[Deep Residual Learning for Image Recognition]用于图像识别的深度残差学习
原文地址:Deep Residual Learning for Image Recognition
摘要
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers - 8×deeper than VGG nets [41] but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers.
更深层的神经网络更难训练。我们提出了一个残差学习框架来简化网络的训练,这些网络比以前使用的要深得多。我们将网络重构为可学习层输入的残差函数,而不是学习不相关数据的函数。实践经验表明,这些残差网络更容易优化,并可以通过增加网络深度提高准确性。在ImageNet数据集上,我们评估了深度高达152层(比VGG网络[41]深8倍),并且仍旧保持低复杂度的残差网络。集成多个残差网络进行测试,在ImageNet测试集上实现了3.57%误差率。该结果在ILSVRC 2015分类任务中获得第一名。我们还使用100层和1000层的网络对CIFAR-10进行了分析
The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015
, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.
表示能力的深度对于许多视觉识别任务来说是至关重要的。仅依靠我们非常深的网络,我们在COCO目标检测数据集上获得了28%的相对改进。在ILSVRC & COCO 2015
1:http://image-net.org/challenges/LSVRC/2015/ and http://mscoco.org/dataset/#detections-challenge2015.
网络深度
网络深度的增加能够捕获更多的特征,同时也出现了以下问题:
- 如何避免梯度消失(
vanishing)和爆炸(exploding)的问题 - 如何避免网络退化(
