Model Rubik's Cube: Twisting Resolution, Depth and Width for TinyNets
原文地址:Model Rubik's Cube: Twisting Resolution, Depth and Width for TinyNets
摘要
To obtain excellent deep neural architectures, a series of techniques are carefully designed in EfficientNets. The giant formula for simultaneously enlarging the resolution, depth and width provides us a Rubik's cube for neural networks. So that we can find networks with high efficiency and excellent performance by twisting the three dimensions. This paper aims to explore the twisting rules for obtaining deep neural networks with minimum model sizes and computational costs. Different from the network enlarging, we observe that resolution and depth are more important than width for tiny networks. Therefore, the original method, i.e., the compound scaling in EfficientNet is no longer suitable. To this end, we summarize a tiny formula for downsizing neural architectures through a series of smaller models derived from the EfficientNet-B0 with the FLOPs constraint. Experimental results on the ImageNet benchmark illustrate that our TinyNet performs much better than the smaller version of EfficientNets using the inversed giant formula. For instance, our TinyNet-E achieves a 59.9% Top-1 accuracy with only 24M FLOPs, which is about 1.9% higher than that of the previous best MobileNetV3 with similar computational cost. Code will be available at this https URL, and this https URL.
为了获得优秀的深层神经结构,我们精心设计了一系列高效的技术。同时扩大分辨率、深度和宽度的放大公式为我们提供了神经网络的魔方。因此,我们可以通过调整这三个维度来找到高效、性能优异的网络。本文旨在探索以最小模型尺寸和计算成本获得深度神经网络的调整规则。与网络放大不同,我们观察到对于微小网络,分辨率和深度(层数)比宽度(通道数)更重要。因此,原来的方法,即EfficientNet中的复合缩放不再适用。为此,以EfficientNet-B0为基准,通过约束FLOPs方式推导出一系列较小的模型,我们总结了一个缩小神经结构的缩小公式。ImageNet基准测试上的实验结果表明,我们的TinyNet比使用反向放大公式的更小版本的EfficientNet性能要好得多。例如,我们的TinyNet-E仅使用24M FLOPs即可实现59.9%的Top-1精度,这比之前计算成本相似的最佳MobileNetV3高出约1.9%。代码开源在https://github.com/huawei-noah/CV-Backbones
引言
论文首先以EfficientNet-B0为基准,将EfficientNet提出的同步调整分辨率、深度和宽度的放大公式进行反向计算,得到更小模型;然后,不再同步调整分辨率、深度以及宽度维度,而是随机设置3个维度(100个采样模型,发现在同一FLOPs约束下,随机调整参数的模型能够比基于放大公式调整的模型更好。
