神经网络推导-单个数据
输入单个数据到神经网络,进行前向传播和反向传播的推导
预备知识
- 链式法则
- 雅可比矩阵
链式法则
反向传播(backpropagatation)的目的是进行可学习参数(learnable parameters)的更新,其实现方式是利用链式法则(chain rule)进行梯度计算
cs231n的Backpropagation, Intuitions给出了生动的关于链式求导的学习示例
简单函数求导
对于简单函数而言,其导数计算方式很简单。比如
复合函数求导
对于复合函数而言,直接计算导数很复杂,但它可以拆分为多个简单函数,然后逐一进行计算
以函数
其中函数可拆分成如下形式:
对
所以函数
可以用相同的方式对权重
所以链式法则指的是将复合函数拆分为一个个简单函数,通过组合简单函数的导数得到复合函数的导数,最后组成梯度进行权值更新
雅可比矩阵
假设函数从
如果函数由
其大小为
在神经网络中每次计算的输入输出结果都是向量或矩阵,所以其偏导数均可以组成Jacobian矩阵
比如函数
其大小为
网络符号定义
规范神经网络的计算符号
关于神经元和层数
0层,隐藏层是第1层,输出层是第2层
342
关于权重矩阵和偏置值
关于神经元输入向量和输出向量
关于神经元激活函数
关于评分函数和损失函数
神经元执行步骤
神经元操作分为2步计算:
- 输入向量
- 输出向量
TestNet网络
TestNet是一个2层神经网络,结构如下:
- 输入层有
3个神经元 - 隐藏层有
4个神经元 - 输出层有
2个神经元
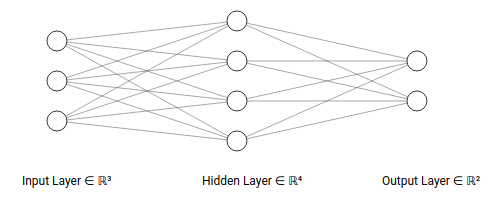
- 激活函数为
relu函数 - 评分函数为
softmax回归 - 代价函数为交叉熵损失
对输入层
对隐藏层
对输出层
评分值
损失值
前向传播
- 对于输入层神经元,其得到输入数据后直接输出到下一层,并没有进行权值操作和激活函数操作,所以严格意义上讲输入层不是真正的神经元
- 对于输出层神经元,其得到输入数据,进行加权求和后直接输出进行评分函数计算,没有进行激活函数操作
输入层到隐藏层计算
隐藏层输入向量到输出向量
隐藏层到输出层计算
评分操作
损失值
反向传播
计算输出层输入向量梯度
计算输出层权重向量梯度
计算隐藏层输出向量梯度
计算隐藏层输入向量的梯度
计算隐藏层权重向量的梯度
小结
TestNet网络的前向操作如下:
反向传播如下:
参考反向传导算法和神经网络反向传播的数学原理,设每层输入向量为残差
前向传播执行步骤
层与层之间的操作就是输出向量和权值矩阵的加权求和以及对输入向量的函数激活
输出层输出结果后,进行评分函数的计算,得到最终的计算结果(以softmax分类为例)
损失函数根据计算结果判断最终损失值(以交叉熵损失为例)
反向传播执行步骤
计算损失函数对于输出层输入向量的梯度(最终层残差)
计算中间隐藏层的残差值(
完成所有的可学习参数(权值矩阵和偏置向量)的梯度计算
更新权值矩阵和偏置向量
初始化数据的必要性
梯度与输入数据呈正相关,权值更新公式如下:
如果输入数据放大1000倍,那么梯度至少放大1000倍,这时需要极小的
未找到相关的 Issues 进行评论
请联系 @zjykzj 初始化创建