动量更新
动量(momentum)更新是梯度下降的一种优化方法,它能够加快损失函数收敛速度(converge rate)
标准梯度下降
标准梯度下降公式如下:
经典动量
经典动量(classical momentum,简称CM)公式如下
momentum coefficient),大小为
物理视角
从物理视角看损失函数收敛问题,将损失值看成丘陵地形(hilly terrain)的高度。对于初始化权重(initial velocity )为0的粒子(particle)。所以优化过程(optimization process)等同于模拟粒子在陆地上滚动的过程
驱动粒子滚动的力就是势能负梯度(
在标准梯度下降中,势能梯度直接用于修改粒子滚动的距离
在经典动量中,将力作用于粒子的速度和方向(
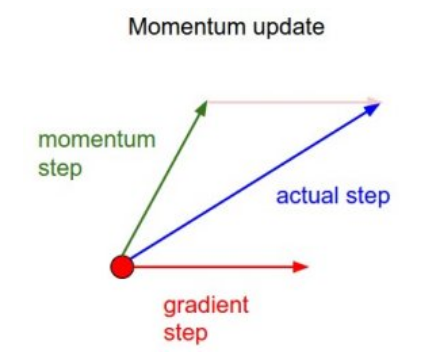
当力作用方向和累计速度方向一致时,就能够加快粒子滚动速度;与此同时,当力作用方向和累积速度方向不一致时,无法立刻修改粒子滚动方向,造成收敛曲线振荡
加速倍率
和标准梯度下降相比,经典动量能够加快损失值收敛速度。参考路遥知马力——Momentum,计算极限情况下加速倍率
对于标准梯度下降而言
对于经典动量更新而言
以
参考等比数列求和公式
- 当
- 当
- 当
也就是说,在极限状态下,当
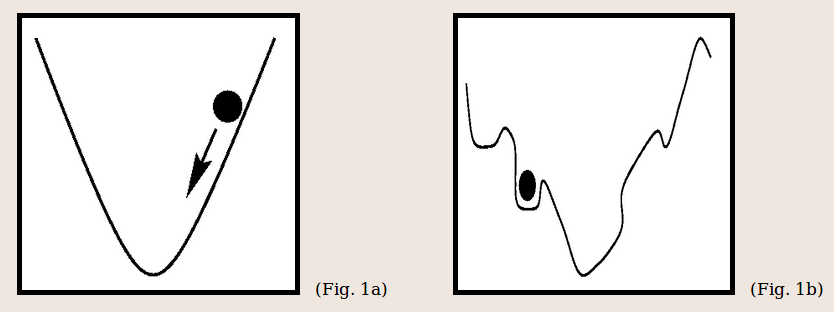
跳出局部最小值
参考Momentum and Learning Rate Adaptation,动量更新相比于标准梯度下降而言还有一个优点是它有可能能够跳出局部最小(local minima)点,找到全局最小(global minima)点
numpy测试
比较标准梯度下降和经典动量更新的损失值收敛梯度,比较不同动量因子(