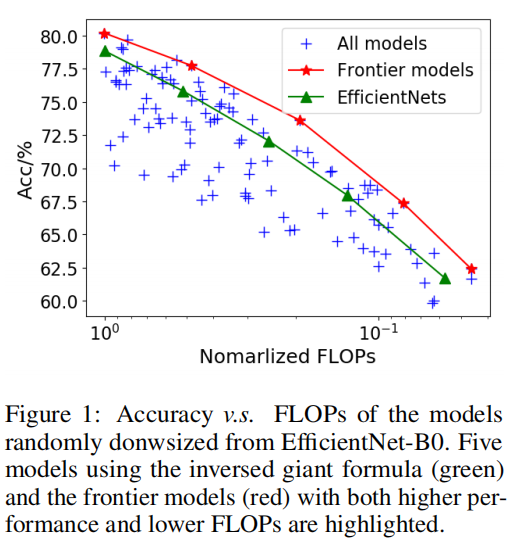
通过研究随机采样的模型训练结果,论文发现分辨率和深度比宽度维度更重要,而反向计算EfficientNet放大公式并不是最佳计算的原因在于它相对而言调整了更大幅度的分辨率维度。
论文设计了一个缩放公式,首先通过高斯进程回归(the Gaussian process regression)模拟最佳模型曲线;然后计算得到最优的分辨率和深度组合;最后基于FLOPs约束以及上一步得到的分辨率和深度大小确定最终的模型宽度。
维度评估
论文评估了指定FLOPs下不同维度(分辨率
FLOPs;
论文使用EfficientNet-B0为基准模型,采集FLOPs约束为FLOPs约束(差异在3%以内)。所有模型均在ImageNet上进行100轮训练,结果如下图所示:
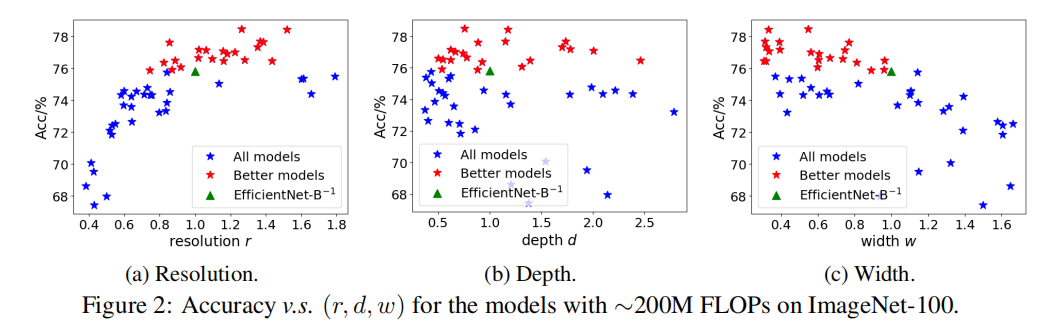
从上图可知,
- 分辨率对于模型精度有更大影响;
- 从图
2(a)可观察到,最佳精度模型分布在分辨率比例 - 当
- 当
- 从图
- 从图
2(b)可观察到,最佳精度模型分布在深度比例为- 如果约束深度维度大小,有可能限制了更好模型的探索。
- 从图
2(c)可观察到,宽度和模型精度有负相关性;- 最好精度的模型均分布在
- 也就是说,宽度越小,模型精度越高。
- 最好精度的模型均分布在
基于EfficientNet提出的放大公式进行反向操作得到3个维度相对于基准模型设置的比例分别为
Tiny Formula
总的来说,论文并没有给出一个非常清晰的数学公式来表达Tiny Formula,而是通过一系列代数推理公式来拟合实验过程中得到的训练数据,相对而言没有很高的复用性。毕竟,越简单,越客观。
论文通过随机采样一系列FLOPs在ImageNet上的识别精度,如下图所示
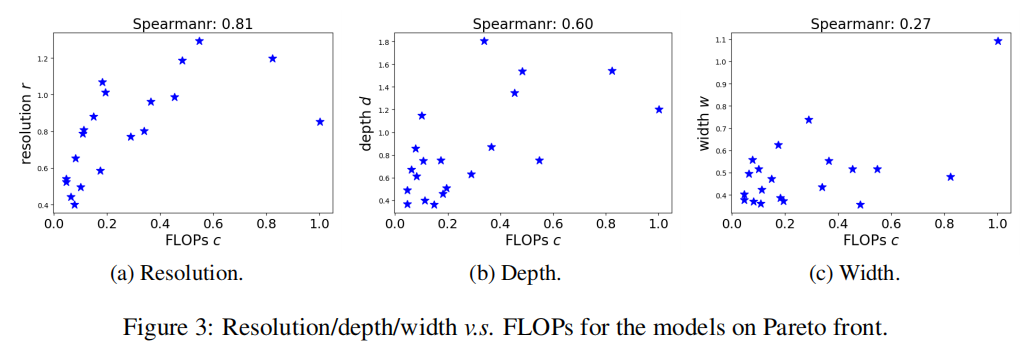
通过计算各个维度的Spearmanr相关系数(the Spearmanr score ???母鸡蛤),可以获取到不同维度重要性为
实验设置
针对EfficientNet-B0在ImageNet1000上的训练设置:
- 轮数:
450轮 - 优化器:
RMSProp,动量0.9,衰减0.9 - 权重衰减:
1e-5 - 批量归一化动量:
