Towards End-to-End License Plate Detection and Recognition: A Large Dataset and Baseline
CCPD是一个中文车牌数据集,图像数目超过25w张,同时提供了车牌矩形框以及车牌角点标注。
论文:Towards End-to-End License Plate Detection and Recognition: A Large Dataset and Baseline
GITHUB: CCPD (Chinese City Parking Dataset, ECCV)
摘要
Most current license plate (LP) detection and recognition approaches are evaluated on a small and usually unrepresentative dataset since there are no publicly available large diverse datasets. In this paper, we introduce CCPD, a large and comprehensive LP dataset. All images are taken manually by workers of a roadside parking management company and are annotated carefully. To our best knowledge, CCPD is the largest publicly available LP dataset to date with over 250k unique car images, and the only one provides vertices location annotations. With CCPD, we present a novel network model which can predict the bounding box and recognize the corresponding LP number simultaneously with high speed and accuracy. Through comparative experiments, we demonstrate our model outperforms current object detection and recognition approaches in both accuracy and speed. In real-world applications, our model recognizes LP numbers directly from relatively high-resolution images at over 61 fps and 98.5% accuracy.
当前大多数的车牌(LP)检测和识别方法都是在一个小型且通常不具代表性的数据集上评估的,因为没有公开的大型多样化的数据集。本文介绍了CCPD,一个庞大且全面的LP数据集。所有图像均由路边停车管理公司的工作人员手动拍摄并且详细注释。据我们所知,CCPD是迄今为止最大的公开LP数据集,拥有超过25万张汽车图像,并且是唯一一个提供车牌角点位置标注的数据集。在CCPD的基础上,我们提出了一个新的网络模型,该模型可以快速准确地预测边界框并同时识别相应的LP号码。通过对比实验,证明了我们的模型在准确性和速度方面都优于当前的目标检测和识别方法。在实际应用过程中,直接从相对高分辨率的图像中识别LP号码,我们的模型能够实现超过61fps和98.5%的准确率。
概要
相比于之前开源的车牌数据集,论文提供的CCPD(Chinese City Parking Dataset)不论在数量(quantity)还是多样性(diversity)上都提供了非常大的空间。
每张图像都详细标注了以下内容:
- 车牌号码(LP number);
- 车牌边界框(LP bounding box);
- 4个角点坐标( Four vertices locations);
- 水平倾斜度和垂直倾斜度(Horizontal tilt degree and vertical tilt degree);
- 其他信息:包括车牌面积、亮度和模糊程度(Other relevant information like the LP area, the degree of brightness, the degree of vagueness and so on)。

论文除了提供有效的车牌数据集以外,还设计了一个端到端的检测+识别网络Roadside Parking net (RPnet)。
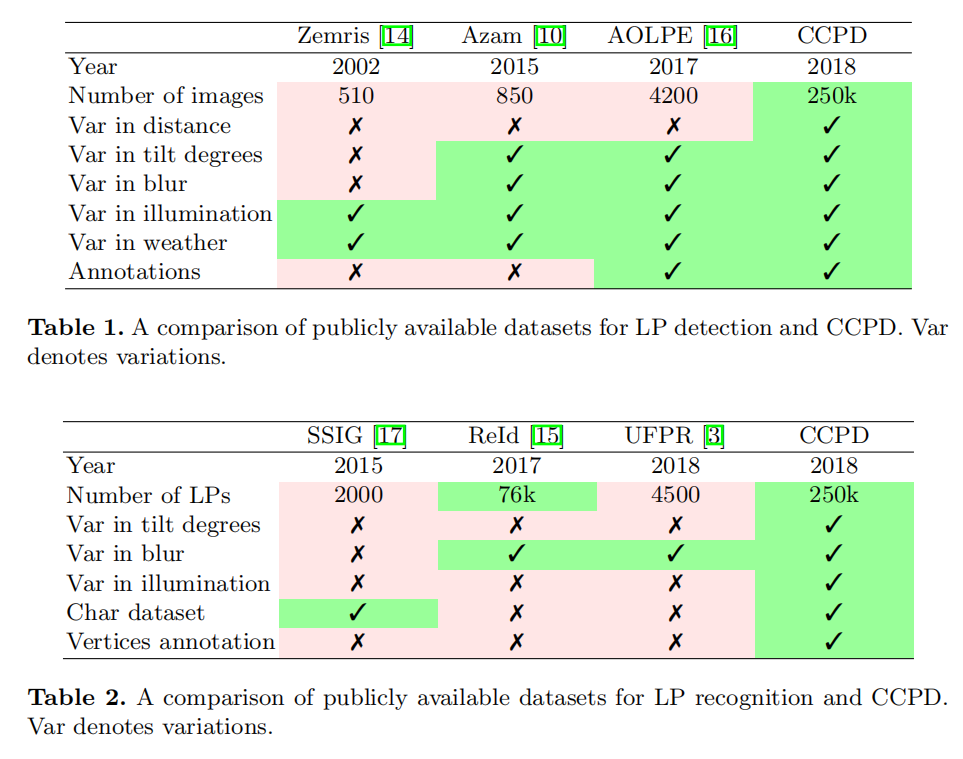
CCPD
每张图片宽高是720x1160,每张图片的文件名包含所有的标注信息,以025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg为例,使用-作为分隔符,一共7个字段,分别代表(参考这个数据集的readme真的是烂的一批 #74):
