3rd Place Solution to Google Landmark Retrieval 2020
原文地址:3rd Place Solution to “Google Landmark Retrieval 2020”
摘要
Image retrieval is a fundamental problem in computer vision. This paper presents our 3rd place detailed solution to the Google Landmark Retrieval 2020 challenge. We focus on the exploration of data cleaning and models with metric learning. We use a data cleaning strategy based on embedding clustering. Besides, we employ a data augmentation method called Corner-Cutmix, which improves the model's ability to recognize multi-scale and occluded landmark images. We show in detail the ablation experiments and results of our method.
图像检索是计算机视觉中的一个基本问题。本文介绍了我们获得谷歌地标检索2020挑战赛第三名的详细解决方案。我们专注于探索数据清洗策略和基于度量学习的模型训练。我们使用了基于嵌入聚类的数据清洗策略,另外,我们采用了一种称为Corner-Cutmix的数据增强方法,提高了模型识别多尺度和遮挡地标图像的能力。我们详细展示了消融实验和我们方法的结果。
引言
论文参与了Google Landmark Retrieval 2020挑战赛。今年挑战赛的方式跟以往有所不同:不再是单独提交一个检索图像文件,而是提交一个模型来提取图像特征(还没有详细看过GLDv2 2020挑战赛的细节,应该之前的话是单独提交检索结果,现在是在评估服务器上直接进行检索)。新的提交方式导致无法使用后处理算法,比如DBA/QE/re-rank。所以论文专注于探索数据前处理以及模型训练。
论文实现方案基于2019年挑战赛第一名(Two-stage Discriminative Re-ranking for Large-scale Landmark Retrieval)的解决方案,新增了基于嵌入聚类的数据清洗策略。另外,论文还提出了一种新的数据增强方法 - Corner-Cutmix,并且使用了度量学习的训练方法。最后,论文还尝试了一系列主干网络。
方法
- 首先介绍数据清洗策略:利用
GLDv2 clean训练模型,然后通过聚类方式重新清洗GLDv2。 - 另外介绍
Corner-Cutmix进行数据增强实现; - 最后介绍模型架构选择以及训练策略。
数据清洗和增强
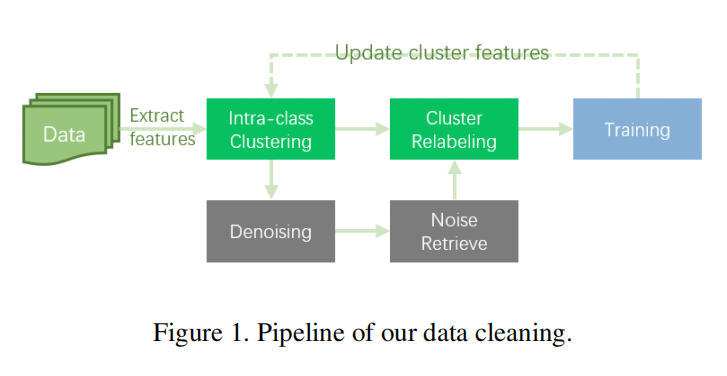
Data Cleaning with Embedding Cluster. GLDv2 2019挑战赛第一名解决方案针对数据进行清洗得到了GLDv2 clean数据集。作者认为这种清洗方法在减少噪声的同时大量消除了有效的数据和类别,所以论文设计了新的清洗策略:
- 利用
GLDv2 clean训练基准模型; - 利用基准模型为所有
GLDv2数据提取512维特征向量; - 对于每个类别数据,使用
DBSCAN进行类内聚类- 每个初始类别的数据都被划分为几个部分;
- 将每个聚类结果定义为一个新的类别;
- 针对噪声数据,使用阈值进行重聚类(这一步不太理解)。
上述聚类清洗得到了GLDv2 cluster,有2.8M张图片,大约210k个类别。基于GLDv2 cluster重新训练模型,能够得到一个更好性能的模型。此外,论文也指出重复上述清洗流程并不一定会提高数据质量,存在过拟合的风险。

Data Augmentation with Corner-Cutmix. 在GLDv2数据中,同一个地标建筑存在不同尺度和不同遮挡的图片。对此论文提出一种新的数据增强策略 - Corner-Cutmix。如下图3所示:

Corner-Cutmix将图像A覆盖到图像B的某一个角落,对于生成的混合图像,其标签为0.5A+0.5B。在训练过程中,使用双流网络架构来同时处理图像\(x_{A}\)和混合版本\(x_{A+B}\),如下图4所示:
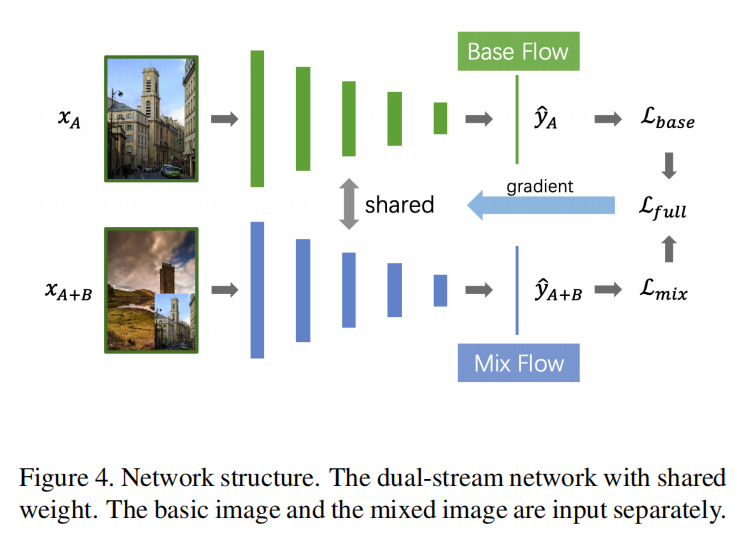
双流网路的输出分别是\(\tilde{y}_{A}\)和\(\tilde{y}_{A+B}\),其交叉熵损失分别为\(L_{base}\)和\(L_{mix}\)。其中\(L_{mix}\)计算如下:
\[ L_{mix}=0.5\times CE(\tilde{y}_{A+B}, y_{A})+0.5\times CE(\tilde{y}_{A+B}, y_{B}) \]
- \(CE(\cdot)\)指的是交叉熵损失。
模型以及训练
Backbone Network. 论文使用ResNest200和ResNet152作为最后的提交模型,使用了两阶段训练策略:首先使用GLDv2 clean进行训练,然后使用GLDv2 cluster进行微调。
针对模型架构,论文总结出以下结论:
- 在
ImageNet上有很好性能的模型架构,并不一定能够在图像检索任务上得到很好的性能; - 在相同推理时间约束的前提下,更深的网络通常比更宽的网络有更好的性能。
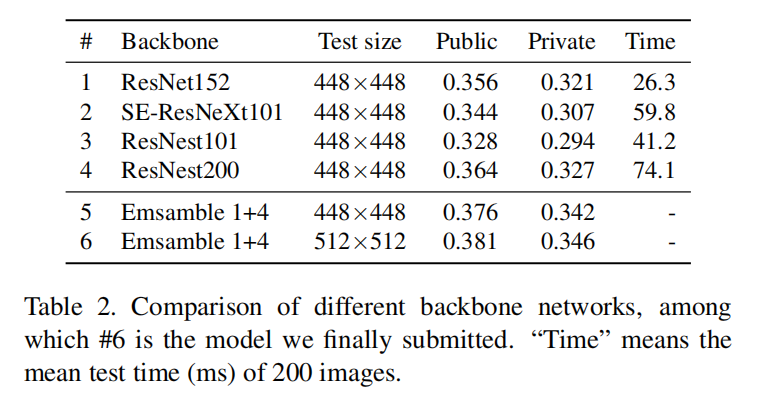
比如在检索任务中ResNet152比ResNest101/SE-ResNeXt101/Inception-v4这些包含了注意力模块、分组卷积或者Inception模块的性能更好,然而它在ImageNet的性能没有超过其他模型。论文也发现GeM(generalized mean-pooling)并没有很明显的性能增益,所以直接使用全局平均池化(global average pooling (GAP))
Dimensionality Reduction. 论文在GAP之后新增了一个\(1\times 1\)大小卷积层,将输出特征缩放到512维,最后执行L2归一化。
Loss Function. 在GLDv2 clean数据集上,使用普通的softmax loss来训练模型;在GLDv2 cluster数据集上,使用ArcFace loss(margin=0.3, scale=30)来进行微调。
Model Ensemble. 对于最后提交的版本,论文集成了两个模型(ResNet152和ResNest200)的特征,简单的连接它们得到1024维度特征。
实验
训练设置
- 训练框架:
Pytorch 1.1 GPU硬件:8 NVIDIA Tesla P40- 图像:缩放到
448x448 - 优化器:
SGD,初始学习率为0.01 - 学习率调度:
lambda poly - 轮数:在
GLDv2上训练24轮,在GLDv2 cluster上训练12轮。对于ResNet200,仅分别训练12轮和6轮。
消融研究

主干网络
小结
北邮联合微信一起参与的GLDv2 2020检索竞赛,取得了第三名的好成绩。因为GLDv2 2020的规则约束,所以没有实现非常复杂的后处理步骤,论文着重在数据清洗和增强,以及模型选择和训练上,整体架构如下:
- 基于
GLDv2 clean数据集训练基准模型,针对GLDv2数据集进行聚类清洗得到GLDv2 cluster; - 选择
ResNet152和ResNest200作为主干网络,- 调整网络架构,在
GAP输出后新增\(1\times 1\)卷积层,输出512维度特征,最后执行L2归一化; - 两阶段训练:先使用
GLDv2 clean数据集进行训练,再使用GLDv2 cluster数据集进行微调; - 结合
Corner-Cutmix以及双流网路架构进行训练,在GLDv2 clean上使用SoftmaxLoss,在GLDv2 cluster上使用ArcFace;
- 调整网络架构,在
- 完成训练后,集成两个模型输出特征得到
1024维度特征。