Destruction and Construction Learning for Fine-grained Image Recognition
原文地址:Destruction and Construction Learning for Fine-grained Image Recognition
官方实现:JDAI-CV/DCL
复现地址:ZJCV/DCL
摘要
Delicate feature representation about object parts plays a critical role in fine-grained recognition. For example, experts can even distinguish fine-grained objects relying only on object parts according to professional knowledge. In this paper, we propose a novel "Destruction and Construction Learning" (DCL) method to enhance the difficulty of fine-grained recognition and exercise the classification model to acquire expert knowledge. Besides the standard classification backbone network, another "destruction and construction" stream is introduced to carefully "destruct" and then "reconstruct" the input image, for learning discriminative regions and features. More specifically, for "destruction", we first partition the input image into local regions and then shuffle them by a Region Confusion Mechanism (RCM). To correctly recognize these destructed images, the classification network has to pay more attention to discriminative regions for spotting the differences. To compensate the noises introduced by RCM, an adversarial loss, which distinguishes original images from destructed ones, is applied to reject noisy patterns introduced by RCM. For "construction", a region alignment network, which tries to restore the original spatial layout of local regions, is followed to model the semantic correlation among local regions. By jointly training with parameter sharing, our proposed DCL injects more discriminative local details to the classification network. Experimental results show that our proposed framework achieves state-of-the-art performance on three standard benchmarks. Moreover, our proposed method does not need any external knowledge during training, and there is no computation overhead at inference time except the standard classification network feed-forwarding. Source code: https://github.com/JDAI-CV/DCL.
目标某些部分的精细特征表示在细粒度识别中起着关键作用。例如,专家可以根据专业知识,仅依靠目标某些区域来区分细粒度对象。本文提出了一种新的“解构和构造学习(DCL)”方法来提高细粒度识别能力,通过训练分类模型来获取专家知识。除了标准的分类主干网络以外,引入另一个“解构和构造”流来仔细地“破坏”然后“重建”输入图像,用于学习有判别力的区域和特征。更具体地说,对于“破坏”,我们首先将输入图像划分为局部区域,然后通过区域混淆机制(RCM)对它们进行洗牌。为了正确地识别这些被破坏的图像,分类网络必须更多地关注于发现有判别力区域之间的差异性。为了补偿RCM引入的噪声,采用了一种将原始图像与破坏图像区分开来的对抗损失来抑制RCM引入的噪声模式。对于“构建”,创建了一个区域对齐网络,通过恢复局部区域的的原始空间布局来建模局部区域之间的语义相关性。通过联合训练和参数共享,我们提出的DCL为分类网络注入了更多有判别力的局部细节。实验结果表明,我们提出的框架在三个标准基准上取得了最先进的性能。此外,我们提出的方法在训练过程中不需要任何外部知识,并且除了标准的分类网络前馈之外,在推理时没有计算开销。源代码:https://github.com/JDAI-CV/DCL.
引言
当前的细粒度图像分类算法大体可分为两类:
- 直接从图像中学习到更好的视觉特征:最常使用的分类网络,直接将图像输入到分类网络,通过更复杂的网络设计来提高特征提取能力
- 基于部件/注意力的算法(
