Focal Loss for Dense Object Detection
原文地址:Focal Loss for Dense Object Detection
摘要
The highest accuracy object detectors to date are based on a two-stage approach popularized by R-CNN, where a classifier is applied to a sparse set of candidate object locations. In contrast, one-stage detectors that are applied over a regular, dense sampling of possible object locations have the potential to be faster and simpler, but have trailed the accuracy of two-stage detectors thus far. In this paper, we investigate why this is the case. We discover that the extreme foreground-background class imbalance encountered during training of dense detectors is the central cause. We propose to address this class imbalance by reshaping the standard cross entropy loss such that it down-weights the loss assigned to well-classified examples. Our novel Focal Loss focuses training on a sparse set of hard examples and prevents the vast number of easy negatives from overwhelming the detector during training. To evaluate the effectiveness of our loss, we design and train a simple dense detector we call RetinaNet. Our results show that when trained with the focal loss, RetinaNet is able to match the speed of previous one-stage detectors while surpassing the accuracy of all existing state-of-the-art two-stage detectors. Code is at: this https URL.
当前最高精度的目标检测器是基于R-CNN的二阶段方法,其分类器仅需要处理候选目标位置的稀疏集合。相比之下,应用于可能目标位置的常规密集采样的单阶段检测器具有更快和更简单的潜力,但迄今为止其精度一直落后于二阶段检测器。在本文中,我们将探讨为什么会出现这种情况。我们发现在密集检测器的训练过程中遇到的极度的前-后景类别的不平衡是主要原因。通过调整标准交叉熵损失,降低正确分类样本的损失权重来解决这种类别不平衡。我们提出的Focal Loss将训练聚焦在错误分类的示例上,避免了大量极易分类的背景样本损害检测器.。为了评估Focal Loss的有效性,我们设计并训练了一个简单的密集检测器,称之为RetinaNet。结果表明,当使用Focal Loss进行训练时,RetinaNet能够匹配之前单阶段检测器的速度,同时超过所有现有的最先进的二阶段检测器的精度。代码地址:https://github.com/facebookresearch/Detectron
类不平衡现象
在二阶段目标检测器中,首先执行候选建议的提取,然后执行候选建议的分类以及边界框检测。在第一个阶段中,候选目标位置的数量将被迅速缩小到一个很小的数量(比如1-2k),能够过滤掉大多数的背景样本,同时通过采样策略来固定输出的正负样本数(比如1:3),保证了第二阶段的训练能够避免类别不平衡问题
而对于一阶段目标检测器而言,通过密集采样候选目标,需要处理非常大数量的候选建议,其中包含了大量的很容易分类的背景样本。这种类别不平衡现象会导致两个问题:
- 训练效率底下。因为大多数的候选建议都是
easy negatives(很容易分类的背景样本),并没有贡献有用的学习信号 - easy negatives会损害训练过程,导致模型退化(太容易分类了)
通常解决类别不平衡的方式是通过bootstrapping或者hard example mining
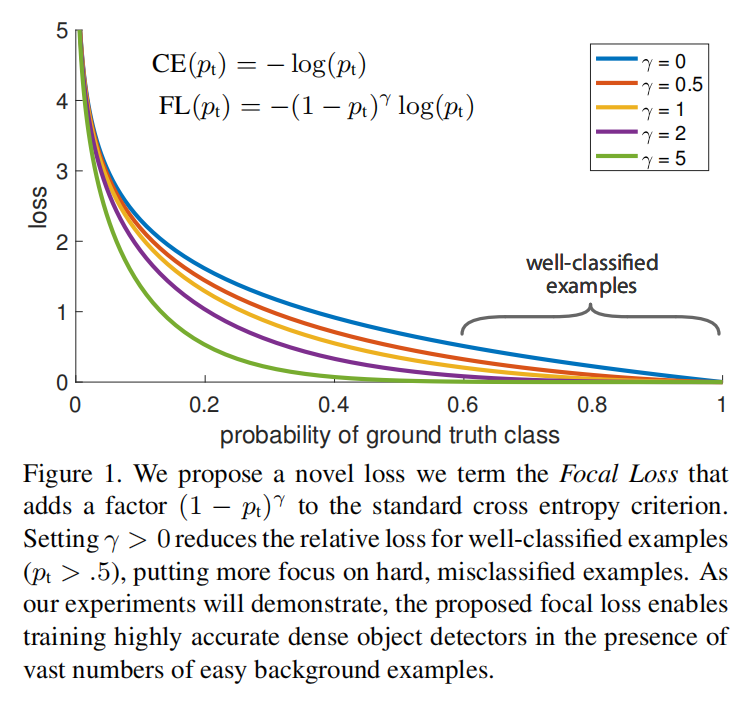
Focal Loss
之前损失函数方面的改进大都专注于如何降低hard examples(不容易正确分类)的权重。而论文提出的Focal Loss则专注于降低easy examples的权重,即使很容易分类的样本数目很大,但是它们对于整体损失的贡献很小,使得检测器专注于一小部分hard examples的训练,从而解决类别不平衡的问题
Gitalk 加载中 ...