k-means聚类算法
分类 vs. 聚类
分类:类别是已知的,通过对已知分类的数据进行训练和学习,找到这些不同类别的特征,再对未分类的数据进行分类。属于有监督学习(有标签) 聚类:事先不知道数据会分为几类,通过聚类分析将数据聚合成几个群体。聚类不需要对数据进行训练和学习。属于无监督学习(无标签)
k-means聚类
定义
k-means聚类算法通过计算距离作为相似度来衡量两个对象是否属于同一簇。其算法如下:
- 随机选取\(k\)个对象作为初始聚类中心
- 计算所有对象和这\(k\)个聚类中心的距离(欧式距离),将其分配给距离最近的聚类中心
- 完成所有对象的分配后,重新计算这\(k\)个聚类的中心,重复第2步
- 终止条件:
- 没有(或最小数目)对象被重新分配给不同的聚类
- 没有(或最小数目)聚类中心发生变化
- 误差平方和局部最小
具体实现过程中,需要注意以下几点:
- \(k\)是超参数,表明了本次实现要计算的类别数
- 通过计算\(k\)个聚类的均值来重新确定聚类中心。注意:此时的聚类中心可能就不是某一个对象了
实现
百度百科给出了很好的实现范例:
1 | class KMeansClusterer: |
距离计算
k-means聚类算法通过欧式距离来衡量对象和聚类中心的相似度。对于多属性的对象而言,选择哪些属性参与距离计算也是一个很好的优化方法
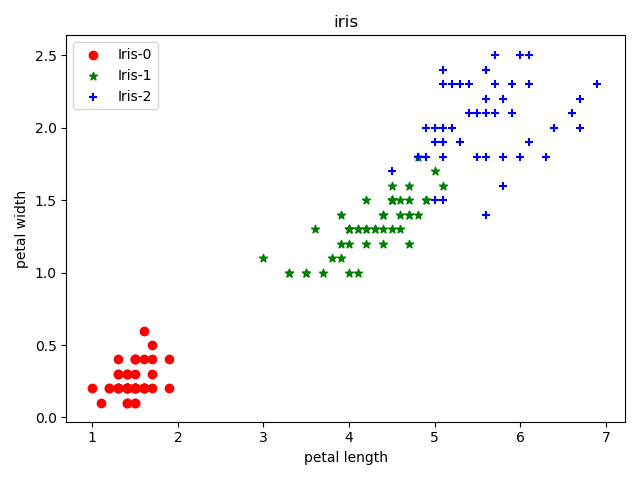
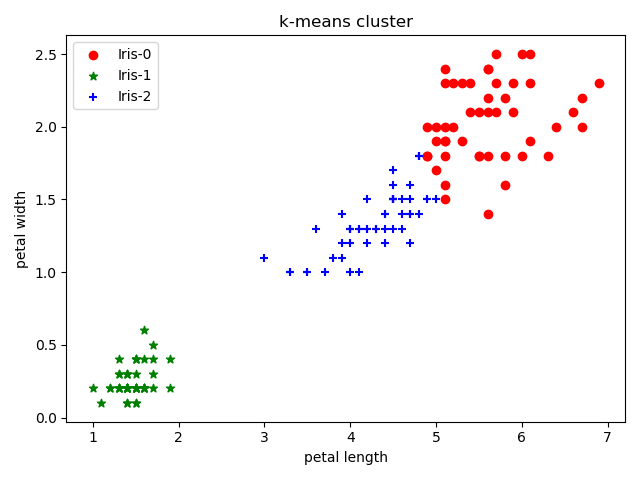
示例:iris分类
使用k-means聚类算法分类iris数据集
数据集定义
iris数据集包含了4个属性,分别表示(单位cm):
- 萼片(
sepal)长度 - 萼片宽度
- 花瓣(
petal)长度 - 花瓣宽度
每个类别有50个实例,整个数据集共150个
sklearn实现
sklearn提供了k-means算法,实现iris聚类
1 | from sklearn import datasets |
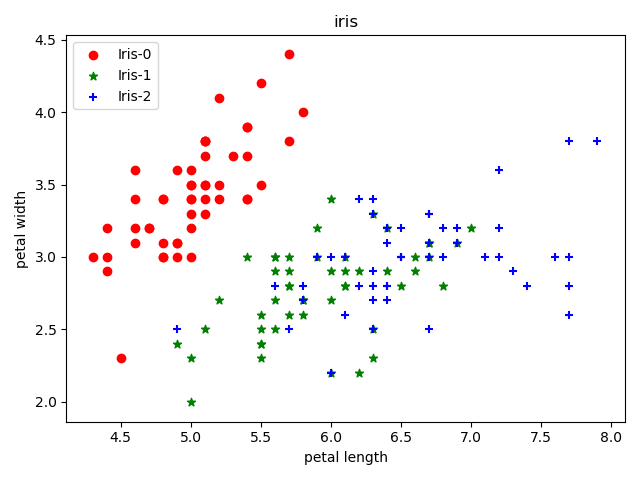
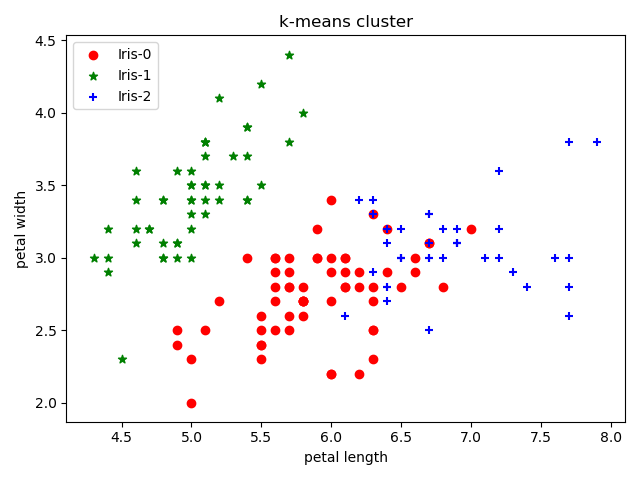
上述结果使用了iris的4个属性进行聚类下面仅使用后两个属性进行聚类
1 | if __name__ == '__main__': |