2nd Place and 2nd Place Solution to Kaggle Landmark Recognition and Retrieval Competition 2019
原文地址:2nd Place and 2nd Place Solution to Kaggle Landmark Recognition andRetrieval Competition 2019
官方实现:Research/CV/landmark
摘要
We present a retrieval based system for landmark retrieval and recognition challenge.There are five parts in retrieval competition system, including feature extraction and matching to get candidates queue; database augmentation and query extension searching; reranking from recognition results and local feature matching. In recognition challenge including: landmark and non-landmark recognition, multiple recognition results voting and reranking using combination of recognition and retrieval results. All of models trained and predicted by PaddlePaddle framework. Using our method, we achieved 2nd place in the Google Landmark Recognition 2019 and 2nd place in the Google Landmark Retrieval 2019 on kaggle. The source code is available at here.
我们提出了一个应用于地标检索和识别挑战的检索系统。应用于检索挑战的实现分为五个部分,包括特征提取和候选队列生成;数据库扩充和查询扩展搜索;以及根据识别结果和局部特征匹配进行重排序。应用于识别挑战的实现包括:地标和非地标识别、多个识别结果投票以及使用识别和检索结果的组合进行重排序。所有模型都由PaddlePaddle框架训练和预测。基于我们的实现,我们在kaggle上获得了2019年谷歌地标识别第二名和2019年谷歌地标检索第二名。源代码已开源。
引言
Google Landmark Dataset(GLD) V2是当前开源最大的图像检索和识别数据集,它包含了4M训练数据,超过10万张查询图像以及接近1M检索数据。
- 传统算法:结合不变的局部特征以及空间校验方法,比如基于词袋(
bag-of-words)的局部特征算法,类似的还有基于Fisher向量和VLAD生成紧凑的局部特征; - 深度学习:通过集成多个深度卷积网络生成的卷积特征来提升性能。论文使用了
ResNet152/ResNet200/SE ResNeXt152/InceptionV4,参考论文Bag of tricks for image classification with convolutional neural networks进行微调训练,在ImageNet验证数据集上的精度分别是80.61%/80.93%/81.45%/80.88%。
GLDv2分为分类竞赛和检索竞赛,论文探索了基于检索的算法在这两个竞赛上的表现。首先利用多个CNN模型中生成卷积特征,利用PCA进行维度衰减以及性能提升;然后通过最近邻搜索(NN Search)获取候选列表,输入到识别和局部特征匹配模块(这一部分需要后续学习);然后进行重排序,使用加权DBA和QE生成最终结果。针对识别竞赛,直接使用多分类模型进行打分,不使用PCA/DBA/QE。