degradation),就是检测精度饱和的问题
针对第一个问题,可以通过初始参数的标准化和中间层输入的批量归一化得到解决;本文通过深度残差学习框架解决第二个问题
通过ImageNet以及CIFAR-10数据集上的实验证明以下内容:
- 深度残差网络更容易优化,与此同时,相对应的普通网络会随着层数的增加得到更高的误差率
- 深度残差网络更容易通过层数增加得到更高的准确度,其结果比之前所有的网络都好
网络退化
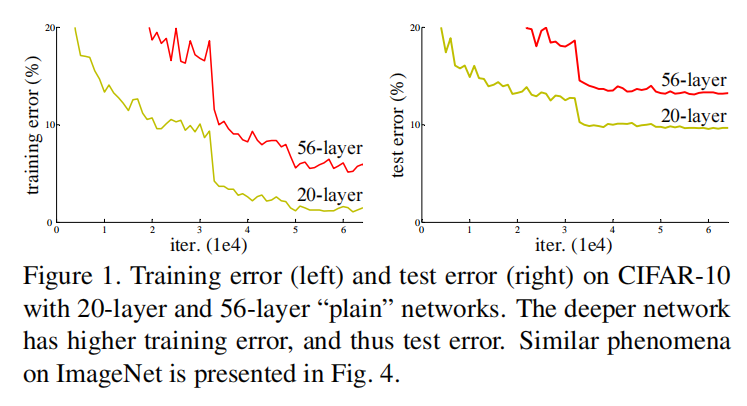
对于普通网络架构,深度的增加会反而会导致更高的训练误差,也就是网络退化问题,如上图所示
残差学习框架
假设理想输出结果为
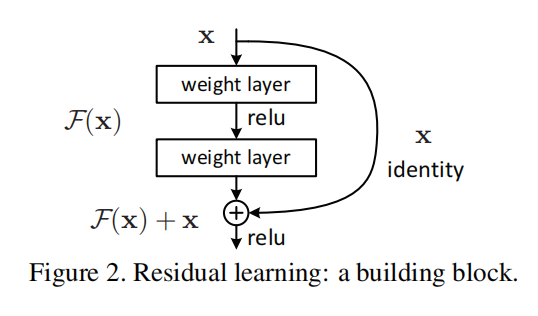
所以论文提出一种残差结构,如上图所示:在网络输出
上图显示的是一个残差网络的构建块(building blocks),其计算如下:
在图2中是一个两层网络,所以
- 如果
identity mapping) - 如果
projection mapping)
另外,在构建块中可以使用多层网络,在论文中设置为2层或者3层
VGG vs. ResNet
论文比较了VGG和ResNet,通过多个不同深度的网络进行比较
VGG-34
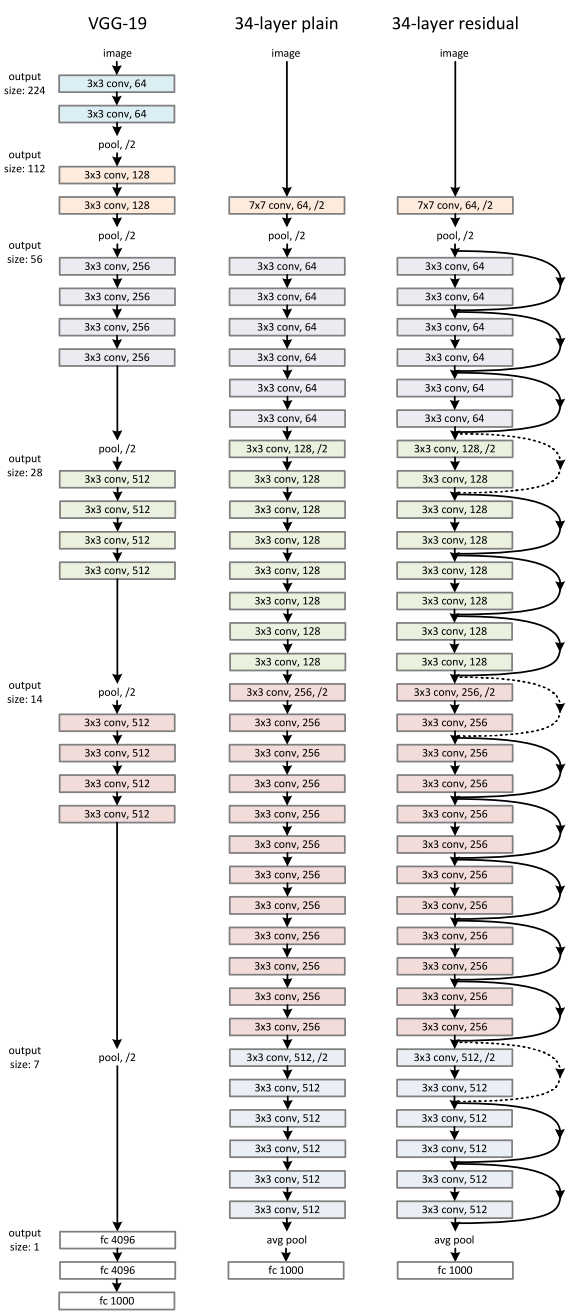
将VGG-19网络扩展到34层,其实现如Appendix A所示。遵循以下实现原则:
- 对于相同输出特征图的大小,使用相同数量的滤波器
- 如果特征图大小减半,那么加倍滤波器数量,以保持逐层的时间复杂度
同时对网络进行了部分修改:
- 在卷积层中使用步长为
2进行下采样 - 卷积操作结束后使用全局平均池化层替代全连接层
ResNet-34
基于VGG-34设计了一个34层的残差网络ResNet-34,其实现如Appendix A所示。其快捷连接(identity shortcuts)分为两种情况:
- 当构建块的输入和输出维度相同时(图中的实线部分),直接进行连接
- 当构建块的输入和输出维度不同时(图中的点线部分),考虑两种实现方式(后续进行实验比对):
