PyRetri: A PyTorch-based Library for Unsupervised Image Retrieval by Deep Convolutional Neural Networks
原文地址:Aggregating Deep Convolutional Features for Image Retrieval
官方实现:PyRetri/PyRetri
摘要
Despite significant progress of applying deep learning methods to the field of content-based image retrieval, there has not been a software library that covers these methods in a unified manner. In order to fill this gap, we introduce PyRetri, an open source library for deep learning based unsupervised image retrieval. The library encapsulates the retrieval process in several stages and provides functionality that covers various prominent methods for each stage. The idea underlying its design is to provide a unified platform for deep learning based image retrieval research, with high usability and extensibility. To the best of our knowledge, this is the first open-source library for unsupervised image retrieval by deep learning.
尽管将深度学习方法应用于基于内容的图像检索领域已经取得了重大进展,但目前还没有一个软件库以统一的方式涵盖这些方法。为了填补这一空白,我们实现了PyRetri,这是一个基于深度学习的无监督图像检索开源库。该库将检索过程封装在几个阶段中,并为每个阶段提供了涵盖各种主要方法的实现。其设计思想是为基于深度学习的图像检索研究提供一个统一的平台,具有高度的可用性和可扩展性。据我们所知,这是第一个通过深度学习进行无监督图像检索的开源库。
引言
PyRetri是一个基于PyTorch的模块化Python库。论文主要贡献如下:
- 提出第一个基于深度学习的无监督图像检索开源框架,具备可读性以及可扩展性;
- 提供了高质量的
CBIR算法实现,强调可用性; - 发布了评估代码、模型库以及实例级别的图像检索工具。
概述
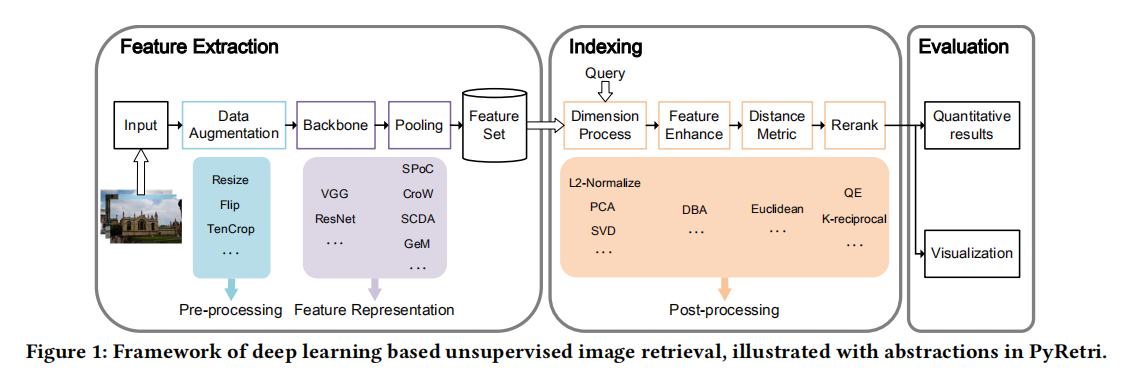
整体架构如上图所示,整体上划分为三个模块:
- 特征提取(
feature extraction); - 检索(
indexing); - 评估(
evaluation)。
评估模块
论文采用召回率(recall)和均值平均精度(mean average precision(mAP))作为评估标准:
- 召回率指的是检索得到的真值样本在整个检索库中的比例(
recall denotes the ratio of returned true matches to the total number or true matches in the database); mAP指的是所有查询的AP均值,也就是PR曲线下面积(mAP denotes the average of AP on all queries, which amounts area under the precision-recall curve)
方法
PyRetri支持了大量的用于图像检索的功能,划分为三个方面:
- 预处理算法
- 特征提取算法
- 后处理算法
预处理
DirectResize(DR):直接将图像缩放到指定大小;PadResize(PR):基于图像较长边等比缩放到目标大小,剩余的像素通过ImageNet均值进行填充;ShorterResize(SR): 基于图像较短边等比缩放到目标大小;TwoFlip(TF):返回原始图像以及相应的水平翻转的结果;CenterCrop(CC):基于指定大小,裁剪图像中央区域;TenCrop(TC):裁剪原始图像以及翻转图像,分别裁剪上、下、左、右、中五个区域。
上述这些操作大都是评估阶段所需实现
特征提取
GAP:全局平均池化;GMP:全局最大池化;R-MAC:基于区域最大激活计算特征向量;SPoC:全局求和池化,同时可以在中央区域赋值更大权重;CroW:基于空间和通道维度执行加权求和池化;SCDA: Keeping useful deep descriptors based on the summation of feature map activations;GeM:广义平均池化;PWA: Aggregating the regional representations weighted by the selected part detectors’output;PCB:Outputting a convolutional descriptor consisting of several part-level features。
后处理
SVD:通过奇异值分解方式减少特征维度;PCA:通过主成分分析方式减少特征维度;DBA:数据库中每个特征与其他特征进行k近邻搜索,选择前topK个候选特征结合该特征进行加权求和,参与查询特征计算;QE:结合查询特征与检索得到的前topK个数据库特征,再次进行检索;k-reciprocal:Encoding k-reciprocal nearest neighbors to enhance the accuracy of retrieval.