- 面积(
025):车牌面积与整个图片区域的面积比; - 倾斜度(
95-113):水平倾斜程度和垂直倾斜度; - 边界框坐标(
154&383_386&473-):左上和右下顶点的坐标; - 四个顶点位置(
386&473_177&454_154&383_363&402):整个图像中车牌的四个顶点的精确(x,y)坐标。这些坐标从右下角顶点开始; - 车牌号(
0_0_22_27_27_33_16):CCPD中的每个图像只有一个车牌。每个车牌号码由一个汉字,一个字母和五个字母或数字组成。有效的中文车牌由七个字符组成:省(1个字符),字母(1个字符),字母+数字(5个字符)。“ 0_0_22_27_27_33_16”是每个字符的索引。这三个数组定义如下。每个数组的最后一个字符是字母O,而不是数字0。我们将O用作“无字符”的符号,因为中文车牌字符中没有O。
1 | provinces = ["皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新", "警", "学", "O"] |
- 亮度(
37):车牌区域的亮度; - 模糊程度(
15):车牌区域的模糊程度。
所以上面展示的文件名表示这幅图片的信息有:
- 车牌面积占比整幅图片的
25%; - 车牌的水平倾斜度是
95度,垂直倾斜度是113度; - 车牌的左上角坐标是
(154, 383),右下角坐标是(386, 473); - 车牌区域4个顶点的坐标分别为
(386, 473)、(177, 454)、(154, 383)、(363, 402); - 车牌号码是
皖AY339S; - 车牌区域的亮度值是
37; - 车牌区域的模糊度是
15。
除了正常光照和正常角度拍摄的车牌图片外,CCPD还设计了不同困难环境下的车牌子数据集,比如CCPD-Rotate(水平倾斜角度在20度-50度,垂直倾斜角度在-10度到10度)、CCPD-Weather(在下雨天、下雪天或者雾天拍摄的图片)等等。
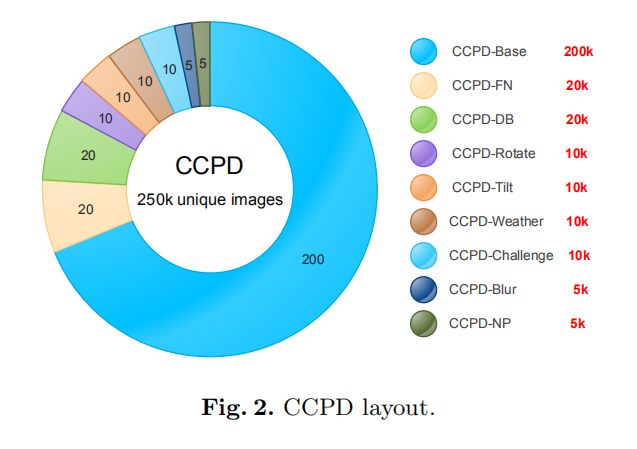
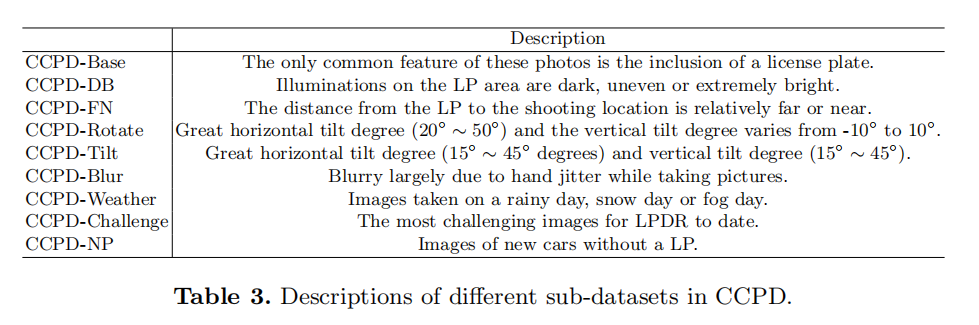
RPnet
RPnet是论文设计的端到端的卷积神经网络模型。分为两个模块,一个是检测模块(the detection module),负责车牌区域的定位;另一个是识别模块(the recognition module),负责车牌号码的识别。两个模块共用同一个卷积特征提取Backbone,具体架构如下图所示:
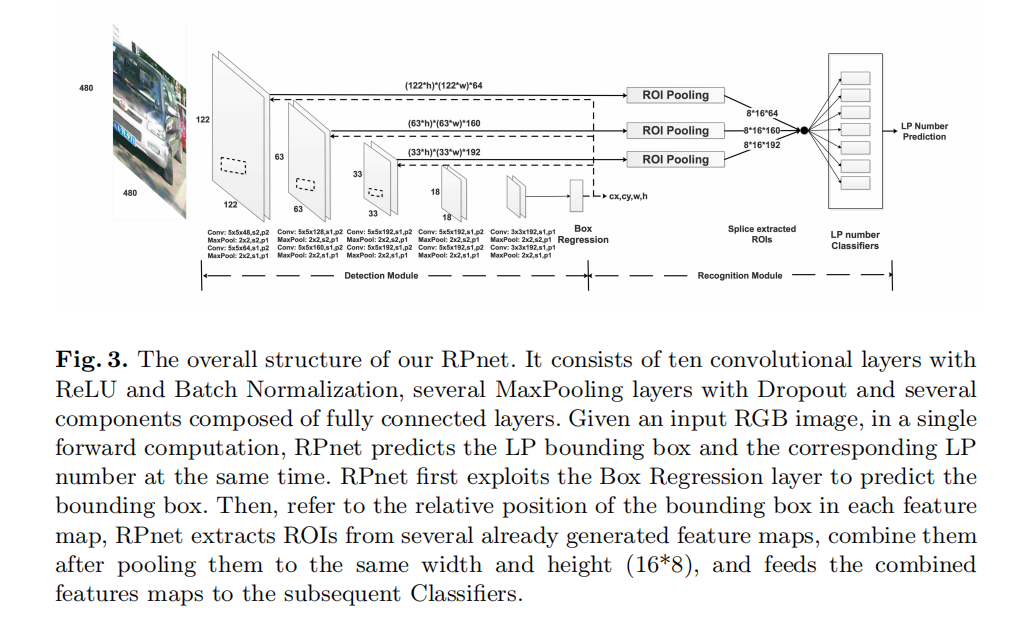
对于车牌定位,RPnet把它看成是回归问题,在Backbone后面直接连接全连接层,预测输出车牌左上角和右下角的坐标;对于车牌识别,RPnet把它看成是分类问题,通过ROI池化层来提取中间层特征,进行浅层和深层特征的融合,最后设置7个分类器分别来分类车牌7位号码。从论文公布的结果来看有很好的效果:
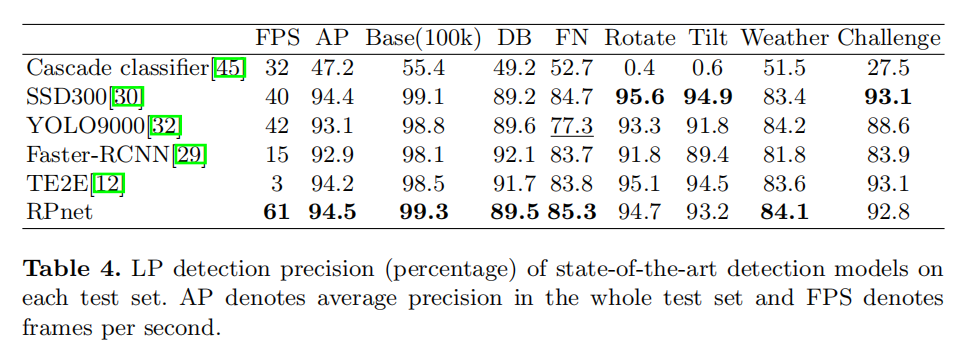
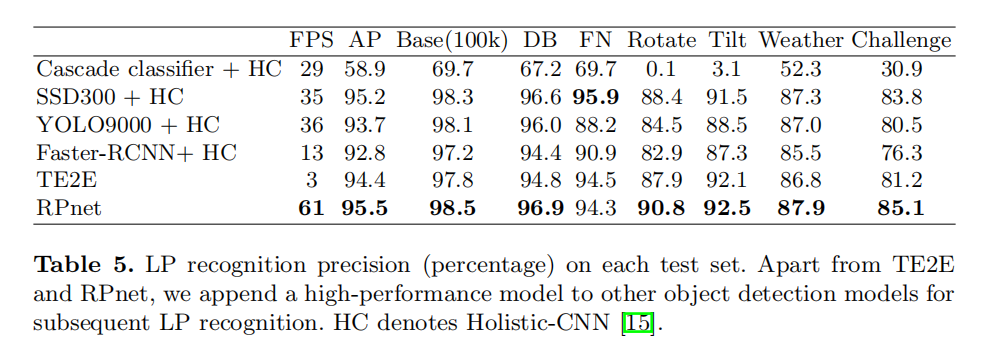
小结
本论文提供了一个非常完备的中文车牌数据集,能够更好的促进车牌检测和车牌识别领域的发展。其次,论文设计的RPnet也表现出强大的性能,对此我尝试着进行复现:zjykzj/LPDet v0.3.0,确实在测试集上达到了很高的精度,不过在实验过程中也发现存在一些改进空间:
- RPnet仅适用于单个车牌场景,无法准确定位和识别多个车牌的图片;
- 因为大量使用了全连接层,导致RPnet的模型非常大(超过200MB)。
最后,我还尝试了使用YOLOv5-Seg+CRNN-CTC的组合进行车牌图片的定位和识别,不管是检测精度还是识别精度,以及整体占用资源都更适用:zjykzj/LPDet。
| Model Segmentation | Input Shape | GFLOPs | Model Size (MB) | Speed RTX 3090 b1 (ms) | ChineseLicensePlate mAP50 (%) | Training Data | Testing Data |
|---|---|---|---|---|---|---|---|
| YOLOv5n-Seg | (3, 640, 640) | 6.7 | 3.9 | 9.0 | 99.2 | 200,579 | 105,585 |
| Model Recognition | Input Shape | GFLOPs | Model Size (MB) | Speed RTX 3090 b1 (ms) | ChineseLicensePlate Accuracy (%) | Training Data | Testing Data |
| CRNN_Tiny | (3, 48, 168) | 0.3 | 4.0 | 7.5 | 76.226 | 269,621 | 149,002 |