[GoogLeNet]Inception-ResNet-v2
参考:Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning,解析Inception-ResNet-v2架构
总体架构
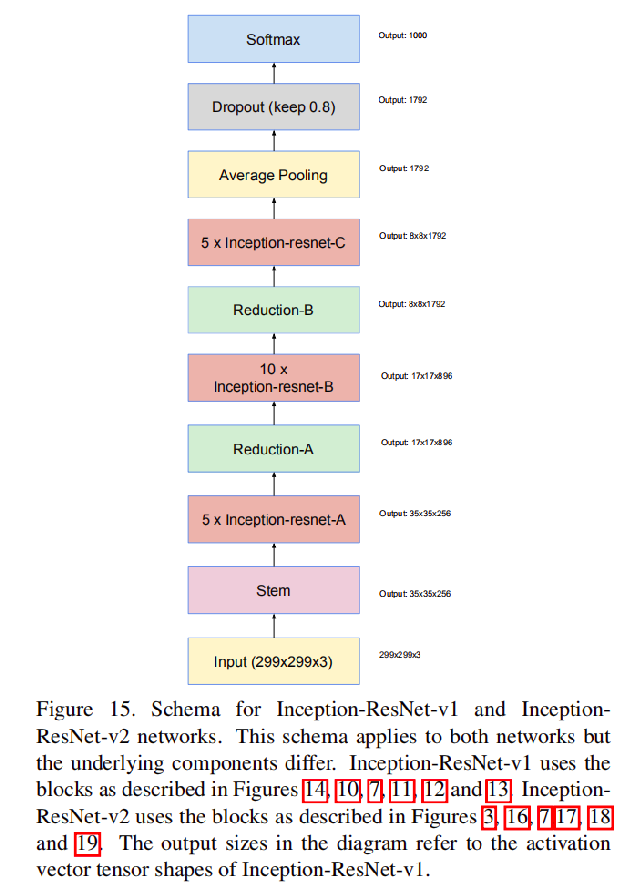
All the convolutions not marked with “V” in the figures are same-padded meaning that their output grid matches the size of their input. Convolutions marked with “V” are valid padded, meaning that input patch of each unit is fully contained in the previous layer and the grid size of the output activation map is reduced accordingly
