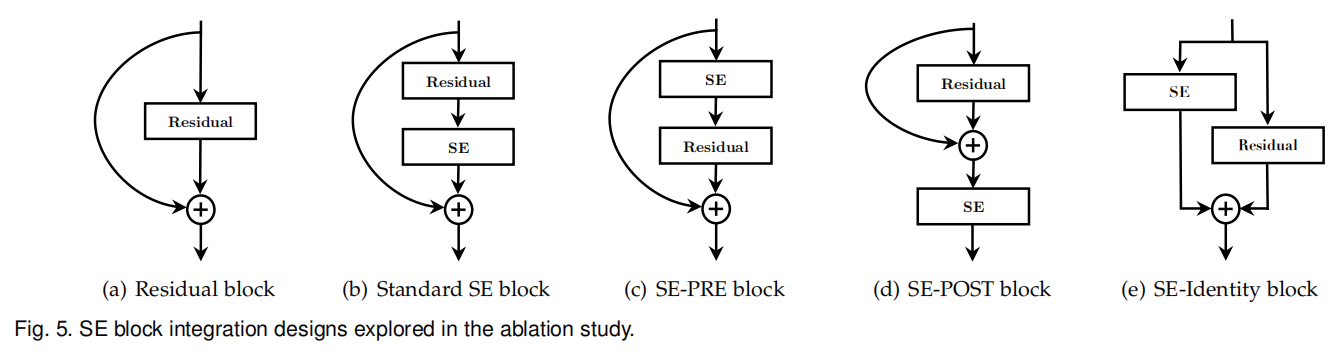
SE-PRE:在残差单元之前嵌入SE-POST:在一致性映射(求和+ReLU)之后嵌入SE-Identity:SE单元嵌入到一致性连接分支,并行于残差单元
其实验结果如下表所示:
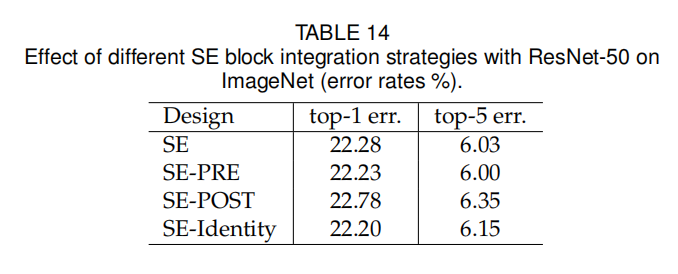
该实验表明,如果在分支聚合之前应用,由SE单元产生的性能改进对于它们的位置是相当稳健的
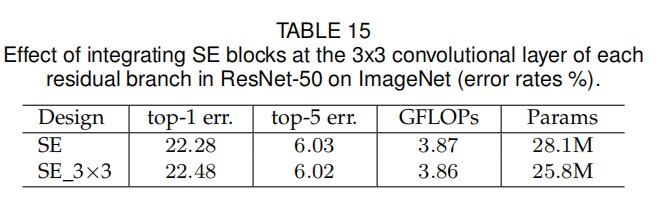
论文同时还测试了将SE单元直接嵌入到残差单元的SE单元的参数也能够相应减少。其实现结果如下:
小结
论文提出了一个新的架构单元 - Squeeze-And-Excitation Block(挤压激励块),通过融合逐通道的卷积特征来学习全局信息,以提高模型的表达能力。将SE模块嵌入到现有的网络模型中,在增加少量计算复杂度的同时能够有效的提升网络性能
未找到相关的 Issues 进行评论
请联系 @zjykzj 初始化创建