An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
摘要
Image-based sequence recognition has been a long-standing research topic in computer vision. In this paper, we investigate the problem of scene text recognition, which is among the most important and challenging tasks in image-based sequence recognition. A novel neural network architecture, which integrates feature extraction, sequence modeling and transcription into a unified framework, is proposed. Compared with previous systems for scene text recognition, the proposed architecture possesses four distinctive properties: (1) It is end-to-end trainable, in contrast to most of the existing algorithms whose components are separately trained and tuned. (2) It naturally handles sequences in arbitrary lengths, involving no character segmentation or horizontal scale normalization. (3) It is not confined to any predefined lexicon and achieves remarkable performances in both lexicon-free and lexicon-based scene text recognition tasks. (4) It generates an effective yet much smaller model, which is more practical for real-world application scenarios. The experiments on standard benchmarks, including the IIIT-5K, Street View Text and ICDAR datasets, demonstrate the superiority of the proposed algorithm over the prior arts. Moreover, the proposed algorithm performs well in the task of image-based music score recognition, which evidently verifies the generality of it.
基于图像的序列识别一直是计算机视觉领域的一个长期研究课题。本文研究了场景文本识别问题,这是基于图像的序列识别中最重要、最具挑战性的任务之一。提出了一种新的神经网络架构,该架构将特征提取、序列建模和转录集成到一个统一的框架中。与之前的场景文本识别系统相比,所提出的架构具有四个独特的特性:(1)它是端到端可训练的,而现有的大多数算法的组件是单独训练和调优的。(2) 它自然地处理任意长度的序列,不涉及字符分割或水平尺度归一化。(3) 它不局限于任何预定义的词典,在无词典和基于词典的场景文本识别任务中都取得了显著的性能。(4) 它生成了一个有效但更小的模型,对于现实世界的应用场景来说更实用。在标准基准(包括IIIT-5K、街景文本和ICDAR数据集)上的实验证明了所提出的算法优于现有技术。此外,所提出的算法在基于图像的乐谱识别任务中表现良好,这显然验证了它的通用性。
概述
DCNN(Deep Convolutional Neural Networks)在识别问题(比如分类/检测)上有很大的进展,但是它无法直接应用于基于图像的序列识别(image based sequence recognition),比如场景文本(scene text)、手写文字(handwritting)和乐谱(musical score)。这类问题有两个特性:一、基于序列的目标通常需要算法识别一系列标签,而不是单个标签;二、基于序列的目标的长度是可变的。 DCNN算法要求输入和输出是固定尺度,这天然不适用于场景文本的识别。
RNN(Recurrent Neural Networks)模型是深度神经网络家族的另外一个分支,专门用于处理序列数据,它其中的一个优势在于无论训练或者测试阶段,模型都不需要指定序列目标图像中每个元素的确切位置。另外,RNN的输入是图像的特征序列,所以需要经过前处理步骤(preprocessing step),将输入图像转换成图像特征的序列数据,可以使用图像算法(比如HOG算子)或者DCNN算法。当前基于RNN的场景文本识别算法的处理流程中,前处理步骤和RNN算法推理是独立的,也就是说,无法以端到端的方式来进行训练和优化。
