1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
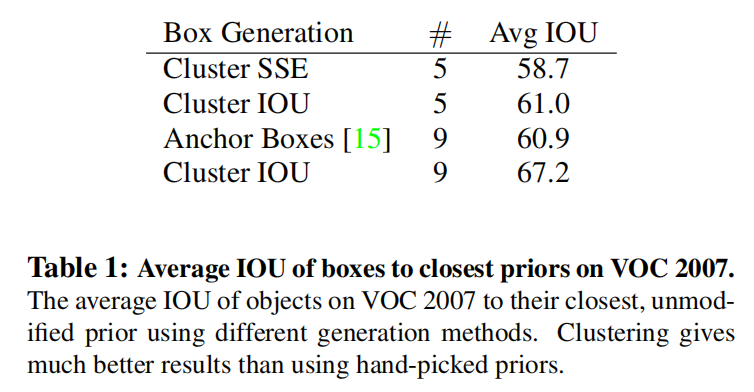
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
|
import numpy as np
def iou(box, clusters):
"""
Calculates the Intersection over Union (IoU) between a box and k clusters.
:param box: tuple or array, shifted to the origin (i. e. width and height)
:param clusters: numpy array of shape (k, 2) where k is the number of clusters
:return: numpy array of shape (k, 0) where k is the number of clusters
"""
x = np.minimum(clusters[:, 0], box[0])
y = np.minimum(clusters[:, 1], box[1])
if np.count_nonzero(x == 0) > 0 or np.count_nonzero(y == 0) > 0:
raise ValueError("Box has no area")
intersection = x * y
box_area = box[0] * box[1]
cluster_area = clusters[:, 0] * clusters[:, 1]
iou_ = intersection / (box_area + cluster_area - intersection)
return iou_
def avg_iou(boxes, clusters):
"""
Calculates the average Intersection over Union (IoU) between a numpy array of boxes and k clusters.
:param boxes: numpy array of shape (r, 2), where r is the number of rows
:param clusters: numpy array of shape (k, 2) where k is the number of clusters
:return: average IoU as a single float
"""
return np.mean([np.max(iou(boxes[i], clusters)) for i in range(boxes.shape[0])])
def translate_boxes(boxes):
"""
Translates all the boxes to the origin.
:param boxes: numpy array of shape (r, 4)
:return: numpy array of shape (r, 2)
"""
new_boxes = boxes.copy()
for row in range(new_boxes.shape[0]):
new_boxes[row][2] = np.abs(new_boxes[row][2] - new_boxes[row][0])
new_boxes[row][3] = np.abs(new_boxes[row][3] - new_boxes[row][1])
return np.delete(new_boxes, [0, 1], axis=1)
def kmeans(boxes, k, dist=np.median):
"""
Calculates k-means clustering with the Intersection over Union (IoU) metric.
:param boxes: numpy array of shape (r, 2), where r is the number of rows
:param k: number of clusters
:param dist: distance function
:return: numpy array of shape (k, 2)
"""
rows = boxes.shape[0]
distances = np.empty((rows, k))
last_clusters = np.zeros((rows,))
np.random.seed()
clusters = boxes[np.random.choice(rows, k, replace=False)]
while True:
for row in range(rows):
distances[row] = 1 - iou(boxes[row], clusters)
nearest_clusters = np.argmin(distances, axis=1)
if (last_clusters == nearest_clusters).all():
break
for cluster in range(k):
clusters[cluster] = dist(boxes[nearest_clusters == cluster], axis=0)
last_clusters = nearest_clusters
return clusters
import glob
import xml.etree.ElementTree as ET
import numpy as np
from kmeans import kmeans, avg_iou
ANNOTATIONS_PATH = "Annotations"
CLUSTERS = 5
def load_dataset(path):
dataset = []
for xml_file in glob.glob("{}/*xml".format(path)):
tree = ET.parse(xml_file)
height = int(tree.findtext("./size/height"))
width = int(tree.findtext("./size/width"))
for obj in tree.iter("object"):
xmin = int(obj.findtext("bndbox/xmin")) / width
ymin = int(obj.findtext("bndbox/ymin")) / height
xmax = int(obj.findtext("bndbox/xmax")) / width
ymax = int(obj.findtext("bndbox/ymax")) / height
dataset.append([xmax - xmin, ymax - ymin])
return np.array(dataset)
data = load_dataset(ANNOTATIONS_PATH)
out = kmeans(data, k=CLUSTERS)
print("Accuracy: {:.2f}%".format(avg_iou(data, out) * 100))
print("Boxes:\n {}".format(out))
ratios = np.around(out[:, 0] / out[:, 1], decimals=2).tolist()
print("Ratios:\n {}".format(sorted(ratios)))
|
未找到相关的 Issues 进行评论
请联系 @zjykzj 初始化创建