ResNeSt: Split-Attention Networks
原文地址:ResNeSt: Split-Attention Networks
自定义实现:ZJCV/ZCls
摘要
1 | It is well known that featuremap attention and multi-path representation are important for visual |
众所周知,特征图注意和多路径表示对视觉识别很重要。在本文中,我们提出了一个模块化的体系结构,它将通道方向的注意力应用于不同的网络分支,以利用它们在捕获跨特征交互和学习不同表示方面的成功。我们的设计产生了一个简单统一的计算块,只需使用几个变量就可以将其参数化。我们的模型名为ResNeSt,在图像分类的准确性和延迟权衡方面优于EfficientNet。此外,ResNeSt在几个基准测试中取得了优异的迁移学习成绩,并被COCO-LVIS挑战赛的获奖作品所采用。完整系统和预训练模型的源代码已开源
解读
在SKNet中,使用了两路分支(soft注意力机制缩放跨通道特征。ResNeSt首先参数化了SKUnit的实现,同时进一步发展了特征提取的细粒度实现,并不只是简单的扩充分支数,而是将输入的特征图进行分组,针对每组特征图执行多分支特征提取以及soft注意力机制进行特征重分配,最后将每组特征图串联成输出数据。简单的说,SKNet针对上一层的特征数据进行了多尺度特征提取+注意力机制,而ResNeSt先对上一层的特征数据进行分组,对每组数据单独执行多分支特征提取+注意力机制,最后通过串联的方式输出特征数据。从实验效果来看取得了更好的成绩
文章中共设计了不同视角下ResNeSt计算块的布局方式:
- 基于基数组(
cardinal groups)视角 - 基于分离组(
radix groups)视角
其中基数组视角遵循从外到内的思路,能够帮助理解ResNeSt计算块的实现以及和之前模型的比较;而基于分离组视角的布局遵循从内到外的思路,能够利用CNN算子实现方式,有助于实际编程实现
cardinality-major implementation