- 通过零填充(
extra zero entries padded)的方式增加维度 - 通过投影(
projection shortcut)的方式增加维度(使用
- 通过零填充(
VGG-18/ResNet-18
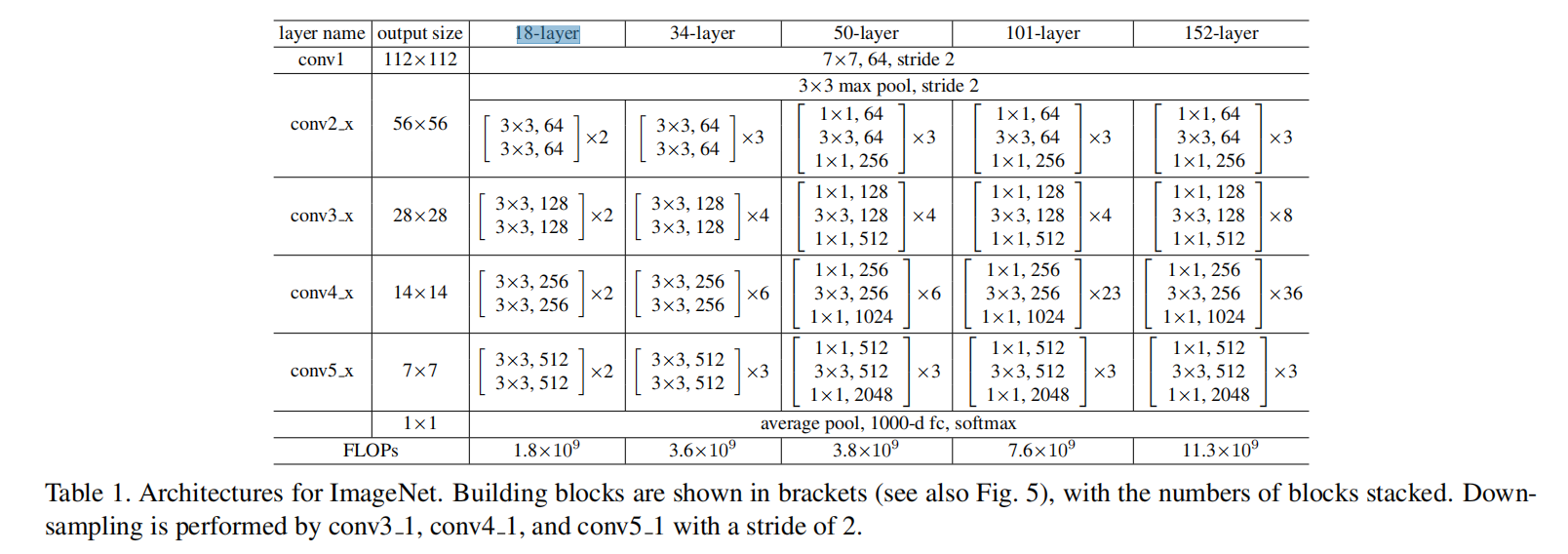
论文同时设计了两个18层的网络,其实现参考了34层网络的设计,具体参数参考Appendix B
ImageNet训练
使用上述网络训练1000类的ImageNet 2012分类数据集,包含了128万训练图像、5万张验证图像和10万张测试图像
训练阶段:
- 输入图像
- 将图像缩放至
256/480(较短边),然后随机采样(224, 224)大小,并进行随机水平翻转 - 数据归一化
- 标准的颜色扩充方法
- 将图像缩放至
- 在每个卷积层之后(激活之前)使用批量归一化
- 批量大小:
256 - 损失函数:交叉熵损失
- 优化方法:
SGD - 学习率:从
0.1开始,当误差稳定时减少10倍 - 权重衰减:
1e-4 - 动量:
0.9
测试阶段:
10-crop:裁剪图像中心和四个角,然后进行水平翻转- 多尺度:将图像分别缩放至
{224, 256, 384, 480, 640}
依据上述操作共得到
VGG-18 vs. VGG-34
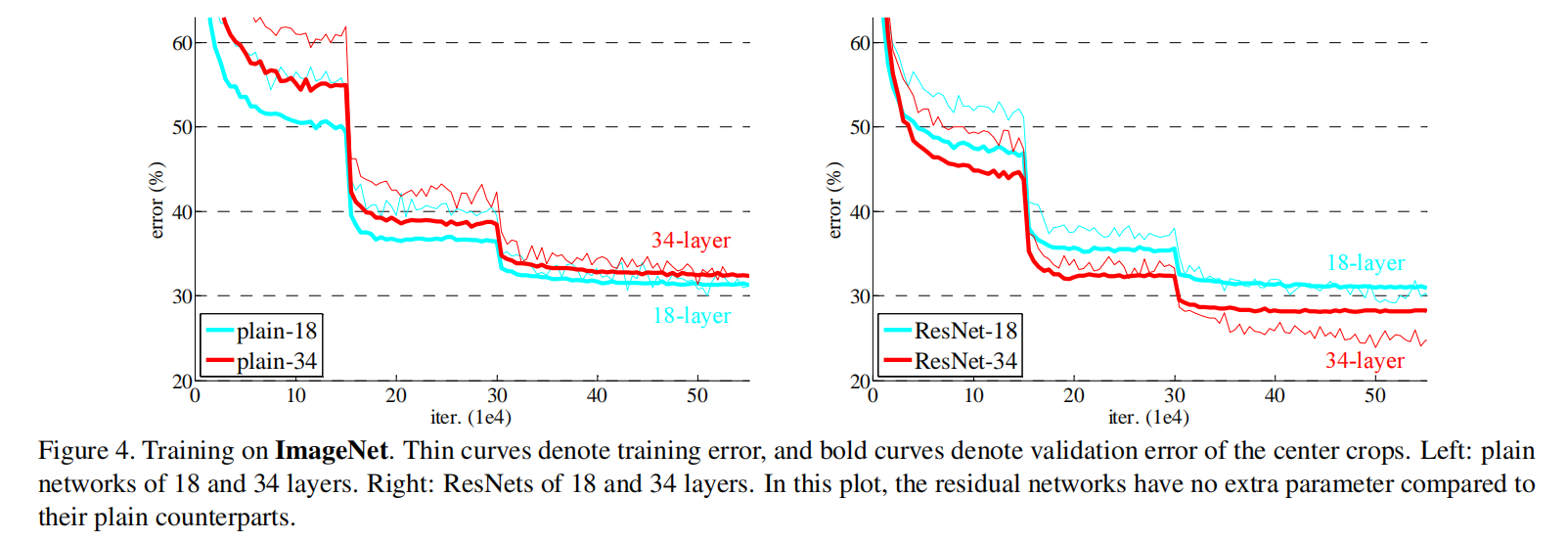
训练集和验证集的误差率结果如图4(左图)所示,VGG-34比VGG-18的误差率更高。因为BN的使用,不存在梯度消失的问题。所以这个问题就是网络退化
Res-18 vs. Res-34
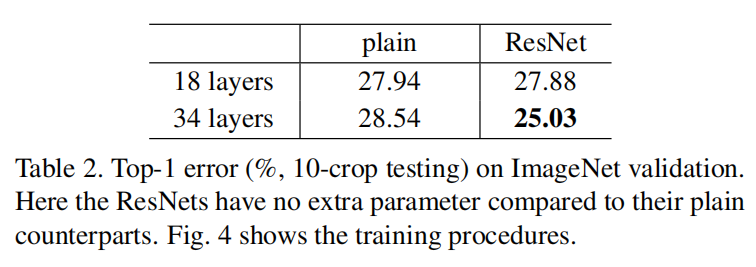
训练集和验证集的误差率结果如图4(右图)所示,测试集的误差率如表2所示
实验结果表明:
ResNet-34比ResNet-18有更低的误差率ResNet-34比VGG-18有更低的误差率
所以残差网络的深度增加能够有效的解决网络退化问题
Identity vs. Projection Shortcuts.