part/attention based methods):- 基于有判别力区域的细粒度分类:首先定位图像中有识别能力的目标区域,然后基于这些区域进行分类;
- 优点:结合检测算法,当前实现了最好的识别效果;
- 缺点:前期需要对图像中目标或者判别力区域进行标注。
- 基于注意力机制的细粒度分类:通过无监督的注意力机制自动定位有判别力区域,然后基于这些区域进行分类;
- 优点:前期不需要额外标注工作;
- 缺点:网络需要额外添加注意力模块,其无监督定位的方式效果上不如检测算法。
- 基于有判别力区域的细粒度分类:首先定位图像中有识别能力的目标区域,然后基于这些区域进行分类;
其中,基于部件/注意力的算法实现流程如下图所示:
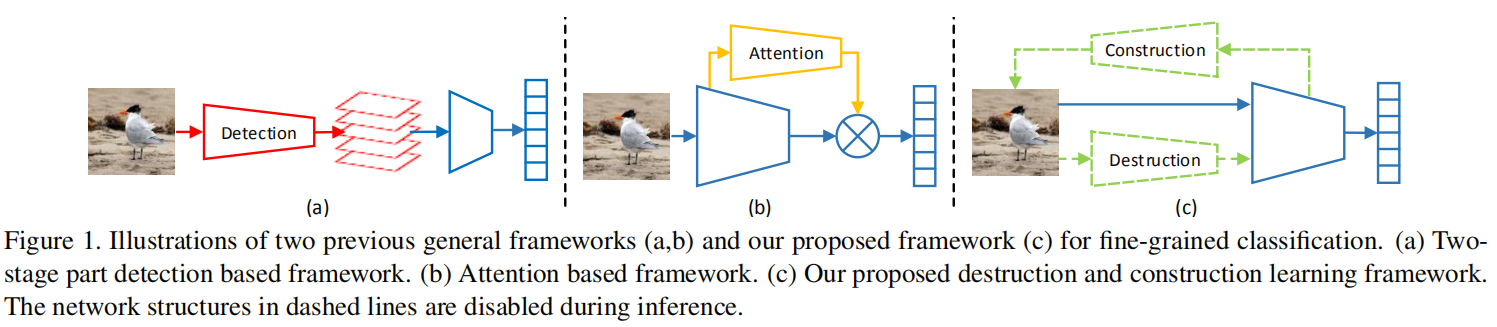
论文提出的DCL是区别于上述实现,如上图(c)所示。在训练过程中,除了正常的分类网络推理之外,论文还添加了一个解构模块和一个构造模块;在推理过程中,不需要额外的计算模块,这样就不会产生额外的计算开销。
对于解构模块,论文提出了区域融合机制(Region Confusion Mechanism, RCM),通过分块打乱输入图像(分块:保持局部细节;打乱:舍弃全局结构),强迫分类网络学习有判别力区域的信息;同时为了消除RCM带来的噪声影响,添加了一个对抗损失来最小化原始图像和打乱图像之间的噪声干扰。
对于构造模块,论文提出一个区域对齐网络( region alignment network),通过建模区域之间的语义相关性来恢复原始区域布局,这种方式可以促使分类网络进一步理解每个区域的语义。
注意:the devil is in the details.
DCL
Destruction and Construction Learning (DCL)整体框架可分为4部分实现,如下图所示:
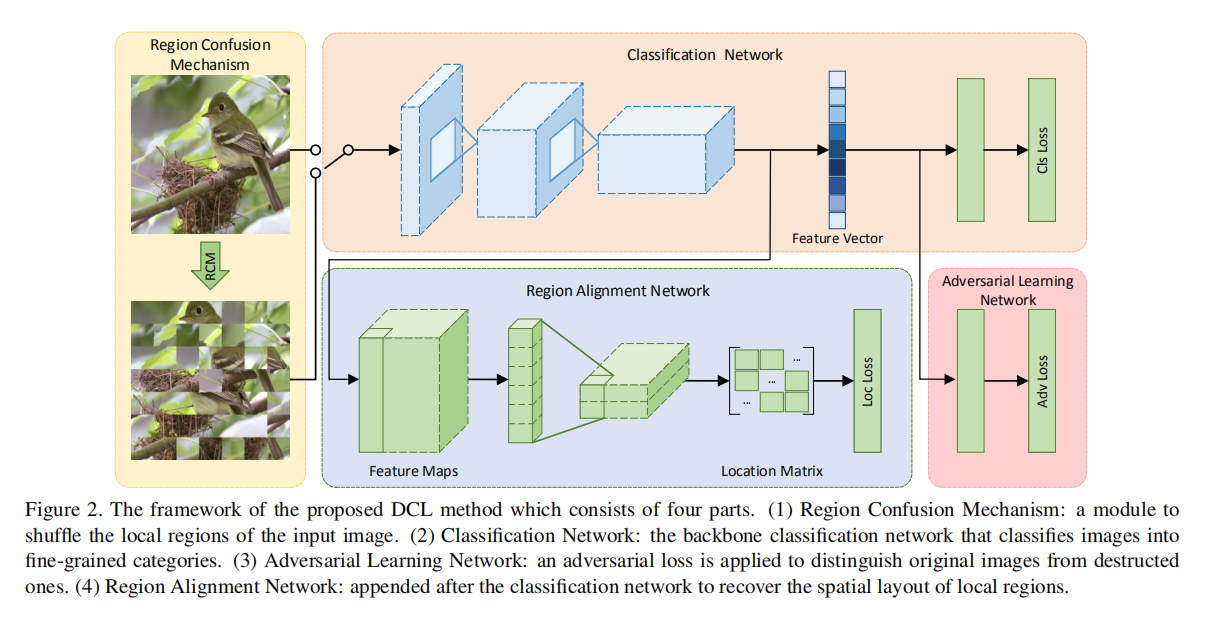
- 区域融合机制(
Region Confusion Mechanism, RCM)实现; - 分类网络(
Classification Network)训练; - 对抗学习网络(
Adversarial Learning Network)训练; - 区域对齐网络(
Region Alignment Network)训练;
其中第一和第三部分属于解构学习(destruction learning),第四部分属于重构学习(construction learning)
Destruction Learning
解构学习分为两部分:
- 区域融合机制:将图像分块后打乱,保持局部细节的同时打乱全局结构,迫使网络训练过程中更加关注于有判别力的区域;
- 对抗学习(
Adversarial Learning):避免混乱图像带来的噪音,添加一个对抗损失帮助网络训练。
RCM

给定图像
- 对于
- 通过排序随机向量
- 类似的可以对每行块图像进行打乱操作,同样可以保证块图像在领域范围内移动
- 完成逐行逐列的打乱操作后,原始图像的每个块坐标
论文写的打乱公式还是很正式的,具体操作过程可查阅相关实现代码,会更加简单易懂
