Nesterov加速梯度
Nesterov加速梯度(Nesterov's Accelerated Gradient,简称NAG)是梯度下降的一种优化方法,其收敛速度比动量更新方法更快,收敛曲线更加稳定
实现公式
NAG计算公式参考On the importance of initialization and momentum in deep learning
其实现和经典动量的区别在于 NAG计算的是当前权重加上累积速度后的梯度
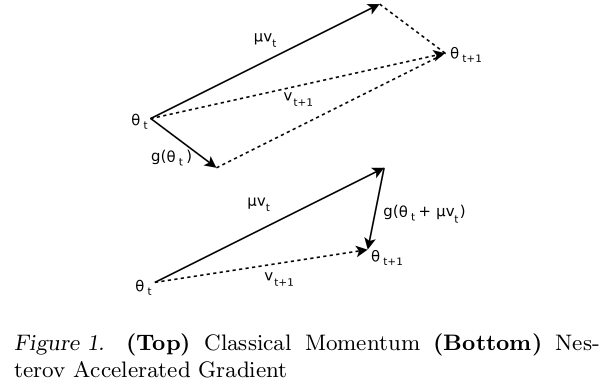
替换公式
实际使用过程中使用替换公式,参考Neural Networks Part 3: Learning and Evaluation
所以替换公式为
将使用的权重向量替换为权重向量加上累积速度后的权重值