比较针对维度增加的3种实现:
- 方式
A:零填充快捷连接(zero-padding shortcuts):使用零填充,并没有增加参数 - 方式
B: 投影快捷连接(projection shortcuts):使用 - 方式
C:所有快捷连接(不管输入和输出维度是否相同)都使用投影方式
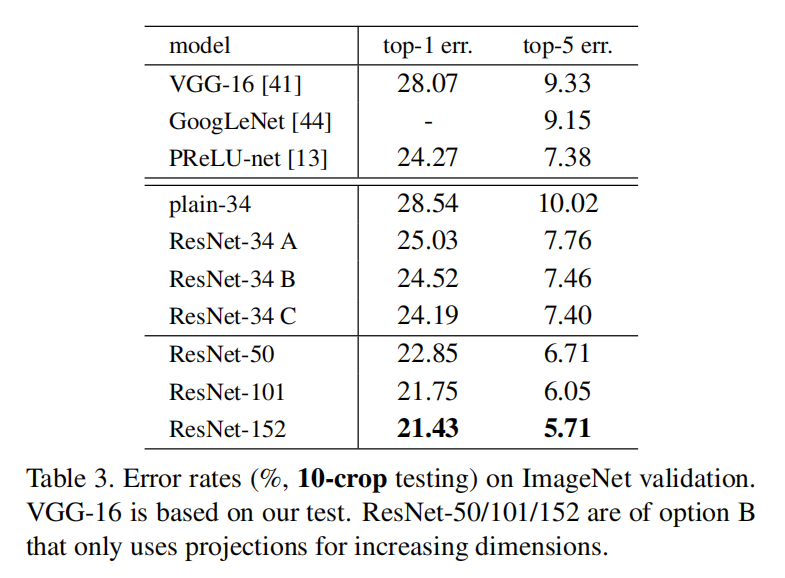
实验结果如表3所示:
A比B稍微差一些:这是由于零填充方式没有任何可学习参数B比C稍微差一些:因为C在残差学习中有更多的参数
A/B/C之间的微小差异表明投影快捷连接是不是解决退化问题的必要条件,所以在维度相同的情况下,使用一致性快捷连接( Identity shortcuts),在维度不同的情况下,使用投影快捷连接。这样能够最大程度的避免增加架构复杂度
Bottleneck
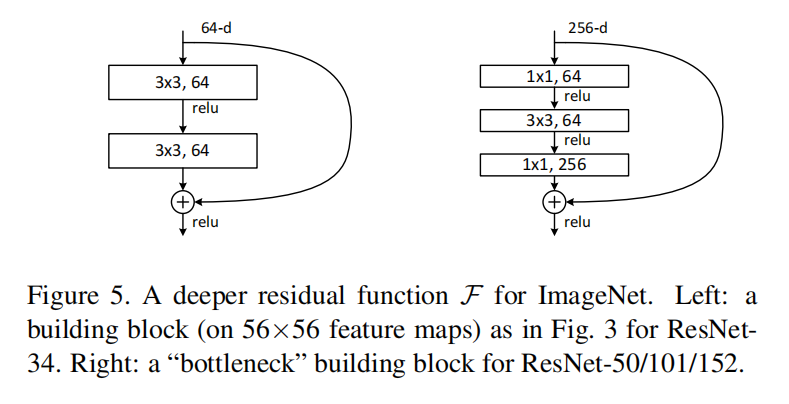
论文设计了一个3层网络的构建块,依次使用ResNet-50/101/152都使用3层构建块,具体网络实现参考Appendix B
Appendix A
Appendix B
未找到相关的 Issues 进行评论
请联系 @zjykzj 初始化创建