本文提出了一个新的神经网络模型CRNN(Convolutional Recurrent Neural Network),它是CNN和RNN的组合,专门用于识别基于图像的序列目标。针对序列目标,CRNN具有以下优势:
- 在训练过程中,它直接使用序列目标的标签进行学习,不需要额外的信息;
- 它拥有DCNN同样的特性,没有前处理步骤,包括字符归一化/字符分割,或者文本定位等(including binarization/segmentation, component localization, etc.),直接从图像数据中学习到有判别力的特征;
- 它拥有RNN同样的特性,能够生成一系列的标签结果;
- 它不限制序列目标的长度,只需要在训练和测试阶段保证图像高度的一致性;
- 相比于之前的算法,CRNN在场景文本识别任务中实现了更好的性能;
- 相比于标准的DCNN模型,CRNN拥有更少的参数和更小的存储空间。
CRNN
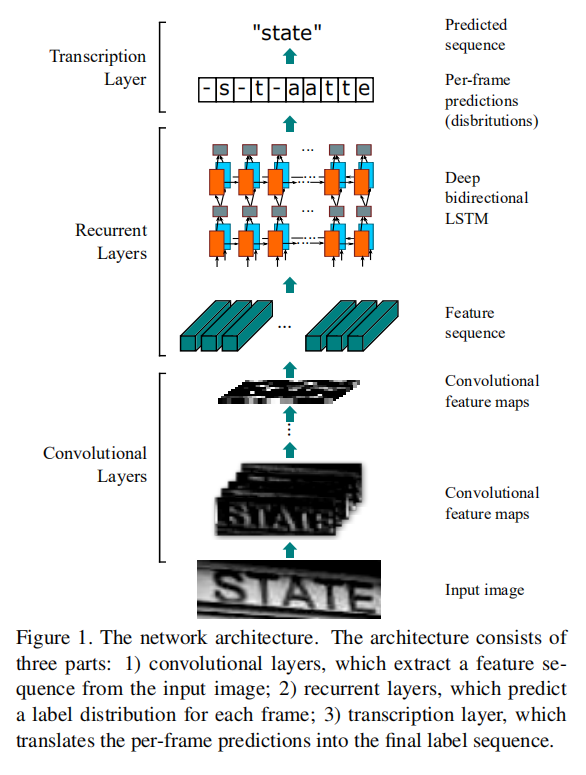
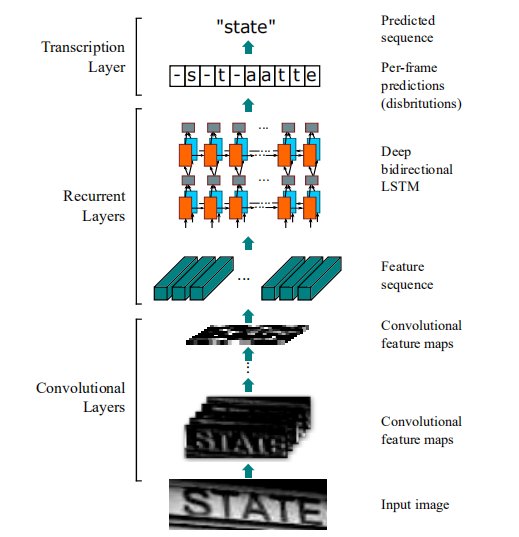
CRNN整体架构由3部分组成:卷积层(convolutional layer)、递归层(recurrent layer)和转录层(transcription layer),分别执行卷积特征提取、逐特征序列识别以及最终的标签输出。整个CRNN是一个端到端的深度神经网络模型,CNN模块和RNN模块使用同一个损失函数进行联合训练。
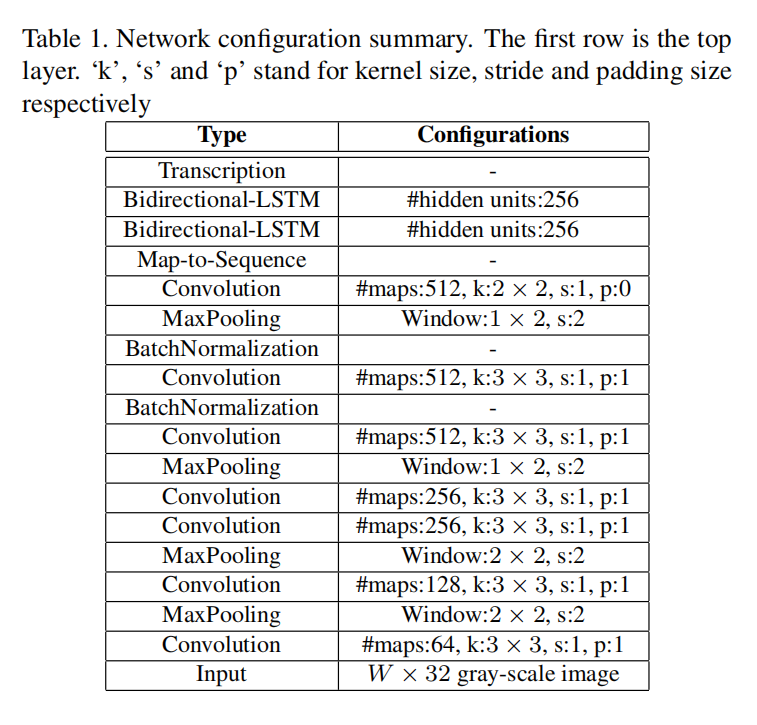
在表一具体的CRNN模型定义中,第3/4个最大池化层没有针对宽度进行缩放,这样能够得到更长的特征序列,也就能够输出更长的预测序列。
特征序列提取
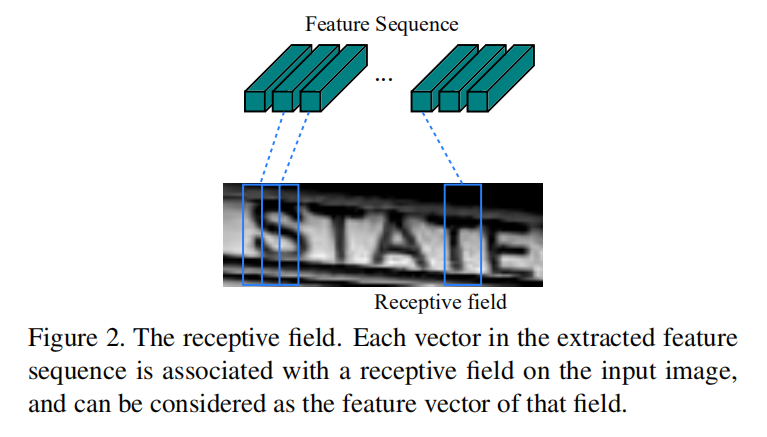
在CRNN的CNN模块中,使用卷积层和最大池化层进行构建,用于从输入图像中提取序列特征。因为卷积神经网络具有平移不变性(translation invariant)以及局部感受野(local receptive field)的特性,所以最后输出的特征序列中每一列特征向量可以看成是图像某一个局部区域的特征提取,也就是该区域的特征描述符(the image descriptor for that region)。
序列建模
得到卷积模块提取的特征序列之后,CRNN将它们输入到递归层中,论文使用了双向LSTM(bidirectional LSTM)进行构建,它的作用在于能够同时利用当前单元输入的序列特征和前后单元中间层输入的上下文序列特征,来更好的建模文本标签。
