Temporal Segment Network
原文地址:
- Temporal Segment Networks: Towards Good Practices for Deep Action Recognition:发布于ECCV 2016
- Temporal Segment Networks for Action Recognition in Videos:发布于17年期刊
官方实现:yjxiong/tsn-pytorch
复现地址:ZJCV/TSN
摘要
Deep convolutional networks have achieved great success for image recognition. However, for action recognition in videos, their advantage over traditional methods is not so evident. We present a general and flexible video-level framework for learning action models in videos. This method, called temporal segment network (TSN), aims to model long-range temporal structures with a new segment-based sampling and aggregation module. This unique design enables our TSN to efficiently learn action models by using the whole action videos. The learned models could be easily adapted for action recognition in both trimmed and untrimmed videos with simple average pooling and multi-scale temporal window integration, respectively. We also study a series of good practices for the instantiation of temporal segment network framework given limited training samples. Our approach obtains the state-the-of-art performance on four challenging action recognition benchmarks: HMDB51 (71.0%), UCF101 (94.9%), THUMOS14 (80.1%), and ActivityNet v1.2 (89.6%). Using the proposed RGB difference for motion models, our method can still achieve competitive accuracy on UCF101 (91.0%) while running at 340 FPS. Furthermore, based on the temporal segment networks, we won the video classification track at the ActivityNet challenge 2016 among 24 teams, which demonstrates the effectiveness of temporal segment network and the proposed good practices.
深度卷积网络在图像识别领域已经取得了巨大的成功。不过,在视频动作识别领域,它们相对于传统方法的优势还没有非常明显。我们提出了一个视频动作识别的通用框架,称之为时间分段网络(TSN),通过一个新的基于分段的采样和融合模型来建模长时间时态结构。这个设计允许TSN能够有效的学习到整个视频的动作信息。通过简单的平均池化和多尺度时间窗口集成,所学习的模型可以容易地分别适用于修剪和未修剪视频中的动作识别。在给定有限的训练样本的情况下,我们还研究了时间分段网络框架实例化的一系列良好实践。在四个动作识别挑战基准上,我们的方法取得了最好的性能:HMDB51 (71.0%), UCF101 (94.9%), THUMOS14 (80.1%), and ActivityNet v1.2 (89.6%)。使用本文提出的RGB差分进行动作建模,我们的方法能够在运行340FPS的情况下仍然可以获得一个很好的准确度(UCF101 (91.0%) )。此外,基于时间分段网络,我们在2016年ActivityNet挑战赛中赢得了视频分类冠军,这证明了时间分段网络的有效性和所提出的良好实践。
引言
对于视频动作识别而言,有两个关键属性:外观(appearance)和时序动态(temporal dymanic)
针对视频识别领域中的卷积网络实现,存在3个问题:
- 一部分深度模型(采用连续帧,帧长度不足)专注于外观(appearance)和短时动作(short-term motion),并没有利用长时间时态结构(long-range temporal structure);
- 一部分深度模型通过密集采样(有可能指定固定间隔)方式采集长时间的帧数据,占据极大的内存空间以及计算耗时;
本文要解决的3个问题:
- 如何有效地学习捕捉长时间时态结构的视频表示;
- 如何将这些学习过的深度模型用于更真实的未剪辑视频;
- 如何在有限的训练样本下有效地学习深度模型,并将其应用于大规模数据。
针对第一个问题,论文作者观察到以下现象:
consecutive frames are highly redundant, where a sparse and global temporal sampling strategy would be more favorable and efficient in this case.