高度计算公式为
实现代码
1 | # -*- coding: utf-8 -*- |
sgd vs momentum
设定学习率为0.001/0.01,动量因子为0.5,迭代100次的收敛情况
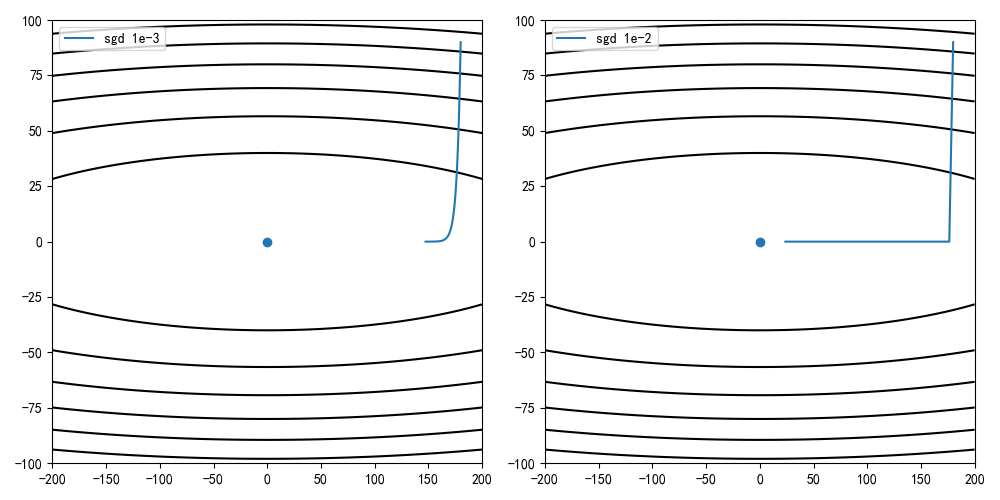
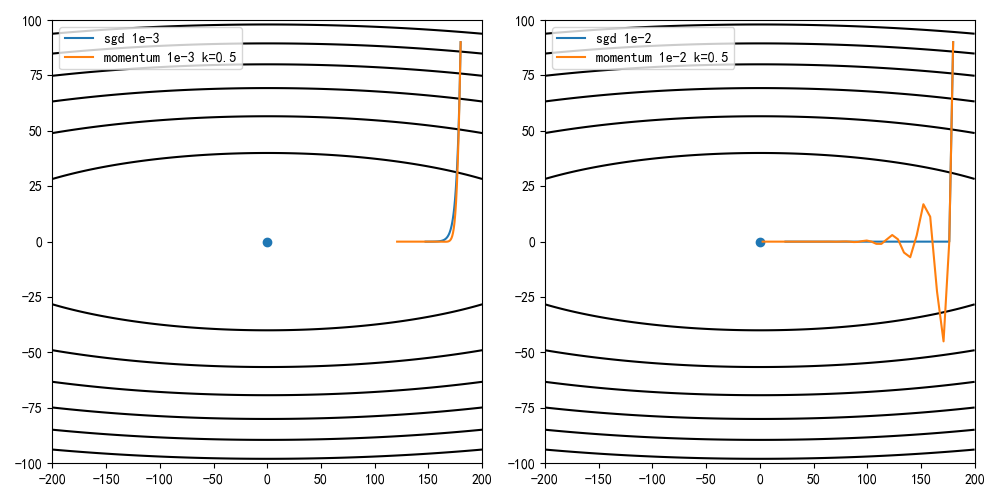
由结果可知,相同学习率和迭代数的情况下动量更新能够比标准梯度下降达到更快的收敛速度
1 | def draw(X, Y, Z, *arr): |
不同动量因子
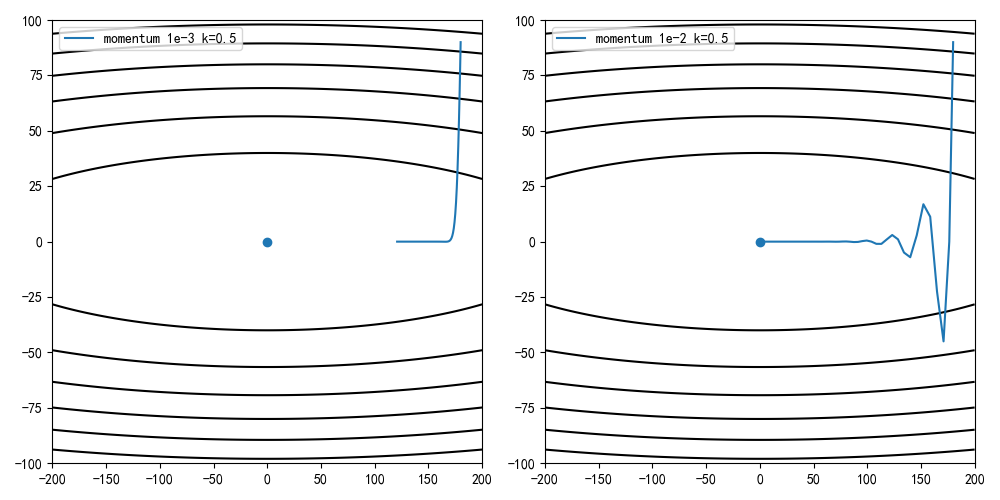
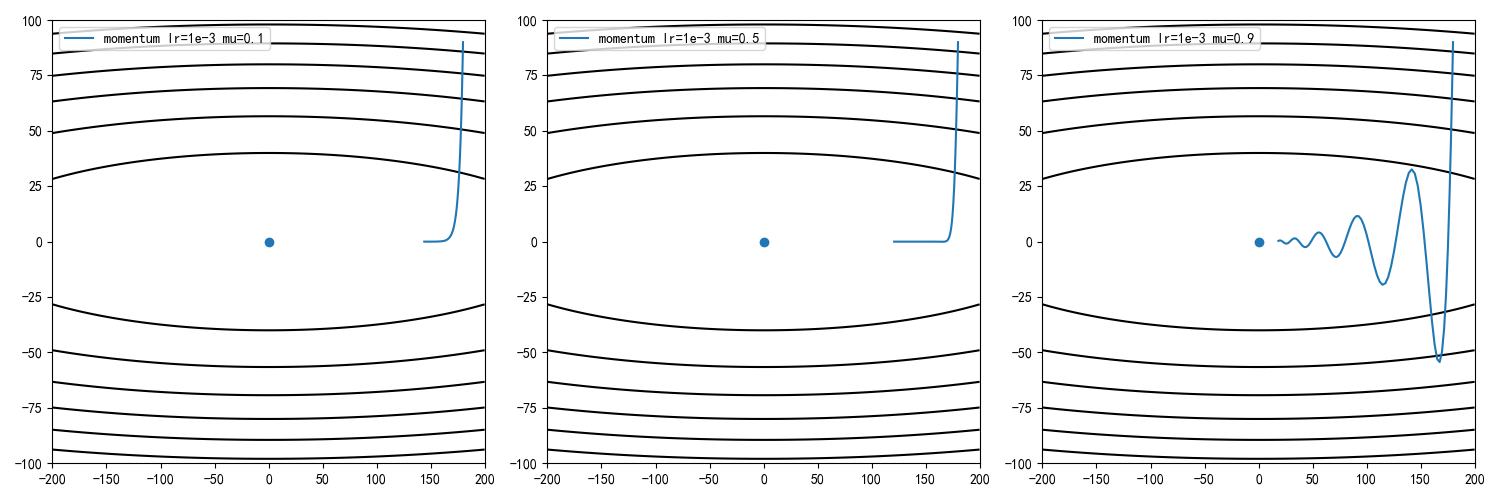
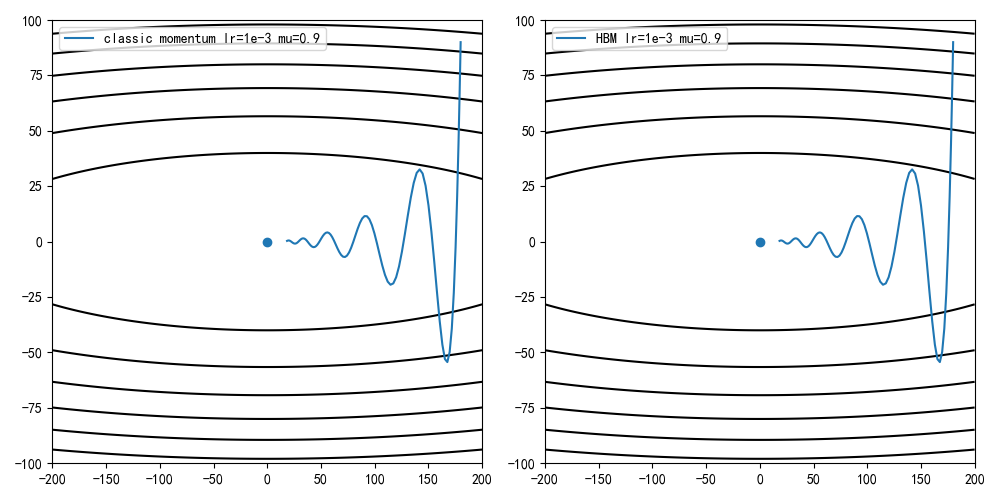