检索方法
论文开发的检索系统如下图1所示:
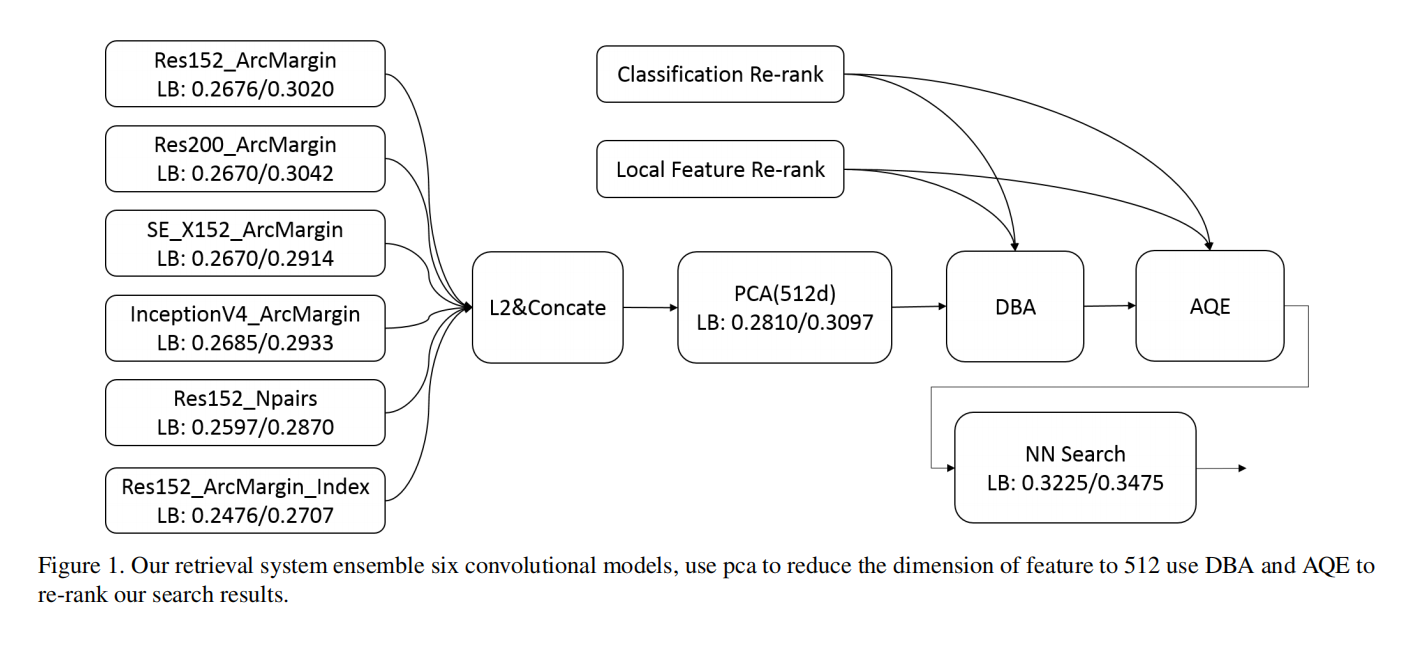
特征模型
全局特征
论文在GLDv2数据集上微调了4个卷积网络:ResNet152/ResNet200/SE ResNeXt152/InceptionV4。在训练过程中,论文使用ArcMargin损失(Arcface: Additive angular margin loss for deep face recognition)替代了Softmax损失。对于网络架构,论文移除了模型最后的全连接层,然后在最后的平均池化层之后增加了两个全连接层,第一个全连接层的输出维度是512,第二个是203094(相对应于训练数据集的类别数)。最后使用第一个全连接层输出特征作为全局描述符。在训练之前,论文没有针对数据进行任何清洗操作,微调训练阶段使用SGD优化器,另外输入大小设置为448。
论文还应用了度量学习损失函数,使用ResNet152+N-Pairs loss(Improved deep metric learning with multiclass n-pair loss objective)进行训练。类似于之前的设置,在平均池化层和分类层之间新增了一个全连接层,用于最后的特征提取。除了在GLDv2训练数据集上进行微调训练外,论文还针对检索数据集进行了聚类,得到了20w数据量接近4w个类别的数据集,使用ResNet152+ArcMargin loss进行微调训练。
在推理阶段,基于图像较短边等比缩放到448大小,然后输入到上述模型共得到6个全局描述符,进行归一化后连接在一起,使用PCA(基于检索数据集训练)进行维度衰减到512维。使用512维度特征描述符进行NN搜索以及后续操作。
注意一:所有基准模型均经过ImageNet1K数据集预训练
注意二:论文已开源了所有的度量学习训练:https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/metric_learning
局部特征

说的这个有些迷糊了,是跟CNN图像检索算法一起还是单独的局部特征检索???
识别模型
论文使用了全部数据(4094044张图像,共203094个类别)参与训练。主要的网络架构是ResNet152和InceptionV4,论文在ResNetC5之后增加了一个嵌入层,大小为256。另外论文使用了Label Smoothing方法,其平滑因子设置为0.1,0.2。
排序策略
对于数据端增强算法(database augmentation (DBA)),论文进行了部分优化,并不是简单加权融合数据库特征以及和它最相近的top-N条特征。首先,基于最近邻搜索得到最相近的前300条特征;然后基于分类模型和局部特征进行校验,从这300条特征中获取得到\(M\)条属于同一类别的特征;将这\(M\)条特征置于300条特征的前面,最后进行融合操作。其权重因子计算如下:
\[ N=\begin{cases} 10 & M\leq 10 \\ \min(M, 20) & M\gt 10 \end{cases} \]
\[ weights=\frac{N-x}{N}, 0 \leq x \lt N \]
也就是说,共融合前\(N\)条特征,每条特征的权重因子计算如上。对于查询扩展算法( query expansion (QE))采用同样的方式,差别在于权重因子和融合特征数目的计算:
\[ N=\begin{cases} 3 & M\leq 3 \\ \min(M, 6) & M\gt 3 \end{cases} \]
\[ weights=\frac{N-x}{N}, 0 \leq x \lt N \]
实验
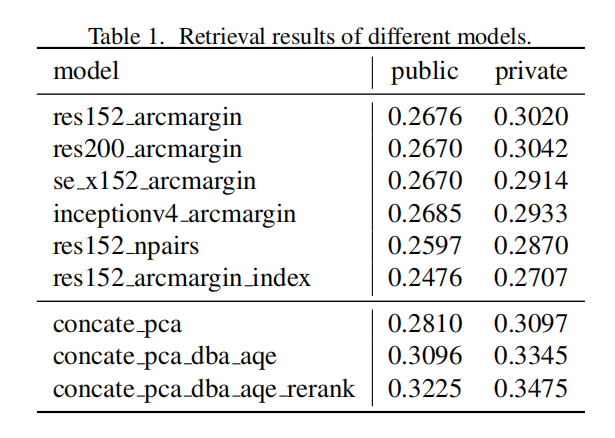
从实验结果来看,多特征集成以及DBA/QE确实能够提升性能,并且论文提出的优化策略能够进一步提升性能。
识别方法
使用检索模型进行分类