numpy测试
参考:动量更新
原始公式实现
NAG实现代码如下
1 | def sgd_nesterov(x_start, lr, epochs=100, mu=0.5): |
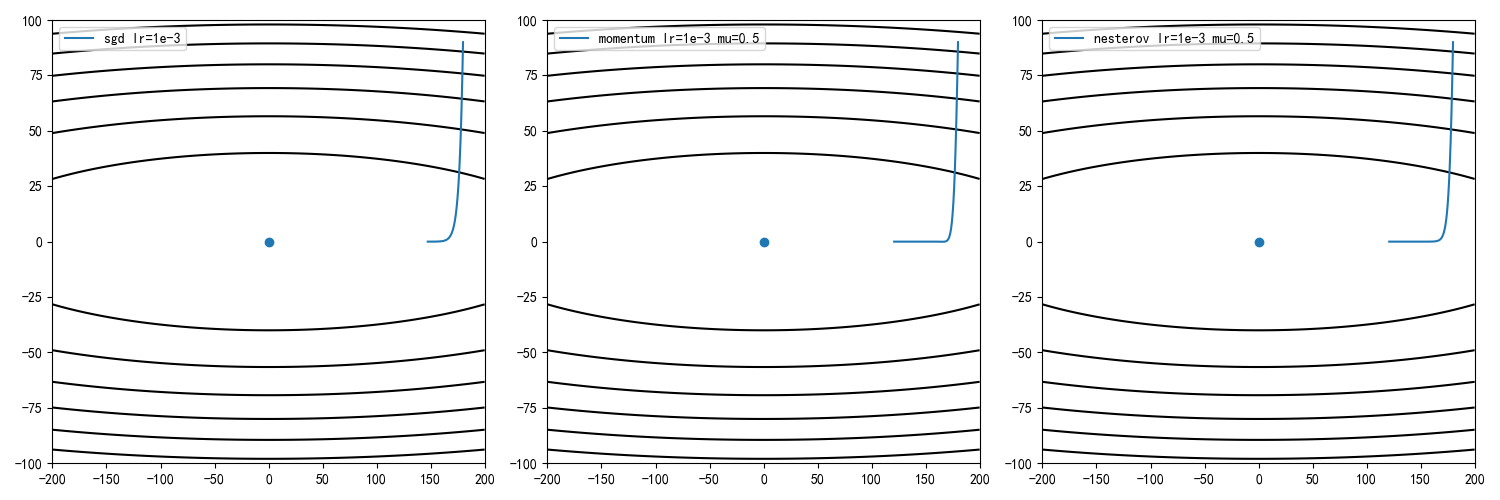
SGD vs CM vs NAG
学习率1e-3,动量因子0.5,迭代100次结果
学习率1e-2,动量因子0.5,迭代100次结果
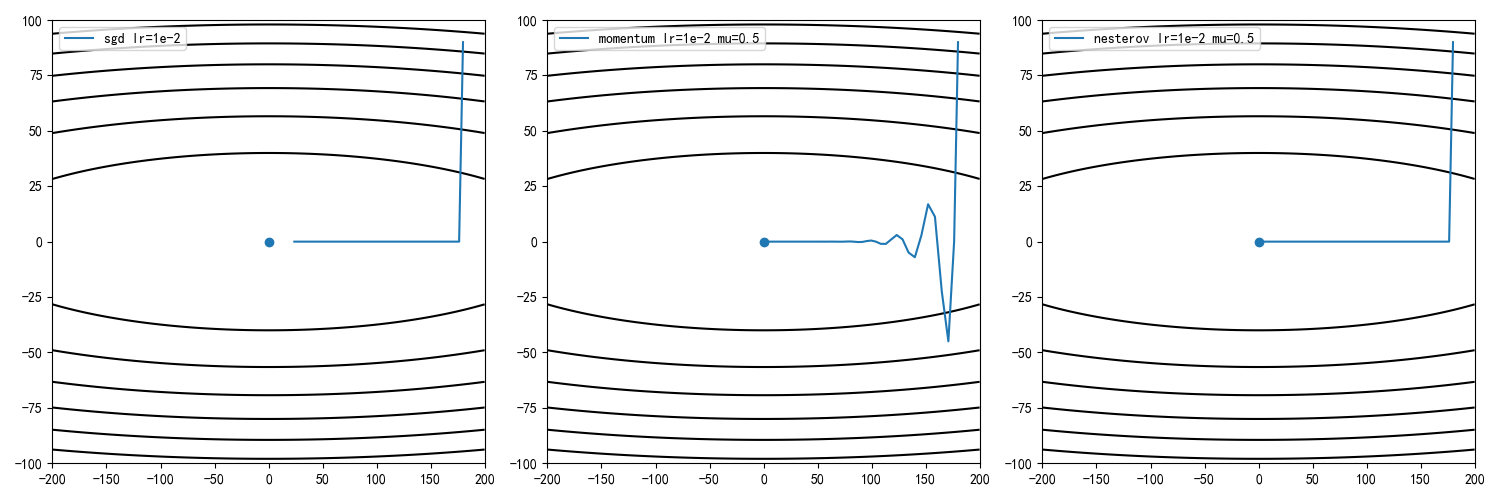
经典动量和NAG方法的收敛速度均比标准梯度下降更快
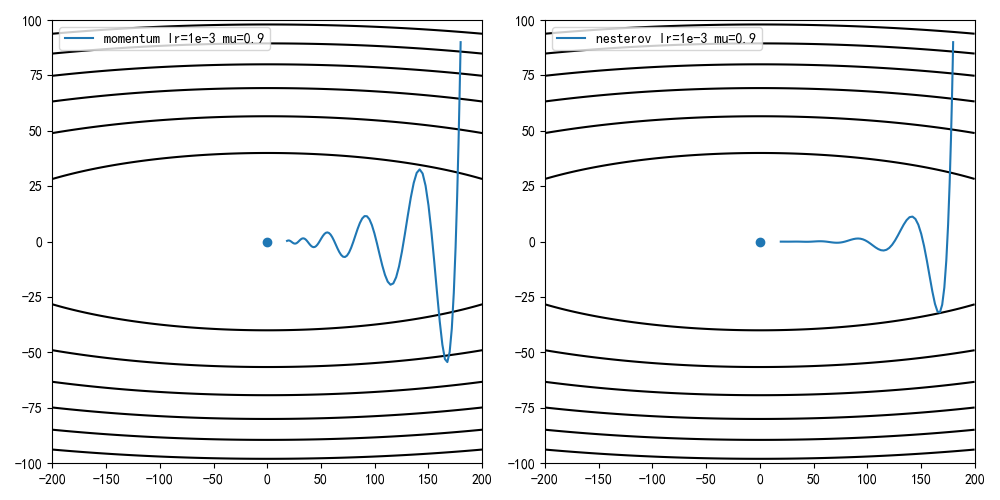
CM vs NAG
学习率1e-3,动量因子0.9,迭代100次结果
学习率1e-2,动量因子0.9,迭代100次结果