设定学习率为0.001,动量因子为0.1/0.5,0.9,计算迭代100次后的收敛情况
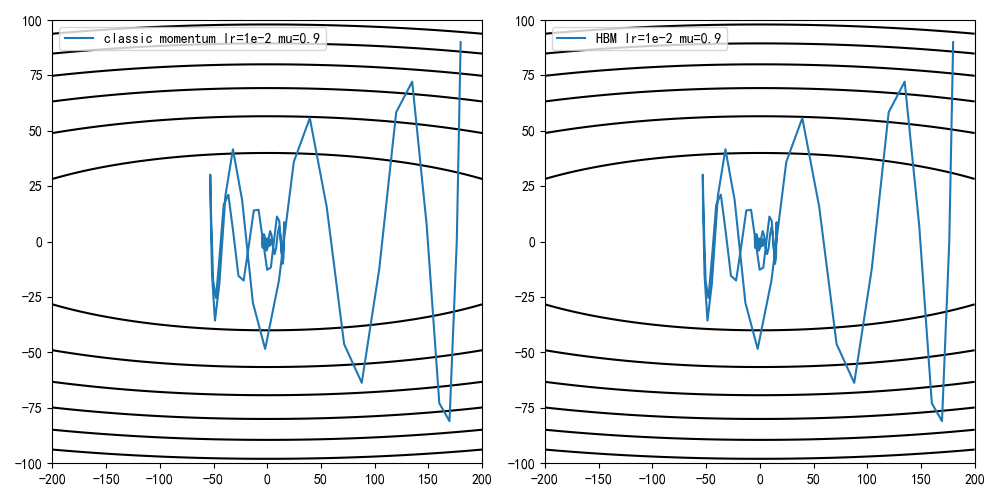
设定学习率为0.01,动量因子为0.1/0.5,0.9,计算迭代100次后的收敛情况
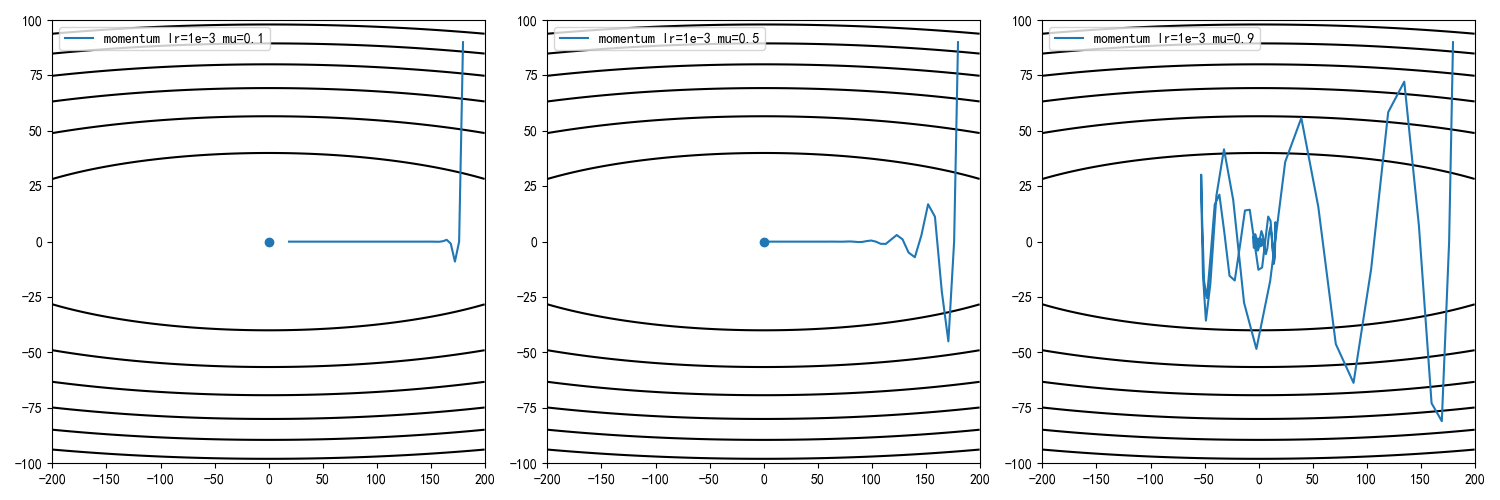
从训练结果可知,动量因子增大能够加快收敛速度,但同时收敛曲线更加动荡
1 | def draw(X, Y, Z, *arr): |
优化方法
动量因子增大能够带来更快的收敛速度,同时也带来了更动荡的收敛曲线
造成收敛曲线不稳定的原因在于累计速度和当前更新方向不一致,这是因为早期小批量图片计算的梯度不能够正确拟合全部图片导致的
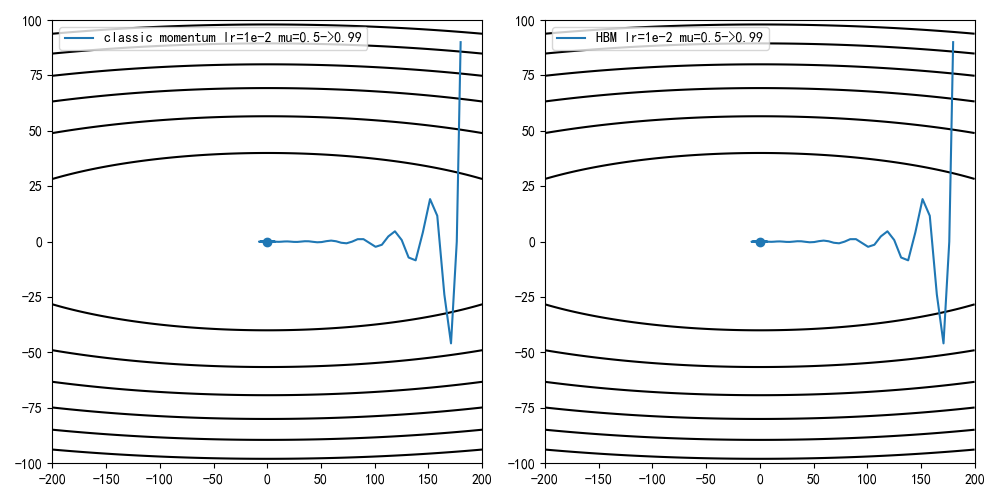
