Two-Stream Convolutional Networks for Action Recognition in Videos
原文地址:Two-Stream Convolutional Networks for Action Recognition in Videos
摘要
We investigate architectures of discriminatively trained deep Convolutional Networks (ConvNets) for action recognition in video. The challenge is to capture the complementary information on appearance from still frames and motion between frames. We also aim to generalise the best performing hand-crafted features within a data-driven learning framework. Our contribution is three-fold. First, we propose a two-stream ConvNet architecture which incorporates spatial and temporal networks. Second, we demonstrate that a ConvNet trained on multi-frame dense optical flow is able to achieve very good performance in spite of limited training data. Finally, we show that multitask learning, applied to two different action classification datasets, can be used to increase the amount of training data and improve the performance on both. Our architecture is trained and evaluated on the standard video actions benchmarks of UCF-101 and HMDB-51, where it is competitive with the state of the art. It also exceeds by a large margin previous attempts to use deep nets for video classification.
我们实现了一个用于视频动作识别的区别当前已实现的深度卷积网络的架构。视频动作识别的挑战在于从静止帧中提取图像信息以及从在帧之间提取运动信息。本文致力于在数据驱动的学习框架中得到一个泛化性能最好的手工设计网络。 有3方面的贡献.首先,我们提出了一个包含空间网络和时间网络的双流卷积网络架构;其次,我们证明了在有限数据情况下,通过训练多帧密集光流能够得到一个很好性能的卷积网络;最后,我们证明了通过多任务学习,将两个动作分类数据集同时进行训练,不仅能够扩充数据量,同时能够提高模型性能。 论文实现的模型在UCF-101和HMDB-51上得到了非常好的性能,它也大大超过了以前使用深度网络进行视频分类的实现结果。
章节介绍
- 第一章:引言。介绍了视频动作识别相比于静态图像分类的难度以及之前应用于视频动作分类的传统图像学习(光流、轨迹)和深度网络方法
- 第二章:双流架构。介绍了双流网络架构以及其中的空间网络
- 第三章:介绍了时间网络
- 第四章:介绍了多任务学习框架,即使用多个不同类别的数据集对一个网络进行训练
- 第五章:介绍了具体的实现细节
- 第六章:介绍了双流网络的评估
启发
双流网络的提出受到双流假说的影响:人类视觉皮层包含两条通路:腹侧流(执行目标识别)和背侧流(执行运动识别)
双流模型
视频可以分解成空间和时间两个组件。在空间部分(静态图像)可以观察到场景以及目标;在时间部分(逐帧信息)可以观察到动作信息。如下图所示

双流模型包含了两个网络,一个用于静态图的计算,一个用于光流图的计算,最后对两个网络的计算结果进行融合
时间网络
对于空间网络,其输入就是RGB图像,而对于时间网络,需要输入包含运动信息的数据,由几个连续帧之间的光流位移场叠加而成。如下图所示:

论文提出了几种基于光流的输入实现:
- 光流堆叠(
optical flow stacking):密集光流可以看成是连续帧\(t\)和\(t+1\)之间的一组位置矢量场\(d_{t}\),其中\(d_{t}(u+v)\)表示帧\(t\)的点\((u,v)\)上的位移向量,由两部分组成:\(d_{t}^{x}\)和\(d_{t}^{y}\),可以看成是图像的两个通道。在论文中,堆叠了\(L\)对连续帧的光流通道\(d_{t}^{x,y}\)得到\(2L\)个输入通道,所以其输入卷\(I_{\tau }\in \Re^{w\times h\times 2L}\)中任意一帧\(\tau\)的计算公式如下:
\[ I_{\tau}(u, v, 2k-1) = d_{\tau + k -1}^{x}(u,v)\\ I_{\tau}(u, v, 2k) = d_{\tau+k-1}^{y}(u,v), u=[1;w], v=[1;h], k=[1;L] \]
对于任意点\((u, v)\),通道\(I_{\tau}(u, v, c), c=[1;2L]\)编码了\(L\)帧序列中该点的动作信息
- 轨迹堆叠(
Trajectory stacking)。使用轨迹向量代替光流 - 双向光流(
Bi-directional optical flow)。构造前向和反向的光流场
对于时间网络,其输入数据大小为\(224\times 224\times 2L\),后续隐藏层的配置和空间网络一样
多任务学习
论文使用了UCF101和HMDB51数据集进行测试,这两个数据集的视频个数不多,所以本文提出结合两个数据集进行测试的方法。简单来说,就是为每个数据集设置一个分类器,其余网络层参数保持不变
评估
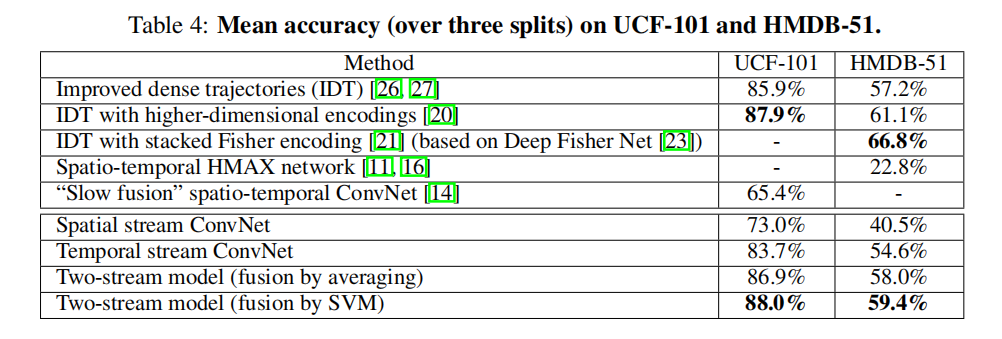
首先比较独立的时间网络和空间网络的性能,如下图所示
从图中可知,时间网络和空间网络都能够实现比较好的分类性能。其实对于空间网络而言,其输入为连续多帧,天然的包含了运动属性;而对于时间网络而言,每帧光流场图像也包含了目标的静态信息
接下来评估了多任务学习的作用,如下图所示

从图中可知,多任务学习的效果比简单的预训练模型更好
然后介绍了不同融合方法对于双流网络的影响,如下图所示

论文比较了Average和SVM的融合方式。相对而言,SVM的实现结果更好,不过差别不是很大
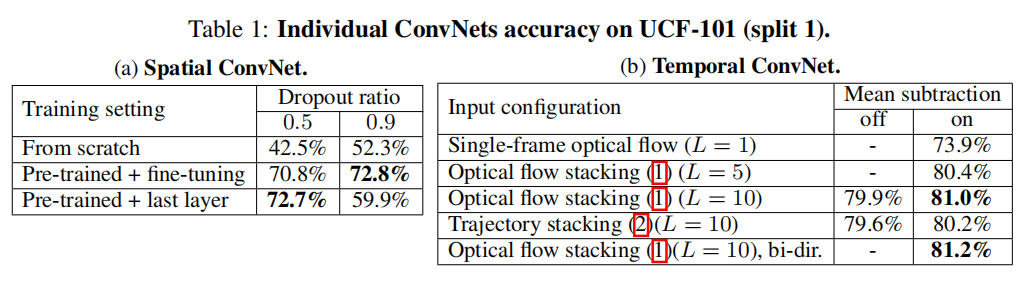
最后介绍了双流网络的训练精度,如下图所示