实验
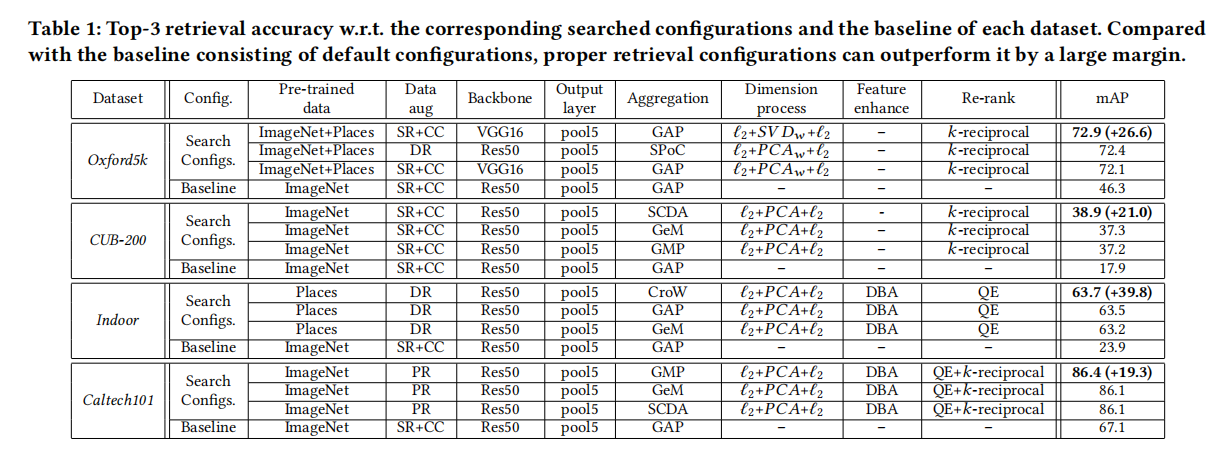
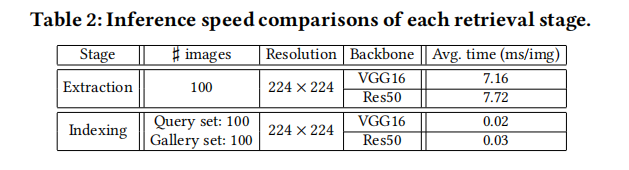
小结
PyRetri以一个统一的架构实现了图像检索任务所需的评估实现,提供了非常多个基准功能,涵盖了预处理、特征提取以及后处理阶段,非常值得研究和深入学习。下面说说自己觉得不足的地方:
- 并没有提供训练相关实现,而这一块是自
2018年以来图像检索任务取得进步的非常重要的领域; - 自从
2020年发布之后就不再进行维护,确实很遗憾,在一些操作和使用上没有继续进行优化; - 看了一部分代码,对于数据的保存和操作结构并没有进行很好的解释,会额外提高理解难度;
另外,我发现PyRetri实现的评估标准更像是信息检索领域的实现方式,而很多数据集评估和论文评估中采用了不一样的方式。就召回率来说,度量学习的召回率计算是被更多论文所采用的:
Recall(metric learning):前topK位检索标签列表中是否出现了真值标签,是就是1, 否则就是0。参考[图像检索]Recall@K
对于mAP而言,如果仅仅是所有查询的AP均值,那么跟召回率没有关系,也就不再是PR曲线下面积的计算了。对此Oxford5k数据集提供了PR曲线下面积的mAP计算实现:[图像检索]准确率、查准率/精确度、查全率/召回率、AP/mAP