Selective Kernel Networks
原文地址:Selective Kernel Networks
官方解读:SKNet——SENet孪生兄弟篇
自定义实现:ZJCV/ZCls
摘要
In standard Convolutional Neural Networks (CNNs), the receptive fields of artificial neurons in each layer are designed to share the same size. It is well-known in the neuroscience community that the receptive field size of visual cortical neurons are modulated by the stimulus, which has been rarely considered in constructing CNNs. We propose a dynamic selection mechanism in CNNs that allows each neuron to adaptively adjust its receptive field size based on multiple scales of input information. A building block called Selective Kernel (SK) unit is designed, in which multiple branches with different kernel sizes are fused using softmax attention that is guided by the information in these branches. Different attentions on these branches yield different sizes of the effective receptive fields of neurons in the fusion layer. Multiple SK units are stacked to a deep network termed Selective Kernel Networks (SKNets). On the ImageNet and CIFAR benchmarks, we empirically show that SKNet outperforms the existing state-of-the-art architectures with lower model complexity. Detailed analyses show that the neurons in SKNet can capture target objects with different scales, which verifies the capability of neurons for adaptively adjusting their receptive field sizes according to the input. The code and models are available at this https URL.
在标准卷积神经网络(CNNs)中,每层人工神经元的感受野大小相同。但是在神经科学中,视觉皮层神经元的感受野大小受刺激的调节,这个属性在构建神经网络时很少被考虑到。我们提出一种动态选择机制,允许每个神经元基于多尺度的输入信息自适应地调整其感受野大小。我们设计了一种构造块(称为选择性内核单元SKUnit),其拥有多个分支(每个分支的内核大小不同),最后通过softmax注意力进行信息融合。不同分支上各自的的关注力在融合层产生不同大小的神经元有效感受野。堆叠多个SKUnit得到最终的深度网络,称为选择性核心网络(SKNet)。在ImageNet和CIFAR基准测试中,通过实验证明,SKNet在模型复杂性较低的情况下优于现有最好的架构。详细分析表明,SKNet中的神经元可以捕捉不同尺度的目标对象,验证了神经元根据输入自适应调整感受野大小的能力。开源地址:https://github.com/implus/SKNet
解读
关于大小
我一开始理解的大小(size)指的是卷积核的长宽,也就是
个人看法:标准卷积的计算方式同样拥有随刺激分配权重的能力,不过相对而言其操作比较粗粒度,而SKUnit通过多分支卷积+注意力机制的实现方式表现的的更加细粒度,从实现结果来看其提取特征的能力也比较好
关于整体架构
单个标准卷积拥有固定长宽的感受野,比如VGG-style)设计的模型的泛化能力有限,后续模型的发展有两个方向:
InceptionNet通过多分支(不同大小的感受野)方式来提取多尺度空间信息;ResNet通过残差连接的方式来提取多尺度空间信息。
对于SKNet而言,其相当于结合了多分支连接+残差连接+注意力机制,并且通过实验证明其能够有效的提取数据信息
另外,从作者博文中提到,在ResNet和ResNeXt的对比过程中,分组卷积的实现一方面极大的降低了计算量;另一方面通过多分支(相同感受野大小的滤波器)的嵌入组合,能够进一步提高分类性能(侧面证明了多分支方式的有效性)
SKUnit
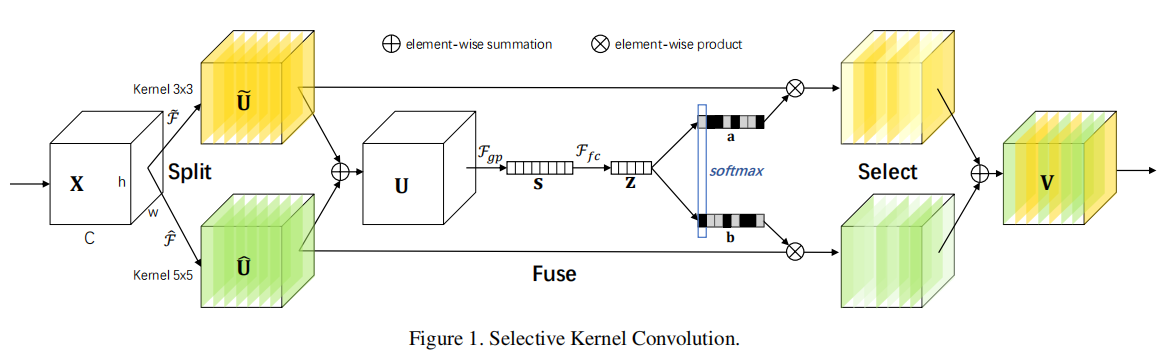
SKUnit(Selective Kernel Unit)可分为3步操作:分离(split)、融合(fuse)和选择(select)
split
分离操作指的是通过多分支卷积提取多尺度空间信息,当前默认为两个分支:
- 假定输入特征图大小为
- 执行两个分支不同大小卷积(卷积核大小分别为
其中
- 使用分组或者深度卷积进行特征提取;
- 在卷积层之后添加归一化层
BN和非线性激活函数ReLU dilation=2)进行替代
fuse
融合操作为了使得神经元能够自适应调整感受野大小:
- 首先执行多分支加法融合:
- 使用全局平均池化来嵌入全局信息:
select
最后使用soft注意力机制执行跨通道自适应调整空间尺度信息,其计算公式如下:
其中
通过soft注意力机制,可以保证
其中
超参数
SKUnit包含3个超参数:
- 分支数
- 分组数
- 缩放率
通常设置为
SKNet
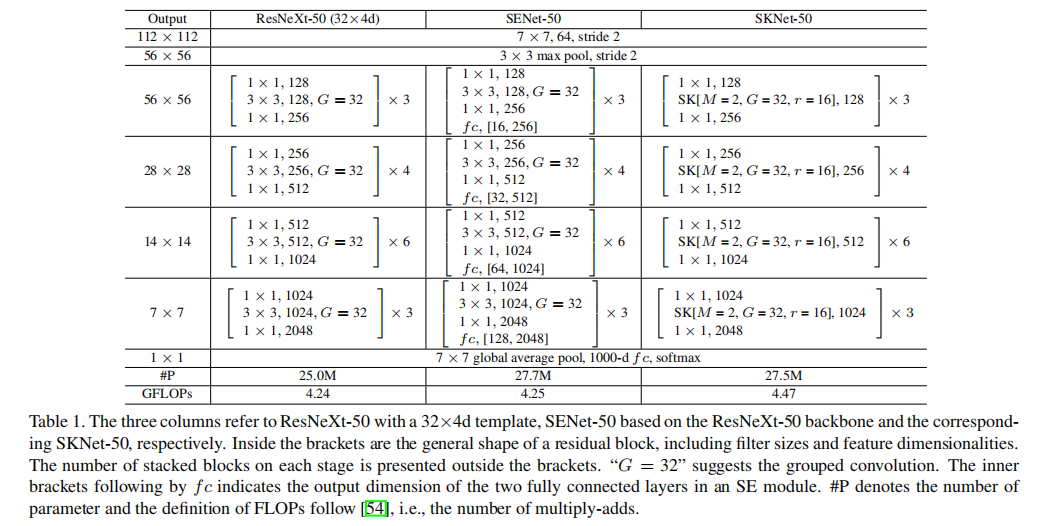
使用SKUnit替代ResNeXt中Bottleneck块中的SKNet
具体架构
论文参考了ResNeXt的设计架构,共实现了3种不同:
SKNet-50:4个阶段的块个数为[3, 4, 6, 3];SKNet-26:4个阶段的块个数为[2, 2, 2, 2];SKNet-101:4个阶段的块个数为[3, 4, 23, 3]。
模型大小 vs. 时间 vs. 分类性能
ImageNet评估
训练过程设置如下:
- 数据增强:
- 随机裁剪
- 随机水平翻转;
- 逐通道减去均值;
- 随机裁剪
- 损失函数:标签平滑正则化损失;
- 优化器:使用动量为
0.9的同步SGD; - 批量大小:
