神经网络推导-批量数据
输入批量数据到神经网络,进行前向传播和反向传播的推导
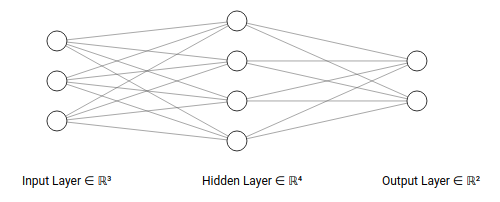
TestNet网络
TestNet是一个2层神经网络,结构如下:
- 输入层有
3个神经元 - 隐藏层有
4个神经元 - 输出层有
2个神经元
- 激活函数为
relu函数 - 评分函数为
softmax回归 - 代价函数为交叉熵损失
网络符号定义
规范神经网络的计算符号
关于神经元和层数
0层,隐藏层是第1层,输出层是第2层
342
关于权重矩阵和偏置值
关于神经元输入向量和输出向量
关于神经元激活函数
关于评分函数和损失函数
神经元执行步骤
神经元操作分为2步计算:
- 输入向量
- 输出向量
网络结构
对输入层
对隐藏层
对输出层
评分值
损失值
前向传播
输入层到隐藏层计算
隐藏层输入向量到输出向量
隐藏层到输出层计算
评分操作
损失值
反向传播
计算输出层输入向量梯度
计算输出层权重向量梯度
计算隐藏层输出向量梯度
计算隐藏层输入向量的梯度
计算隐藏层权重向量的梯度
小结
TestNet网络的前向操作如下:
反向传播如下:
假设批量数据大小为
参考反向传导算法和神经网络反向传播的数学原理,设每层输入向量为残差
前向传播执行步骤
层与层之间的操作就是输出向量和权值矩阵的加权求和以及对输入向量的函数激活(以relu为例)
输出层输出结果后,进行评分函数的计算,得到最终的计算结果(以softmax分类为例)
损失函数根据计算结果判断最终损失值(以交叉熵损失为例)
反向传播执行步骤
计算损失函数对于输出层输入向量的梯度(最终层残差)
计算中间隐藏层的残差值(
完成所有的可学习参数(权值矩阵和偏置向量)的梯度计算
更新权值矩阵和偏置向量
未找到相关的 Issues 进行评论
请联系 @zjykzj 初始化创建