0.99 - 初始学习率:
0.048,每隔2.4轮衰减0.97 warmup:前3轮- 批量大小:
8卡V100,每张卡128张图像,共1024每次 - 随机失活:
0.2,应用于最后的全连接层 - 指数滑动平均:
0.9999
训练ResNet50:
- 轮数:
90轮 - 批量大小:
1024 - 优化器:
SGD,动量0.9 - 权重衰减
1e-4 - 初始学习率:
0.4,每隔30轮衰减0.1
TinyNet
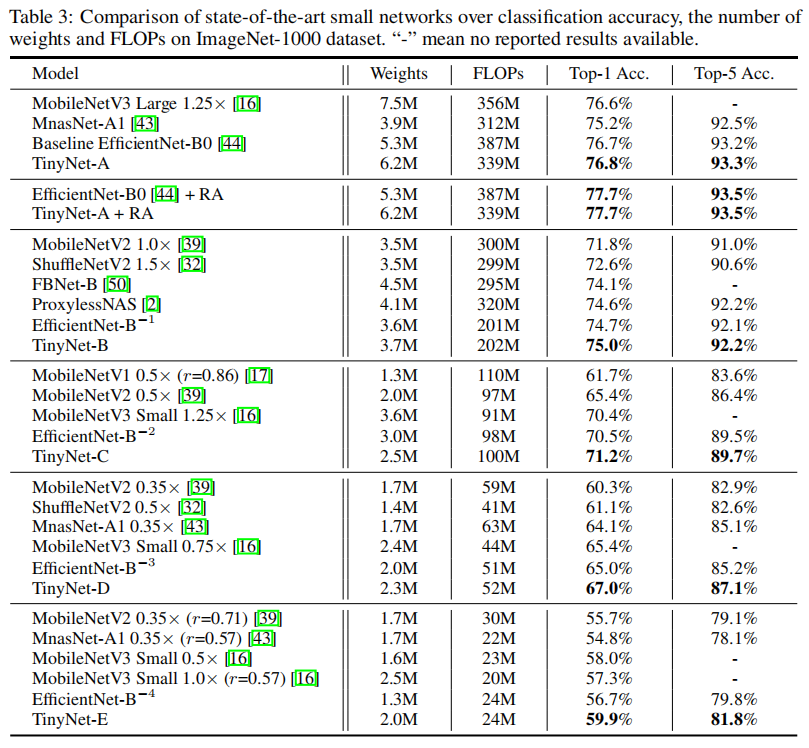
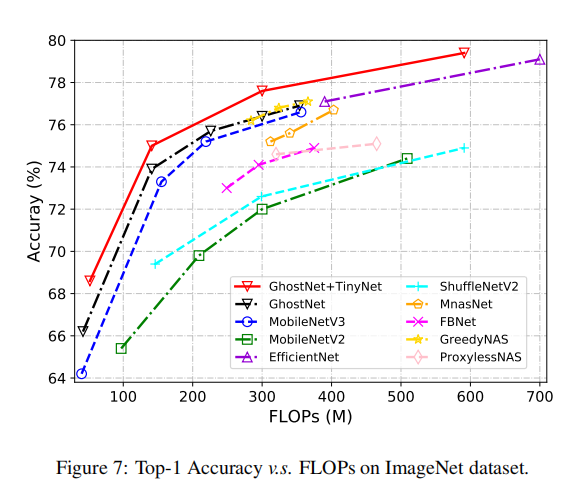
在ImageNet1000训练中,TinyNet一致性超越了其他小模型系列,论文同时指出RandAugment的有效性。设置RandAugment量级为9,标准方差为0.5,可以提高TinyNet-A和EfficientNet-B0的性能。整体训练结果如下图所示
论文同时比较了TinyNet和EfficientNet-B0在华为智能手机P40上的推理延时。批量为1,单线程模式,共运行1000次进行平均

论文还比较了EfficientNet-TinyNet-D在SDDLite上的表现

GhostNet
论文还以GhostNet为基准验证了TinyNet的有效性,另外通过配合HSwish(替换GhostNet的ReLU)和RandAugment,可以获取到更好的效果
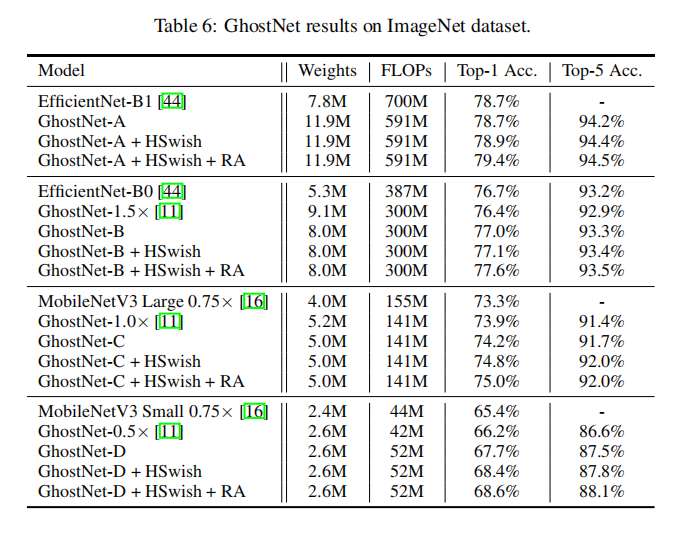
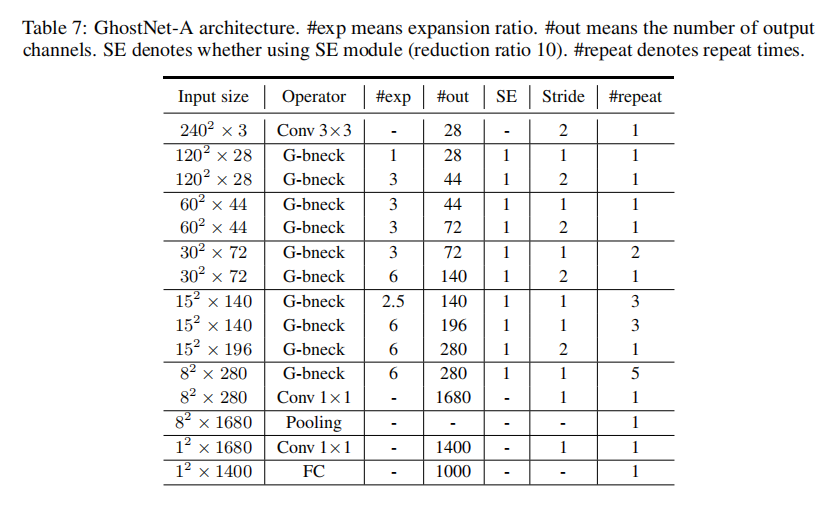
论文没有公布GhostNet-A/B/C/D的源码,不过提供了Ghostnet-A的架构设计
小结
论文重点:
- 证明了
EfficientNet手动设计的放大公式不适用于反向缩放; - 证明了模型的分辨率和深度比模型宽度更重要;
- 提供了
TinyNet的Pytorch实现和GhostNet-A的设计架构。
我对这篇论文的感受很复杂,首先它确实通过实验证明了存在更好设计的小模型架构,但是很显然它从中总结出的规律无法通过很明确的公式确定下来。另外小模型设计有可能并不是很具有市场价值,所以也没有感觉在传播上有很大热度。
最后,感谢诺亚实验室的这份工作,通过大量实验给出来更有效的模型设计。
Gitalk 加载中 ...