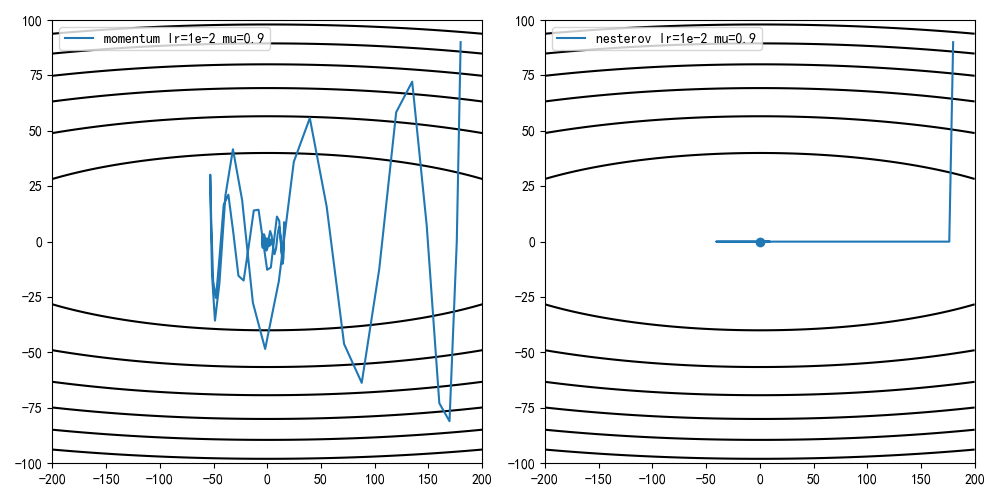
NAG方法的收敛曲线比经典动量方法更稳定
替换公式实现
替换公式实现代码如下:
1 | def sgd_nesterov_v2(x_start, lr, epochs=100, mu=0.5): |
NAG vs NAG_alter
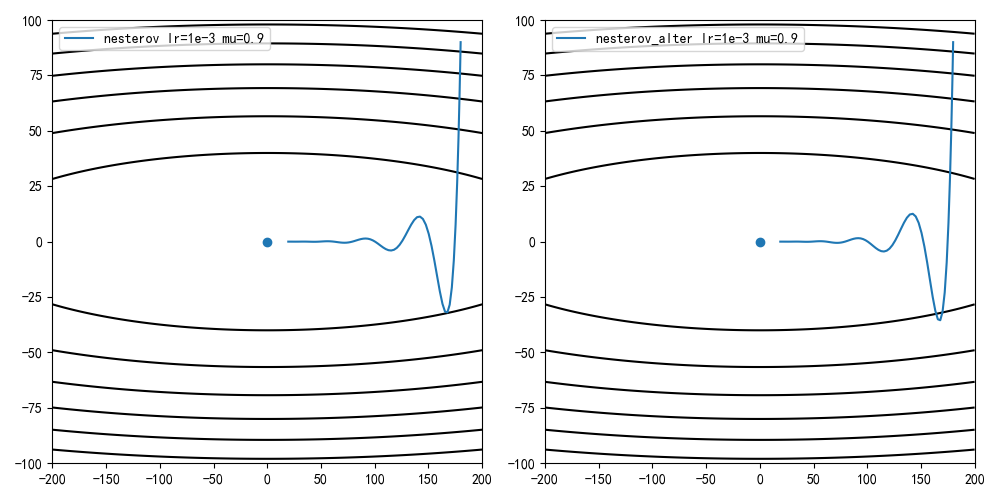
学习率1e-3,动量因子0.9,迭代100次结果
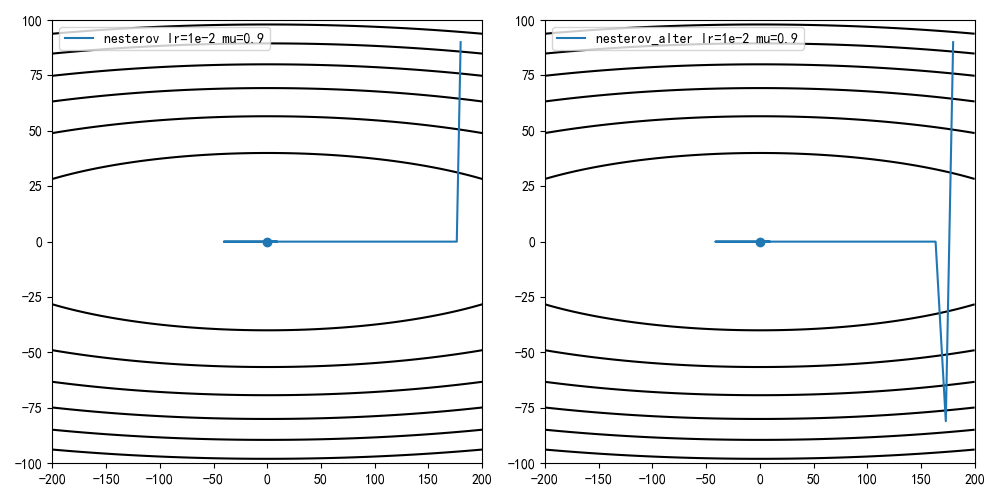
学习率1e-2,动量因子0.9,迭代100次结果
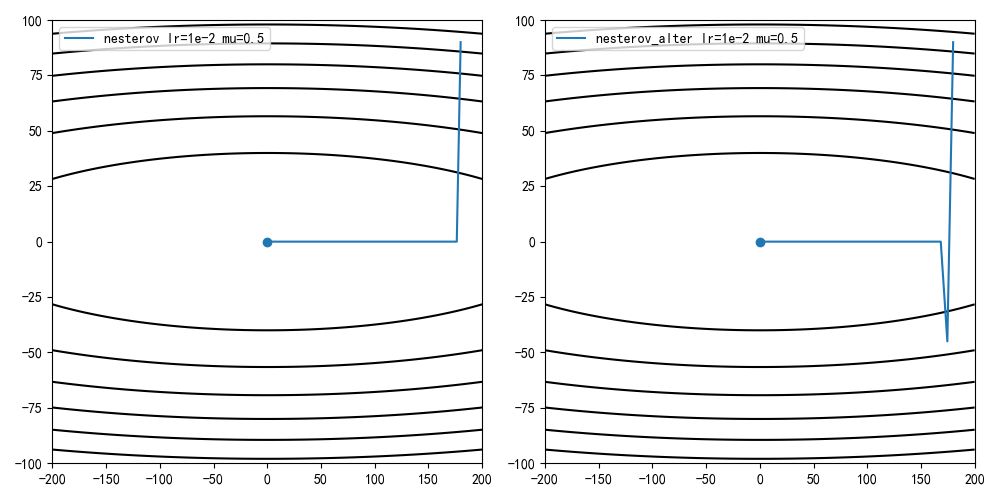
学习率1e-2,动量因子0.5,迭代100次结果
Gitalk 加载中 ...