Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
原文地址:Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
论文基于Inception结构和残差连接实现了3个网络:
Inception-v4Inception-ResNet-v1Inception-ResNet-v2
通过实验证明了残差连接能够很好的改善训练速度,同时证明了非残差的Inception网络同样能够实现最好的分类精度
摘要
Very deep convolutional networks have been central to the largest advances in image recognition performance in recent years. One example is the Inception architecture that has been shown to achieve very good performance at relatively low computational cost. Recently, the introduction of residual connections in conjunction with a more traditional architecture has yielded state-of-the-art performance in the 2015 ILSVRC challenge; its performance was similar to the latest generation Inception-v3 network. This raises the question of whether there are any benefit in combining the Inception architecture with residual connections. Here we give clear empirical evidence that training with residual connections accelerates the training of Inception networks significantly. There is also some evidence of residual Inception networks outperforming similarly expensive Inception networks without residual connections by a thin margin. We also present several new streamlined architectures for both residual and non-residual Inception networks. These variations improve the single-frame recognition performance on the ILSVRC 2012 classification task significantly. We further demonstrate how proper activation scaling stabilizes the training of very wide residual Inception networks. With an ensemble of three residual and one Inception-v4, we achieve 3.08% top-5 error on the test set of the ImageNet classification (CLS) challenge.
极深卷积网络是近年来图像识别性能最大进步的核心。一个例子是Inception架构,它已经被证明在相对较低的计算成本下实现了非常好的性能。最近,在2015年ILSVRC挑战赛中,残差连接与更传统的架构相结合产生了最先进的性能;其性能类似于最新一代的Inception-v3网络。这就提出了这样一个问题:将Inception架构与残差连接相结合是否有效。在这里,我们给出了明确的经验证据表明,使用残差连接的训练显著加快了Inception网络的训练。同样有证据表明,在没有残差连接的情况下,残差Inception网络的性能比Inception网络的性能要差得多。我们还为残差和非残差Inception网络提出了几种新的简化架构。这些变化显著提高了ILSVRC 2012分类任务的单帧识别性能。我们进一步证明了适当的激活尺度如何稳定极宽残差Inception网络的训练。通过集成三个残差和一个Inception-v4网络,我们在ImageNet分类(CLS)挑战的测试集上获得了3.08%的top-5误差率
模型
Inception-ResNet-v1:混合Inception版本,其计算成本类似于Inception-v3Inception-ResNet-v2:计算成本更高的混合Inception版本,其识别性能显著提高Inception-v4:纯Inception版本,没有残差连接的情况下识别性能与Inception-ResNet-v2大致相同
残差缩放
Also we found that if the number of filters exceeded 1000, the residual variants started to exhibit instabilities and the network has just “died” early in the training, meaning that the last layer before the average pooling started to produce only zeros after a few tens of thousands of iterations. This could not be prevented, neither by lowering the learning rate, nor by adding an extra batch-normalization to this layer.
我们还发现,如果滤波器的数量超过1000个,残差Inception网络开始表现出不稳定性,并且网络在训练早期就“死亡”,这意味着平均池化之前的最后一层在几万次迭代之后开始只产生零。这是无法避免的,既不能通过降低学习速度,也不能通过在这一层增加额外的批量标准化
We found that scaling down the residuals before adding them to the previous layer activation seemed to stabilize the training. In general we picked some scaling factors between 0.1 and 0.3 to scale the residuals before their being added to the accumulated layer activations (cf. Figure 20).
我们发现,在将残差添加到前一层激活之前缩小残差似乎可以稳定训练。总的来说,我们选择了0.1到0.3之间的一些缩放因子来缩放残差,然后将它们添加到累积层激活中(参见图20)
A similar instability was observed by He et al. in [5] in the case of very deep residual networks and they suggested a two-phase training where the first “warm-up” phase is done with very low learning rate, followed by a second phase with high learning rata. We found that if the number of filters is very high, then even a very low (0.00001) learning rate is not sufficient to cope with the instabilities and the training with high learning rate had a chance to destroy its effects. We found it much more reliable to just scale the residuals.
在非常深的残差网络中,何等人在[5]中观察到了类似的不稳定性,他们提出了两阶段训练,其中第一个“预热”阶段以非常低的学习速率完成,随后是具有高学习速率的第二阶段。我们发现,如果滤波器的数量非常大,那么即使非常低(0.00001)的学习率也不足以应对不稳定性,并且具有高学习率的训练有可能破坏其效果。我们发现仅仅缩放残差要可靠得多
Even where the scaling was not strictly necessary, it never seemed to harm the final accuracy, but it helped to stabilize the training.