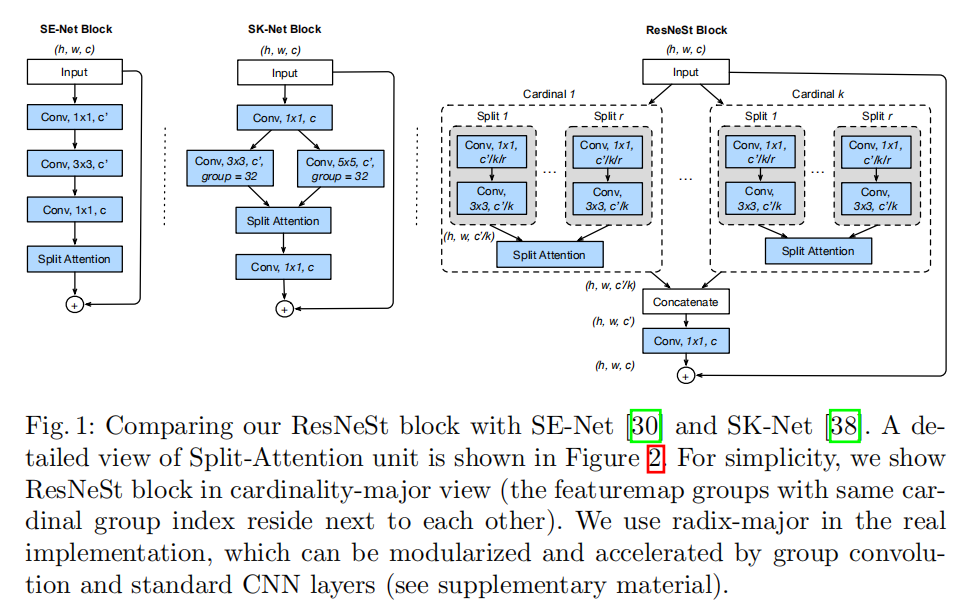
基数组视角的布局如上图所示,在ResNeSt Block实现中,首先对输入特征进行分组,然后输入到各个Split-Attention Block中进行计算,完成后将各个分组特征串联在一起。
其中ReLU激活函数)
详细说明如下
Split-Attention Block
论文设计了一个基本计算单元:Split-Attention Block,用于对输入特征进行不同特征提取+跨通道特征融合。可为两步操作:
- 特征图分组(
feature-map group); - 注意力分离(
split attention)。
特征图分组
- 在
ResNeXt中,上层输入特征cardinal groups),其大小为 - 在
ResNeSt中,对每个基数组特征基于通道维度分成了radix groups),其大小为 - 完整的分组数为
- 对每个分离组特征执行各自的转换操作:
注意力分离
单个基数组中各个分离组的多分支特征提取+soft注意力重分配的实现如下图所示:
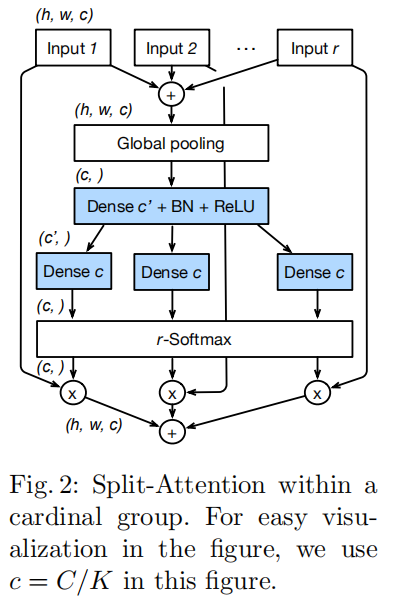
- 对同一基数组中的不同分离组进行逐元素加法,以获取跨通道信息,第
- 通过全局平均池化方式获取全局上下文信息,输出大小为
- 第
ResNeSt Block
Split-Attention Block输入特征图大小为
完成串联后,执行残差连接:
SENet vs. SKNet vs. ResNeSt
ResNeSt统一了SENet和SKNet的架构实现:
- 当
radix=1时,Split-Attention Block退化为对每个基数组执行Squeeze-And-Excitation操作; - 当
radix=2时,Split Attention Block在各个基数组中执行了一个类似SKUnit的多分支特征提取+soft注意力
radix-major implementation
为了更易于编码实现,文章在附录中给出了分离组视角(radix-major view),如下图所示