AL
论文设计了一个对抗损失用来避免网络学习打乱图像带来的噪声。具体操作如下:
- 获取分类网络
Backbone输出的特征向量 - 添加一个线性映射
2维向量; - 为每个图像设置一个
2值标签,0表示图像已解构,1表示图像未解构; - 设计
softmax分类器来判断图像是否被解构,公式如下:
- 定义交叉熵损失来提醒分类网络该图像是否解构,公式如下:
其中
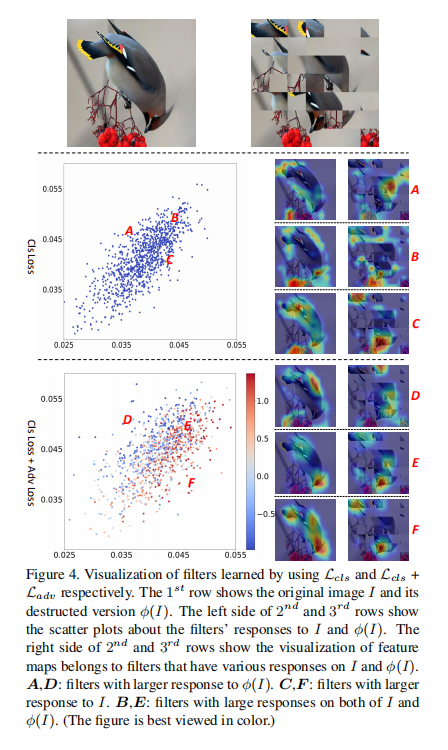
论文设计该2分类器的目的在于促使网络在不同集合(原始图像和打乱图像)学习过程中不会相互混淆。论文也对特征向量进行热力图显示,通过可视化方式证明了对抗学习的必要性
Construction Learning
给定图像
论文设计了一个区域对齐网络(region alignment network),用于建模打乱前后图像块之间的语义相关性和帮助网络学习目标全局结构。
- 获取分类网络的特征向量
- 使用
- 再经过
ReLU以及平均池化操作,最后输出
源码中论文使用了tanh而不是ReLU
其整体实现公式如下:
其中
2个通道维度分别表示块图像的横/纵坐标。
也就是说,如果使用了原始图像
区域对齐网络使用
损失函数
整体损失函数如下:
实验
在论文实验设置中,设置RCM中的超参数
分类
关于超参数
- 对于刚性物体识别数据集
Stanford Cars和FGVC-Aircraft,设置 - 对于非刚性目标识别数据集
CUB-200-2011,设置
定位
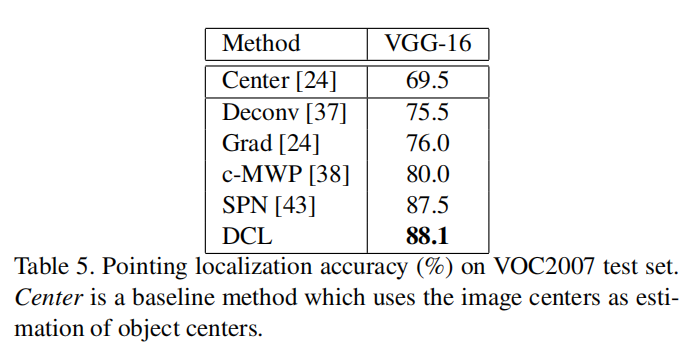
论文在VOC2007数据集上实验了弱监督目标定位任务,使用Pointing Localization Accuracy(SPN网络上应用DCL进行训练,精度从87.5%提高到88.1%
特征可视化
论文通过可视化分类网络最后输出特征向量,发现通过DCL训练的网络能够更加关注于有判别力区域

消融研究
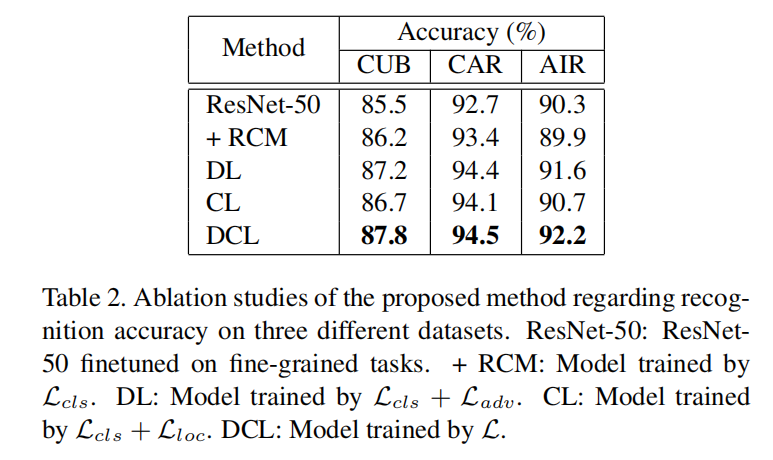
以ResNet-50为分类网络,在不同数据集上研究了DCL框架中各个增强模块的作用,证明了对抗学习和区域重构模块具有互补作用
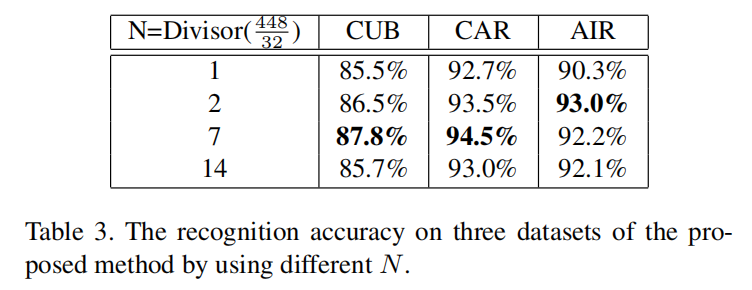
N设置
在上述数据集实验中,使用的输入图像大小为DCL作用。
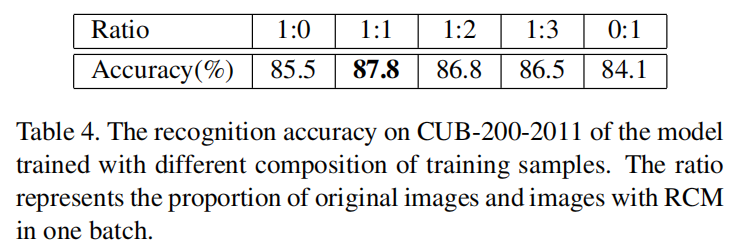
解构比率
论文还研究了在每一批次中原始图像和解构图像的比例,从结果来看,
k设置
超参数RCM打乱图像时的领域范围,论文比较了不同

小结
这是研究的第一篇细粒度分类相关论文,DCL训练框架通过RCM打乱图像,让网络更加关注于判别力区域;然后通过对抗学习避免打乱图像产生的噪声;以及通过区域对齐网络进一步学习各个块图像之间的语义相关性和目标全局结构。
还是需要好好阅读一下论文提供的源码,这样才能够更好的理解实际使用和各个模块含义,因为发现论文好多内容写的都不太好理解哈哈哈~~~
Gitalk 加载中 ...