即使在严格来说不需要缩放的地方,它似乎也不会损害最终的准确度,但它有助于稳定训练
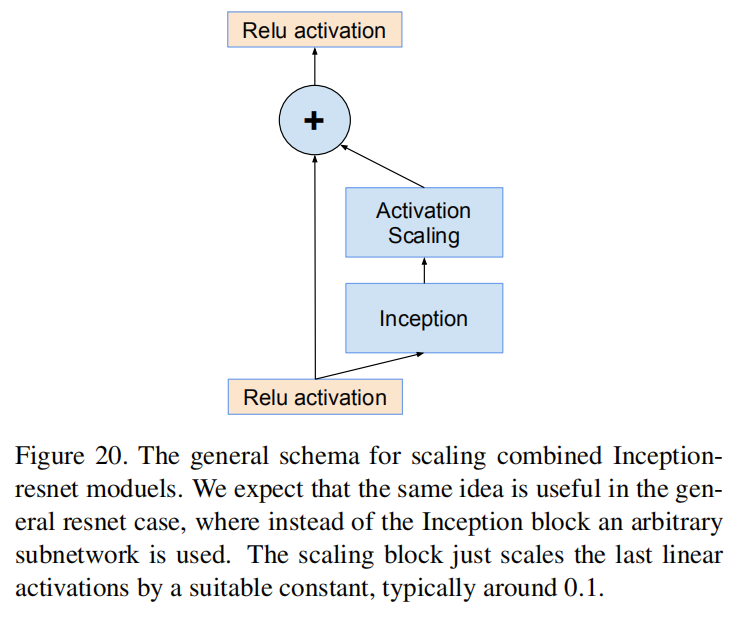
Figure 20. The general schema for scaling combined Inception-resnet moduels. We expect that the same idea is useful in the general resnet case, where instead of the Inception block an arbitrary subnetwork is used. The scaling block just scales the last linear activations by a suitable constant, typically around 0.1.
图20。缩放Inception-ResNet模块的通用模式。我们期望同样的想法在一般的ResNet情况下是有用的,在这种情况下,使用一个任意的子网来代替Inception模块。Activation Scaling模块仅使用合适的常数进行最后的线性激活,通常在0.1左右
训练方法
- 优化器:
RMSProp,decay=0.9, - 学习率:
0.045。每2个阶段进行指数衰减,衰减因子为0.94
共运行了20个相同结构的模型,每一个分别运行在Nvidia Kelper GPU上。完成训练后平均这些模型参数得到最后的模型
实验结果
表2显示了单模型 - 单裁剪测试结果
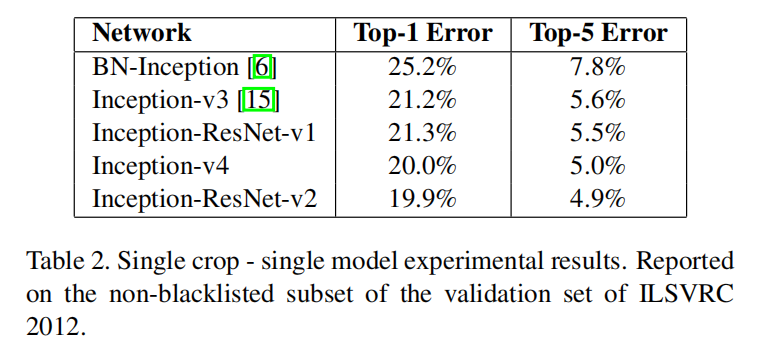
表3显示了单模型 - 10/12裁剪测试结果
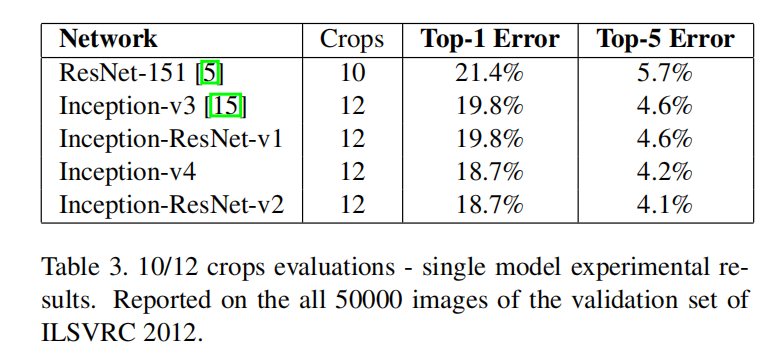
表4显示了单模型 - 144裁剪测试结果
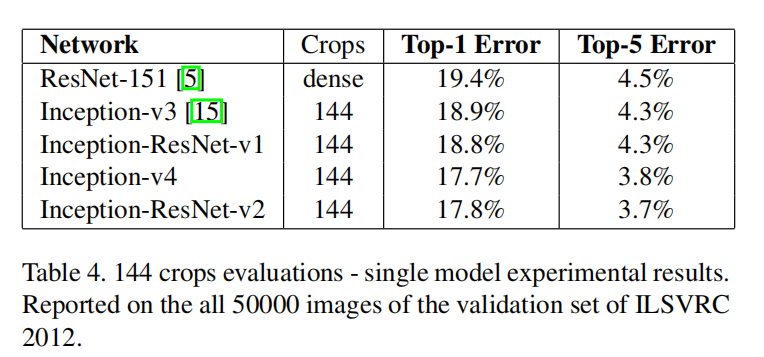
表5显示了模型集成 - 144裁剪测试结果

未找到相关的 Issues 进行评论
请联系 @zjykzj 初始化创建