256; - 学习率/权重衰减:
0.1/1e-4; - 学习率调度:每
30轮衰减一次,衰减因子为0.1; GPU个数:8;- 训练论数:
100
上述设置用于训练大的模型,对于小模型,使用4e-5大小的权重衰减,同时减少数据增强尺度。训练结果如下:
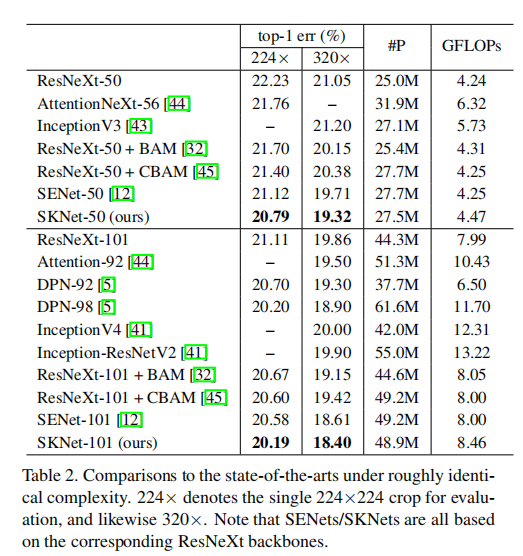
SKNet vs. ResNeXt
比较SKUnit和不同深度/宽度/基数的ResNeXt,结果如下:
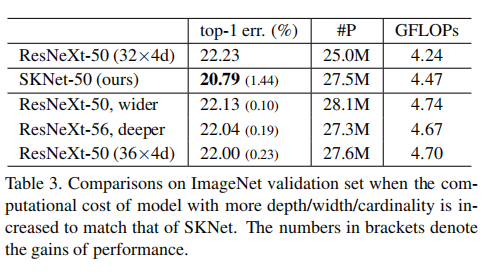
通过提高深度(ResNeXt-50 -> ResNeXt-53)、宽度(ResNeXt-50 -> ResNeXt-53 wider)、基数(ResNeXt-50(32x4d) -> ResNeXt-50(36x4d))使得ResNeXt拥有和SKNet-50有相近的GFLOPs。从实验结果看,SKNet仍旧拥有更好的性能
SKUnit vs. SEUnit
在ShuffleNetV2上分别嵌入SKUnit和SEUnit,从实验结果发现SKUnit拥有更强的泛化能力
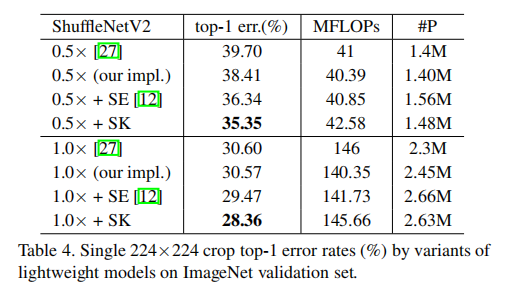
+SE表示嵌入SE模块到每个shuffle层之后;+SK表示替代原先的M=2(表示使用K3和K5双路卷积)、r=4以及和之前相同的分组数G
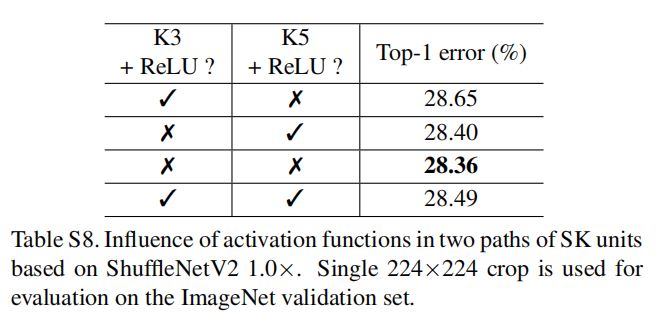
在ShuffleNetV2的ReLU激活函数,论文同样实践了最佳的ShuffleNetV2+SKUnit方式,发现在SKUnit每路卷积之后同样不执行ReLU激活函数的效果最好
消融实验
论文针对不同目标大小以及不同深度的模型架构进行了消融实验,从消融实验中观察到两个现象:
- 当输入目标变大的时候,中层的
SKUnit会提取更多 - 更高层的
SKUnit(比如从SK_3_4 -> SK_5_3)不再会根据目标大小变化变现出感受野变化,这表明高层卷积已经将尺度信息编码在特征向量中,与较低层的情况相比,内核大小不太重要
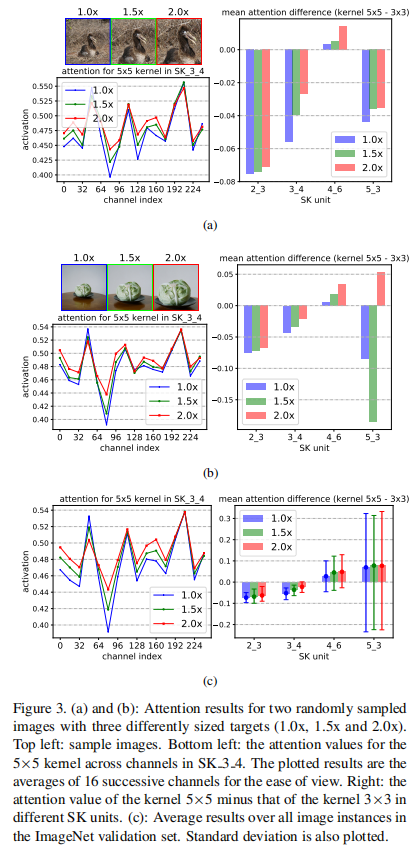
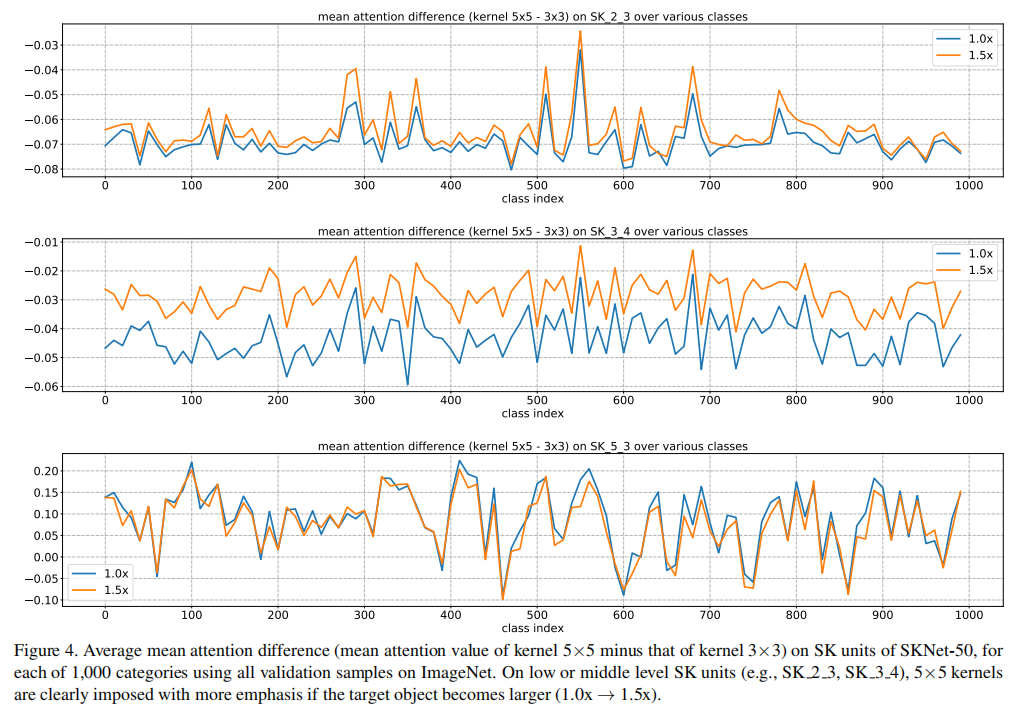
我没看懂这两张图???
Gitalk 加载中 ...