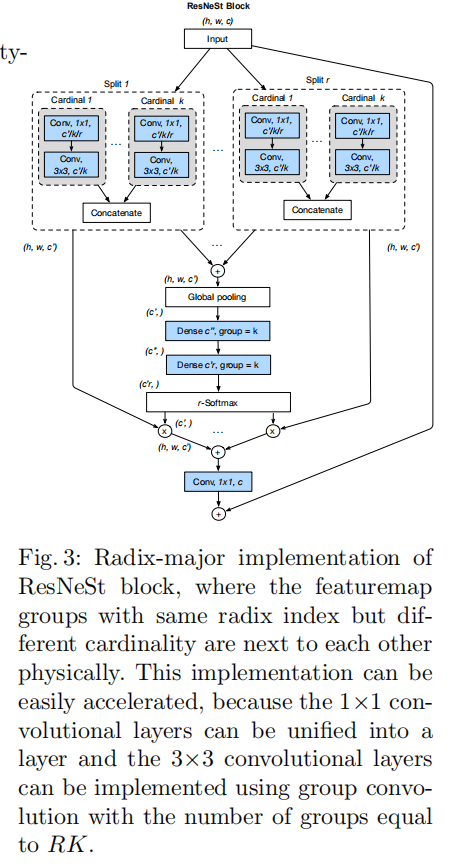
- 输入特征图首先分离为
- 将相同分离组下标的分组数据排列在一起并执行串联操作;然后不同分离组下标的分组数据进行求和操作,这相当于同一基数组中各个分离组数据的求和,从而完成同一基数组中全局上下文的信息融合
- 对求和后的串联数据执行全局池化操作,这相当于执行跨通道的信息融合;
- 在池化层之后使用两个全连接层(分组数为
- 最后使用
softmax函数计算各个基数组不同分离组中各个通道的权重分配
tricks
平均下采样
在ResNet Bottleneck实现中:
- 最开始在第一个
- 之后优化为在中间
- 在
ResNeSt中,通过在
ResNet-D
使用ResNet-D代替ResNet作为ResNeSt的基础模型,其改变有:
- 使用3个
- 对于一致性连接,如果需要执行下采样,那么在
训练策略
GPU个数:64(共8台服务器)- 学习率调度策略:
warm up(前5轮)+cosine schedule - 初始学习率:
zero_init_residual_block:设置每个block最后一个- 损失函数:标签平滑损失函数
- 数据增强:自动数据增强策略+随机大小裁剪++随机水平翻转+颜色抖动+亮度改变
- 训练加速:
mixup - 裁剪大小:
EfficientNet证明了越深越宽的网络需要增加输入图像大小,所以- 对于
ResNet变体,执行224大小裁剪; - 对于其他网络,执行
256大小裁剪。
- 对于
- 正则化:
- 在最后一个全连接层之前执行
- 仅对对于卷积层以及全连接层权重执行权重衰减
- 在最后一个全连接层之前执行
- 权重初始化:
Kaiming初始化 - 权重衰减:
1e-4 - 动量大小:
0.9
测试策略
- 首先将图像缩放到裁剪大小的
1/0.875; - 执行中央裁剪
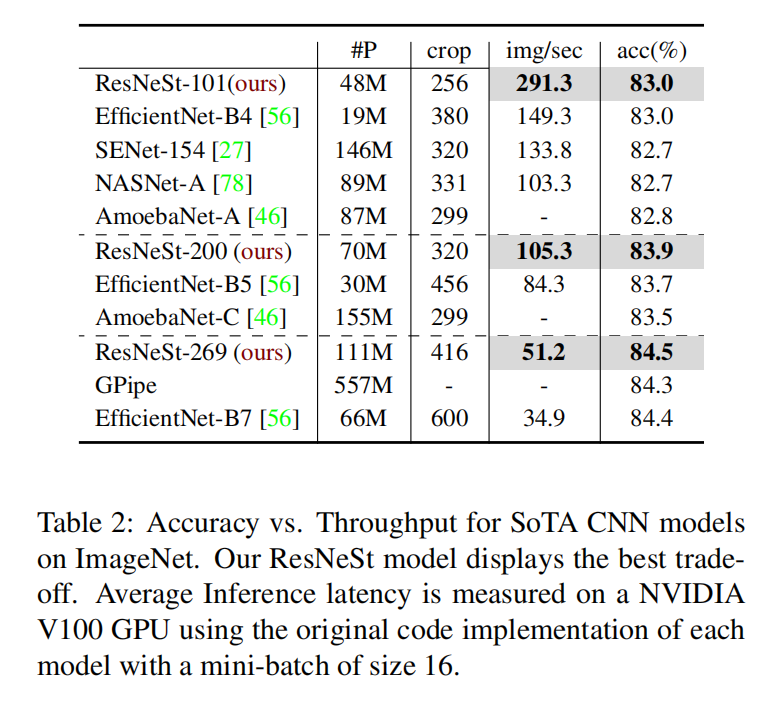
分类测试
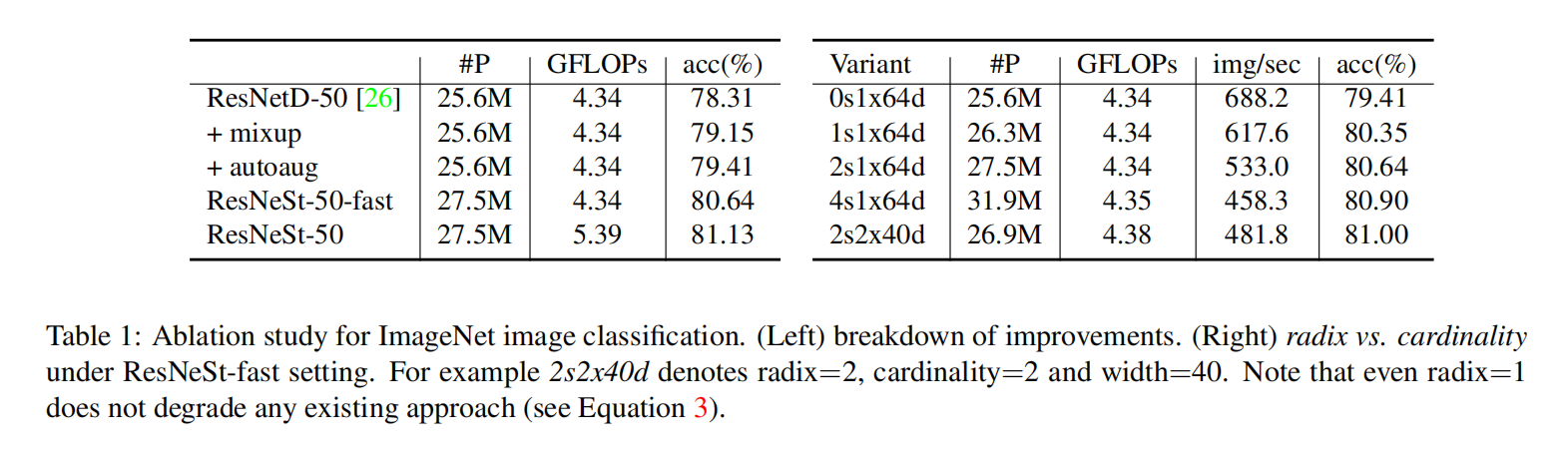
radixcardinality
Gitalk 加载中 ...