1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
|
"""
梯度下降法计算线性回归问题
"""
import matplotlib.pyplot as plt
import numpy as np
def load_ex1_multi_data():
"""
加载多变量数据
"""
path = '../data/coursera2.txt'
datas = []
with open(path, 'r') as f:
lines = f.readlines()
for line in lines:
datas.append(line.strip().split(','))
data_arr = np.array(datas)
data_arr = data_arr.astype(np.float)
X = data_arr[:, :2]
Y = data_arr[:, 2]
return X, Y
def load_machine_data():
"""
加载计算机硬件数据
"""
data = np.loadtxt('../data/machine.data', delimiter=',', dtype=np.str)
x = data[:, 2:8].astype(np.float)
y = data[:, 8].astype(np.float)
return x, y
def draw_loss(loss_list):
"""
绘制损失函数值
"""
fig = plt.figure()
plt.plot(loss_list)
plt.show()
def init_weight(size):
"""
初始化权重,使用均值为0,方差为1的标准正态分布
"""
return np.random.normal(loc=0.0, scale=1.0, size=size)
def compute_loss(w, x, y):
"""
计算损失值
"""
n = y.shape[0]
return (x.dot(w) - y).T.dot(x.dot(w) - y) / n
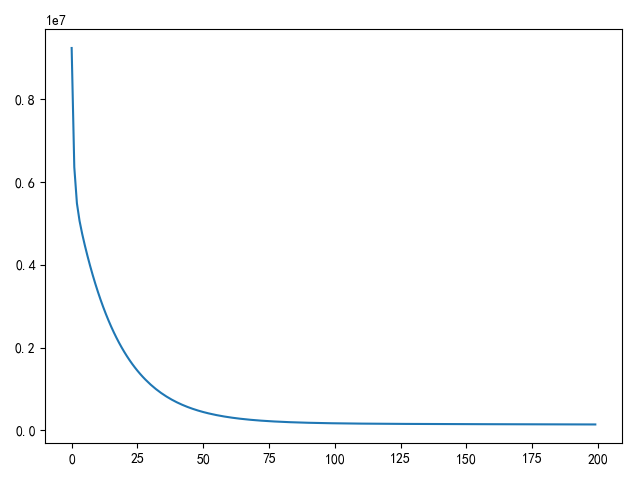
def using_batch_gradient_descent():
"""
批量梯度下降
"""
x, y = load_machine_data()
extend_x = np.insert(x, 0, values=np.ones(x.shape[0]), axis=1)
w = init_weight(extend_x.shape[1])
n = y.shape[0]
epoches = 50
alpha = 1e-9
loss_list = []
for i in range(epoches):
temp = w - alpha * extend_x.T.dot(extend_x.dot(w) - y) / n
w = temp
loss_list.append(compute_loss(w, extend_x, y))
draw_loss(loss_list)
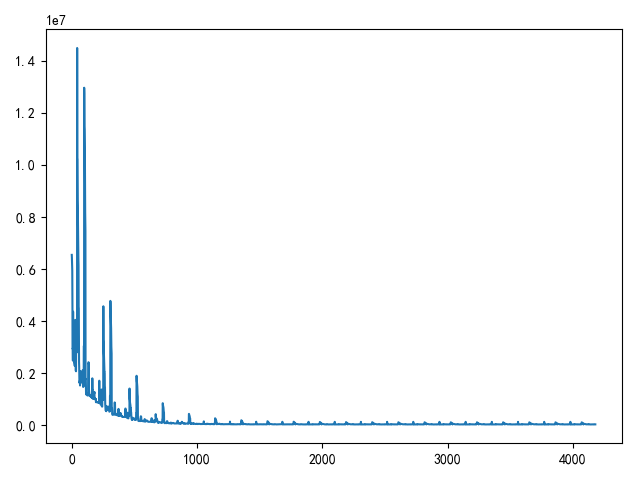
def using_stochastic_gradient_descent():
"""
随机梯度下降
"""
x, y = load_machine_data()
extend_x = np.insert(x, 0, values=np.ones(x.shape[0]), axis=1)
w = init_weight(extend_x.shape[1])
print(w.shape)
np.random.shuffle(extend_x)
print(extend_x.shape)
print(y.shape)
n = y.shape[0]
epoches = 20
alpha = 1e-9
loss_list = []
for i in range(epoches):
for j in range(n):
temp = w - alpha * (extend_x[j].dot(w) - y[j]) * extend_x[j].T / 2
w = temp
loss_list.append(compute_loss(w, extend_x, y))
draw_loss(loss_list)
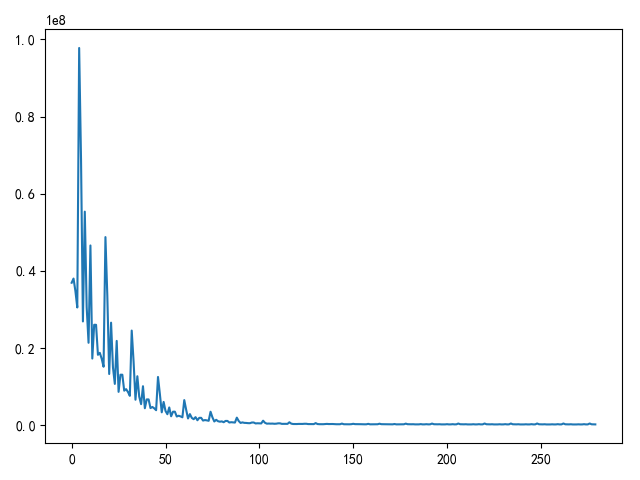
def using_small_batch_gradient_descent():
"""
小批量梯度下降
"""
x, y = load_machine_data()
extend_x = np.insert(x, 0, values=np.ones(x.shape[0]), axis=1)
w = init_weight(extend_x.shape[1])
print(w.shape)
np.random.shuffle(extend_x)
print(extend_x.shape)
print(y.shape)
batch_size = 16
n = y.shape[0]
epoches = 20
alpha = 5e-9
loss_list = []
for i in range(epoches):
for j in list(range(0, n, batch_size)):
temp = w - alpha * extend_x[j:j + batch_size].T.dot(
extend_x[j:j + batch_size].dot(w) - y[j:j + batch_size]) / batch_size
w = temp
loss_list.append(compute_loss(w, extend_x, y))
draw_loss(loss_list)
if __name__ == '__main__':
using_stochastic_gradient_descent()
|
未找到相关的 Issues 进行评论
请联系 @zjykzj 初始化创建