连续帧是高度冗余的,在这种情况下,稀疏和全局时间采样策略会更有利和有效。
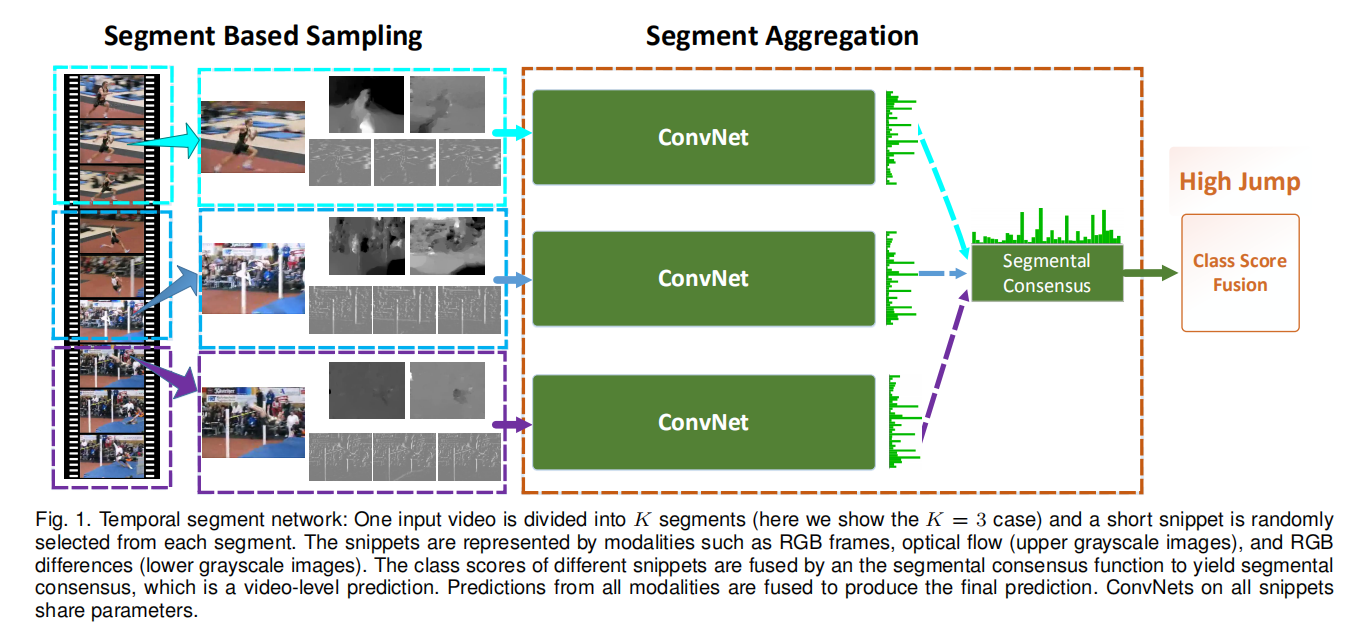
为此,提出了一个模块化视频级架构:时间分段网络(temporal segment network)。将视频等间隔分为固定数量片段,然后从每个片段中随机采集一帧组成训练数据;输入到2D网络计算每个图像的分类成绩;最后通过一个分段一致性函数(segment consensus function)将结果聚合在一起得到最后的分类结果。
5个聚合函数 求和采样图像的分类成绩
平均池化/最大池化/加权平均/top-k池化/自适应注意力加权
设计一个分层聚合策略作用于未剪辑视频:
四种模态:
- RGB图像;
- 堆叠的RGB差分;
- 堆叠的光流场;
- 堆叠扭曲的光流场。
如何高效、有效的学习和应用动作识别模型,论文从4个方向进行了阐述:
- 训练和推理问题(共3个方面:模型设计、应用以及训练);
- 相应的解决方案
论文实现分3个方面:
- 提出了一个端到端的框架,称为时间分段网络(TSN),用于学习捕获长时间时态信息的视频表示;
- 设计了一个分层聚合方案,将动作识别模型应用于未剪辑的视频;
- 研究了一系列应用于深度动作识别模型的良好实践。
Tenporal Segment Network
- 基于分段采样的动机
- 时间分段网络框架架构
- 针对聚集函数进行分析
- 最后研究了时间分段网络框架实例化的几个实际问题
采样策略
TSN的视频采样策略遵循两个原则:
- 稀疏采样:单次训练所需的图像个数固定,不会因为视频长度发生变化,这样保证了计算成本的一致性
- 全局采样:确保采样片段在时间维度能够均匀分布,不管视频长短,采样片段通常会大致覆盖整个视频的视觉内容
其实现如下图所示:
灵感
固定采样帧数:
- 固定计算成本;
- 保证采样成本
架构
聚合函数
tricks
关于输入
关于训练
实际使用
有剪辑视频:整段视频描述了标签内容;
未剪辑视频:仅有一部分视频片段描述了标签内容