Note:上图显示的输出大小参考的是Inception-ResNet-v1架构
在下面各个模块的结构图中,没有加\(V\)符号的表示其输出数据体的空间尺寸和输入相同;加\(V\)符号的表示输出数据体空间尺寸进行了衰减
Stem
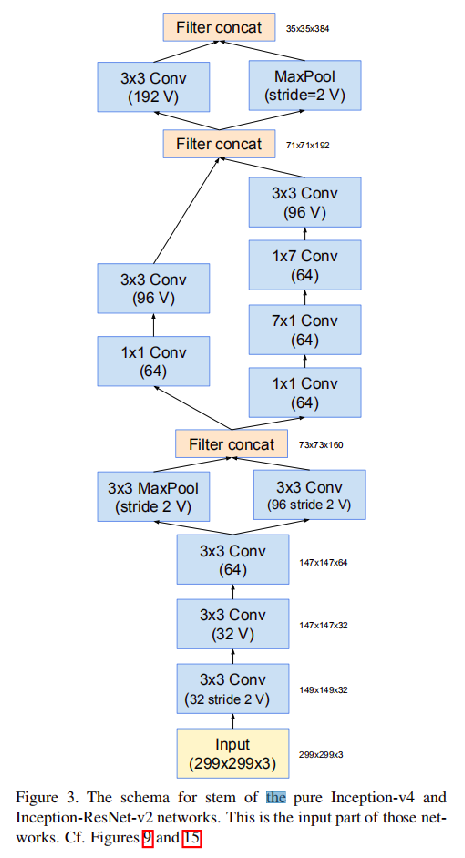
- \(Input = 3\times 299\times 299\)
- \(Output = 384\times 35\times 35\)
Inception-ResNet-A
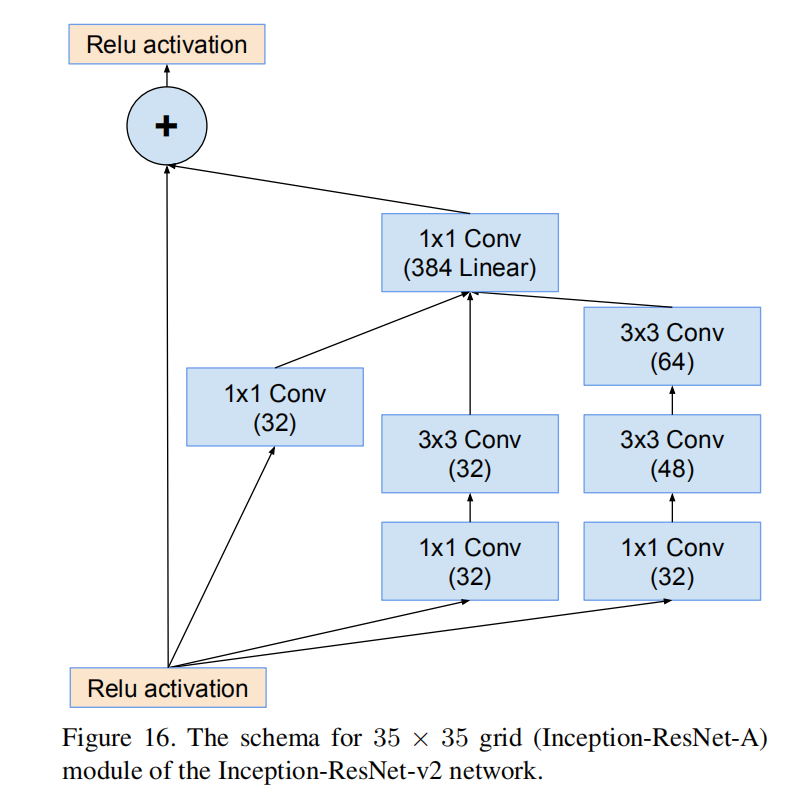
- \(Input = 384\times 35\times 35\)
- \(Output = 384\times 35\times 35\)
Reduction-A
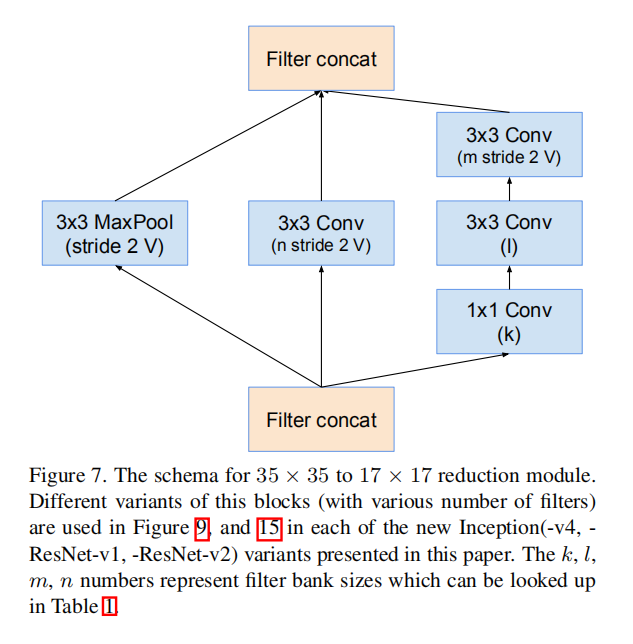
超参数\(k = 256, l = 256, m = 384, n = 384\)
- \(Input = 384\times 35\times 35\)