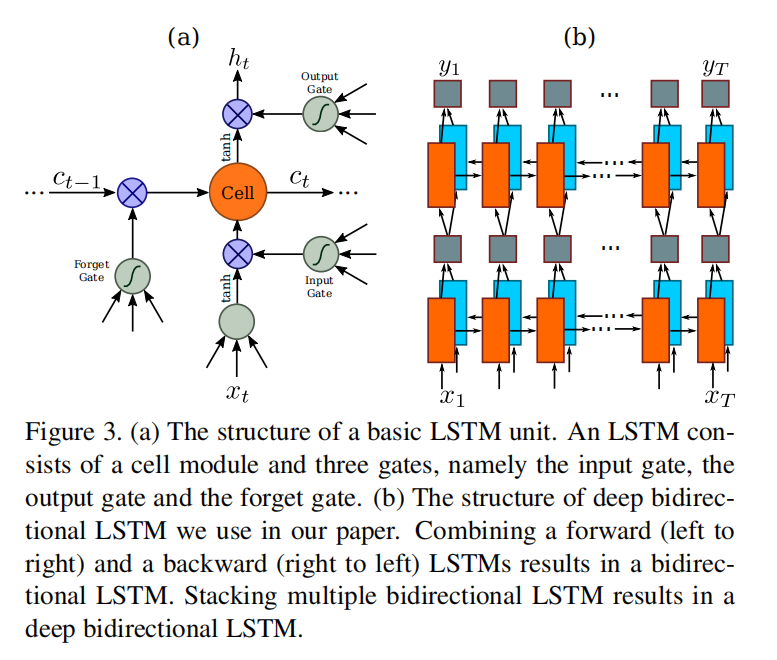
转录层
转录层的目的是将RNN层输出的逐帧预测转换成标签序列。实际上,我没有很好的理解论文针对CTC模块的具体实现过程以及数学解释。我能够想清楚的内容是:RNN模块会输出逐帧标签的概率分布,然后通过CTC模块进行解码。在CTC模块中,首先将每帧特征预测按照最大概率计算得到标签,最终组成整组特征的预测标签序列;然后使用序列预测函数\(B\),移除相邻重复的标签和空白标签,比如预测标签序列是--hh-e-l-ll-oo--,其中-表示空白标签,hh表示相邻重复标签,经过\(B\)的计算后得到最终的标签值hello。
相关阅读:
- Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks
- Sequence Modeling With CTC
实验
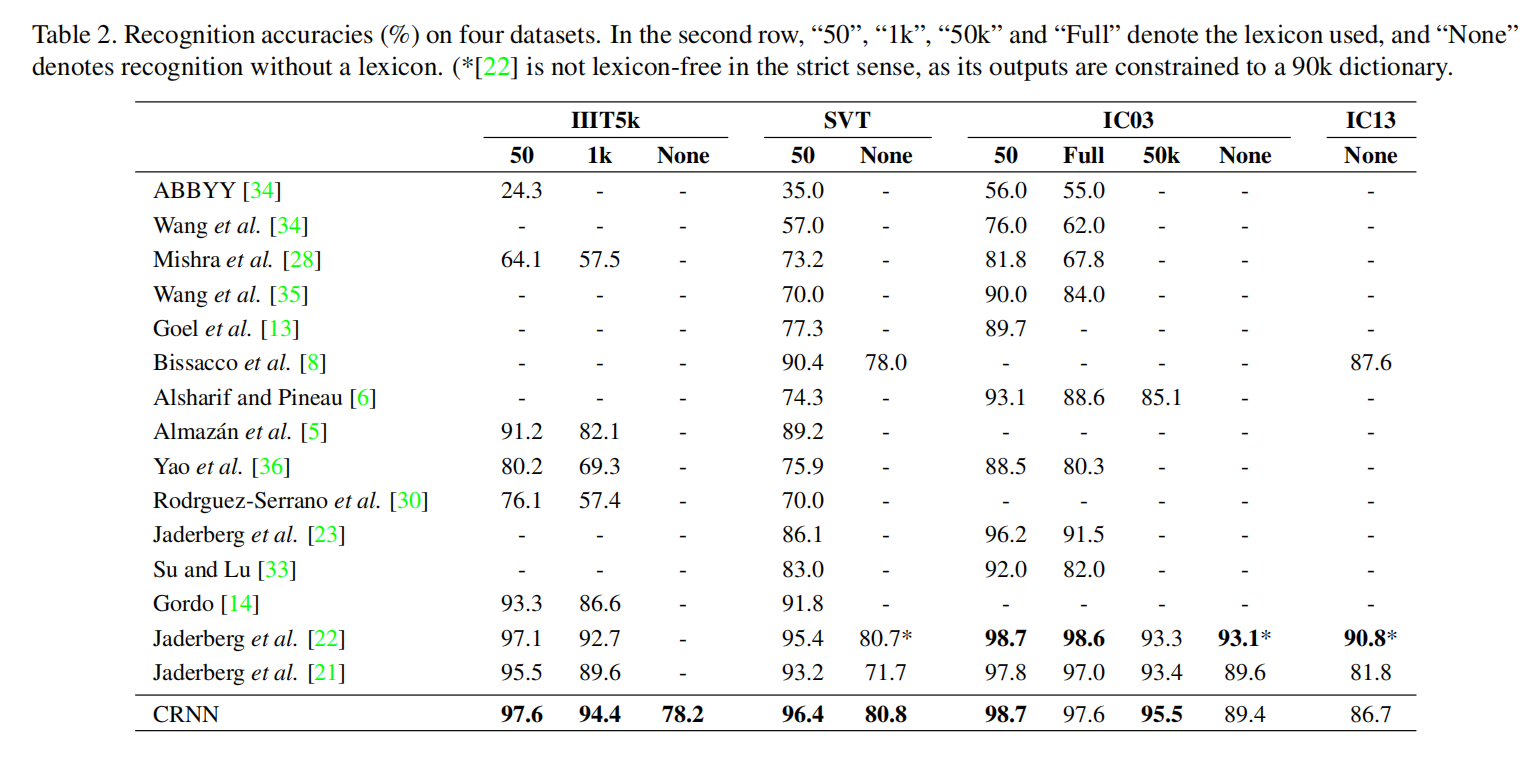
对于训练数据,论文使用了the synthetic dataset (Synth),它包含800w张训练图片和对应的真值文字,是通过合成文本引擎生成的。在训练完成后,CRNN评估了其他4个场景文本数据集,不需要额外在这些数据集的训练数据上进行微调训练。测试数据集包括IC03(ICDAR 2003)、IC13(ICDAR 2013)、IIIT55k(IIIT 5k-word)和SVT(Street View Text)。
小结
CRNN很好的结合了CNN模块和RNN模块,提出了一个适用于基于图像的序列识别任务的端到端的深度神经网络算法架构。结合近些年提出的更轻量级和更强大的CNN模型以及RNN模型,可以改造CRNN得到参数量更少,推理时间更短,同时性能更强大的算法,比如PaddleOCR中针对文本识别算法的迭代优化。
最后,我尝试着将CRNN应用于车牌识别任务(zjykzj/crnn-ctc)。
| Model | ARCH | Input Shape | GFLOPs | Model Size (MB) | ChineseLicensePlate Accuracy (%) | Training Data | Testing Data |
|---|---|---|---|---|---|---|---|
| CRNN | CONV+GRU | (3, 48, 168) | 4.0 | 58 | 82.147 | 269,621 | 149,002 |
| CRNN_Tiny | CONV+GRU | (3, 48, 168) | 0.3 | 4.0 | 76.590 | 269,621 | 149,002 |