参考学习率退火,在早期设置一个较小的动量因子,随着迭代次数增加慢慢增大。比如设置mu=0.5,每轮迭代增加0.01,当mu=0,99时不再增加
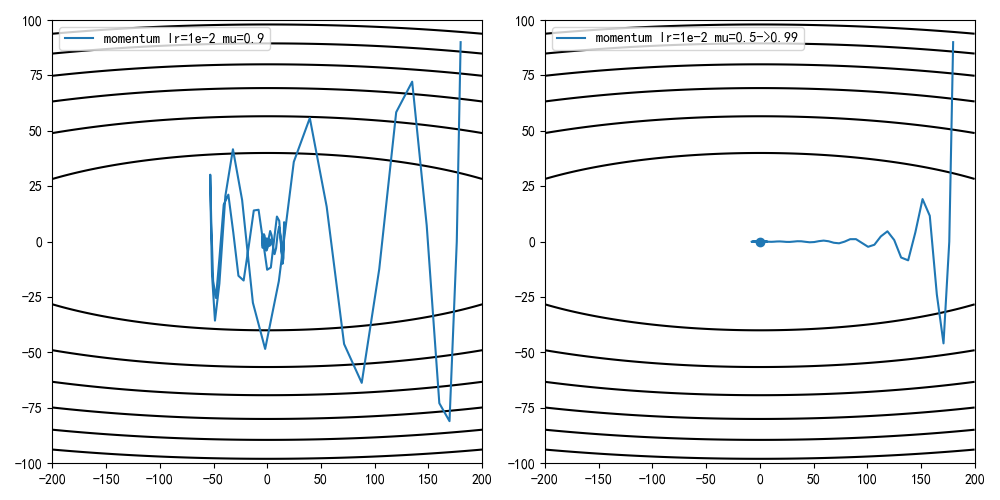
1 | def sgd_momentum_v2(x_start, lr, epochs=100): |
pytorch实现
torch.optim.SGD实现的动量更新公式有别于经典动量,使用的是重球法(heavy ball method,简称HBM)
其效果和经典动量类似
1 | def sgd_momentum_v3(x_start, lr, epochs=100, mu=0.5): |
小结
动量更新方法能够有效的加速训练过程,但需要注意学习率和动量因子的配合
未找到相关的 Issues 进行评论
请联系 @zjykzj 初始化创建