- \(Output = 1152\times 17\times 17\)
Inception-ResNet-B
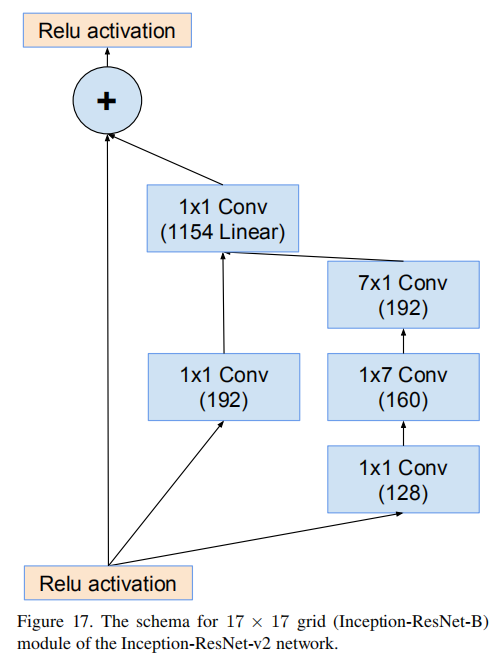
- \(Input = 1152\times 17\times 17\)
- \(Output = 1154\times 17\times 17\)
Reduction-B
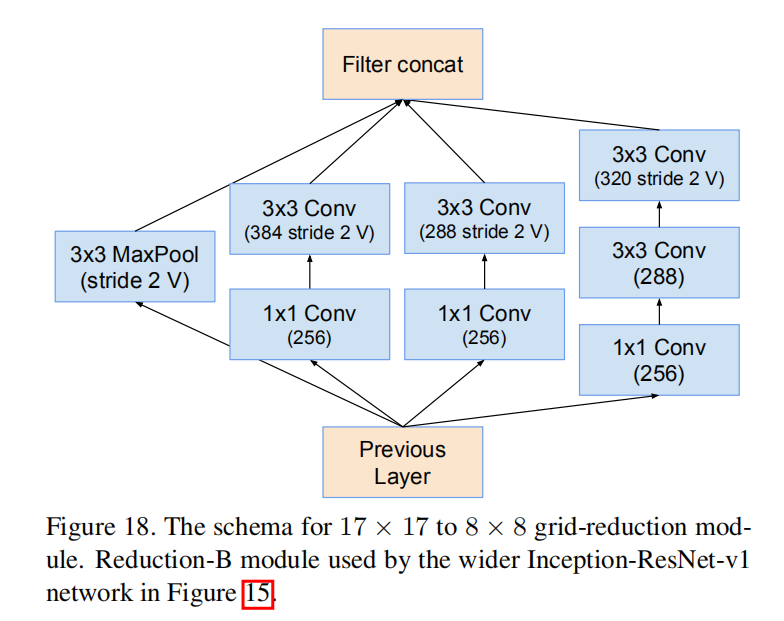
- \(Input = 1154\times 17\times 17\)
- \(Output = 2146\times 8\times 8\)
Inception-ResNet-C
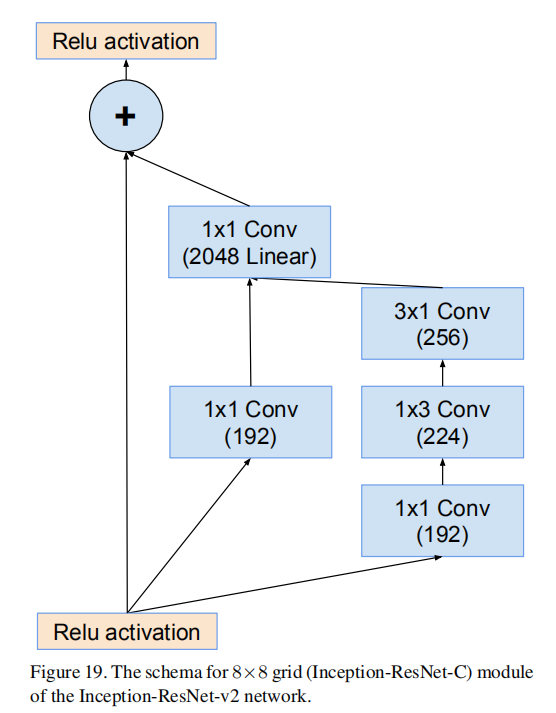
- \(Input = 2146\times 8\times 8\)
- \(Output = 2048\times 8\times 8\)
实现
分别定义上述6个模块,然后定义Inception_ResNet_v2模型,完整实现参考inception_resnet_v2.py