论文首先尝试了检索方式进行分类挑战。首先利用ResNet152模型提取训练和测试图像的全局特征;然后对于每张测试图像,在所有训练图像(4.13M)中进行最近邻搜索;从top-5候选列表中投票得到图像标签,选择该图像标签所属列表中最高的成绩作为该测试图像属于该标签的预测成绩。具体实现架构如下图3所示:

另外,论文还考虑到检索方式无法针对非坐标图像进行过滤,所以在很多测试图像的检索中非坐标的训练图像有可能会占据非常高的检索排名。整体GAP仅为private/public 0.10360/0.09455。示例结果如下图4所示:

使用目标检测器过滤非地标图像
论文使用目标检测器来过滤非地标图像,使用open images dataset v4数据集来训练Faster RCNN。该数据集包含了600个类别,共1743042张训练图像。论文使用ResNet50作为Backbone,训练得到mAP=0.5。
论文首先将600个类别划分为三个部分:
- 类别判定为地标:共
5个类别(Building/Tower/Castle/Sculpture/Skyscraper); - 类别不确定:共
7个类别(House/Tree/Palm tree/Watercraft/Aircraft/Swimming pool and Fountain); - 类别判定为非地标:剩余类别。
对于测试图像,如果存在至少一个目标属于地标类别列表,那么它被认定为地标图像;如果存在一个目标属于非地标类别列表,那么它被认定为候选非地标图像。另外,论文还针对非地标图像的判定增加了两条约束:
- 检测为非地标类别的预测成绩必须大于
0.3; - 检测为非地标类别的预测框占整幅图像的比例必须大于
0.6。
基于上述实现,使用目标检测器来过滤非地标图像。在120k的测试图像集中共过滤得到28k的非地标图像。另外,论文还是用这28k过滤图像作为检索集,重新检索120k测试图像。对于每张测试图像,如果top3的匹配成绩大于某一个阈值,那么就认定为非地标图像。基于上述操作,大约64k剩余测试图像被过滤。一共过滤了92k测试图像,GAP提升到private/public 0.30160/0.28335。
使用多模型进行重排序
因为GAP跟所有预测的排名有关,因此增加高可信度的地标分数有助于提高性能。论文设计了一套分级策略,使用了检索挑战用到的6个模型,另外新训练一个分类模型,使用ResNet152,训练数据大约3M张图像。这些数据来自于GLDv2的训练集,使用上述过滤方法去除了非地标图像。另外,使用了Label Smoothing方法,平滑因子设置为0.2。
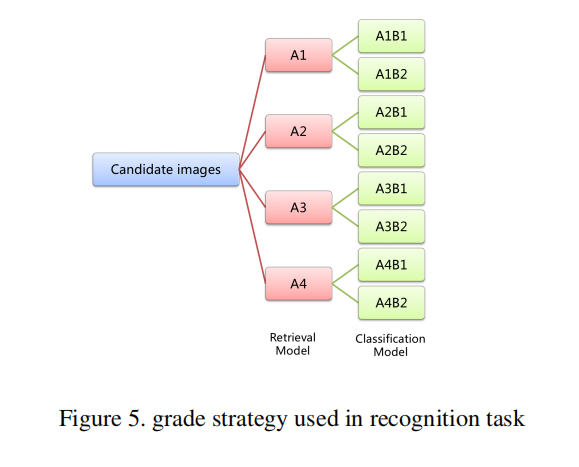
首先使用检索模型进行分级,获取top-5候选列表进行投票,数目最多的作为预测标签以及使用该标签最大的成绩作为预测成绩。如上图5所示。测试图像被划分为4个部分:
A1:top-5候选列表的标签数目不超过2个,另外最小预测标签(就是第5个)的成绩大于0.9;A2:类似于A1,标签数目不超过2个,另外最大的预测标签(就是top1)的成绩大于0.85;A3:不满足A1、A2和A4的情况;A4:top5候选列表的标签都不一样。
将测试图像划分为上述4个部分,然后基于A1>A2>A3>A4重新打分地标图像,GAP达到private/public 0.31340/0.29426。对于上述每个级别,使用分类模型再分为两级:
B1:使用检索模型和分类模型得到的成绩是一样的;B2:不满足B1的情况。
最终的分级制度为A1B1 > A1B2 > A2B1 > A2B2 > A3B1 > A3B2 > A4B1 > A4B2,GAP达到了private/public 0.32574/0.30839。后续论文还讨论了进一步优化的策略,不过我还没有看懂,所以。。。
小结
百度发布的一篇竞赛总结论文,论文写作方面相较于以往文章会更加粗粒度。使用了很多的实践策略,没有具体的理论解析但确实提升了最终成绩。初步看下来还不太适应,不论是写作风格还是具体操作,还需要多多研究源码。